- Home
- Hochschule
-
Studium
- Studienangebote
-
Beratung
- Studienorientierung
- Zentrale Studienberatung
- Studienfachberatung
- Psychosoziale Beratung
- Studienfinanzierungsberatung und Stipendien
- Schreibberatung
- Studieren mit beruflicher Qualifikation
- Studieren mit ausländischen Zeugnissen
- Studieren mit Handicap
- Studieren mit Familie
- Informationen für Schulen
- Auslandsaufenthalt
-
Bewerbung
- Auswahlgrenzen und Vergabeverfahren (NC)
- Bewerbungsportal
- Bewerbung Schritt für Schritt: Von der Bewerbung bis zur Einschreibung
- Bewerbung für ein höheres Fachsemester
- Bewerbung mit beruflicher Qualifikation
- Gasthörerschaft und Zweithörerschaft
- Kontakt Studierendenservice
- Losverfahren
- Promotion
- Sonderanträge
- Studiengang wählen
- Wer kann an der HSBI studieren?
- Studienstart
-
Studium organisieren
- Studierendenservice
- Abschlussunterlagen
- Anerkennung von Leistungen
- Anträge einreichen
- Beurlaubung
- CampusCard
- Einreichung schriftliche Arbeiten
- Erstattung
- Exmatrikulation
- IT-Services
- Online-Serviceportale (LSF/CAT)
- Prüfungsangelegenheiten: Ordnungen, Modulhandbücher
- Rücktritt von einer Modulprüfung
- Rückmeldung
- Semesterbeitrag
- Semesterticket (Studi-Deutschlandticket)
- Semester-, Vorlesungs- und Prüfungszeiten
- Studienbezogene Auslandserfahrung
- Studiengebühren
- Vorlesungsverzeichnis
- Rund ums Studium
- Fachbereiche
- Forschung
- Transfer
- Weiterbildung
- Internationales
- Karriere an der HSBI
- Hochschule
- Studium
- Studium
- Studienangebote
-
Beratung
- Studienorientierung
- Zentrale Studienberatung
- Studienfachberatung
- Psychosoziale Beratung
- Studienfinanzierungsberatung und Stipendien
- Schreibberatung
- Studieren mit beruflicher Qualifikation
- Studieren mit ausländischen Zeugnissen
- Studieren mit Handicap
- Studieren mit Familie
- Informationen für Schulen
- Auslandsaufenthalt
-
Bewerbung
- Auswahlgrenzen und Vergabeverfahren (NC)
- Bewerbungsportal
- Bewerbung Schritt für Schritt: Von der Bewerbung bis zur Einschreibung
- Bewerbung für ein höheres Fachsemester
- Bewerbung mit beruflicher Qualifikation
- Gasthörerschaft und Zweithörerschaft
- Kontakt Studierendenservice
- Losverfahren
- Promotion
- Sonderanträge
- Studiengang wählen
- Wer kann an der HSBI studieren?
- Studienstart
-
Studium organisieren
- Studierendenservice
- Abschlussunterlagen
- Anerkennung von Leistungen
- Anträge einreichen
- Beurlaubung
- CampusCard
- Einreichung schriftliche Arbeiten
- Erstattung
- Exmatrikulation
- IT-Services
- Online-Serviceportale (LSF/CAT)
- Prüfungsangelegenheiten: Ordnungen, Modulhandbücher
- Rücktritt von einer Modulprüfung
- Rückmeldung
- Semesterbeitrag
- Semesterticket (Studi-Deutschlandticket)
- Semester-, Vorlesungs- und Prüfungszeiten
- Studienbezogene Auslandserfahrung
- Studiengebühren
- Vorlesungsverzeichnis
- Rund ums Studium
- Fachbereiche

- Forschung
- Transfer
- Weiterbildung
- Internationales
- Karriere an der HSBI
Hardware-KI-Codesign für die effiziente Ausführung neuronaler Netze
|
Anzahl Studierende |
1 |
|
Art |
Projekt mit externen Partnern |
|
Projektverantwortung |
Prof. Dr.-Ing. habil. Thorsten Jungeblut, Dr.-Ing. Qazi Arbab Ahmed |
|
Projektkontext |
CareTech OWL Transferprojekt in Zusammenarbeit mit dem externen Partner, der Steinel GmbH, im Rahmen des Forschungsprojekts CareTech OWL. Eine parallele Beschäftigung als studentische Hilfskraft (WHK) ist möglich. |
Abstrakt
Das Paradigma der künstlichen Intelligenz (KI) hat eine Handvoll traditioneller Computer-Vision-Techniken ersetzt, um die korrekte Ausgabe eines komplexen Systems unter engen Einschränkungen und unterschiedlichen Bedingungen intelligent vorherzusagen. Viele KI-Algorithmen benötigen jedoch aufgrund ihrer massiven Rechenanforderungen enorme Mengen an Hardwareressourcen. Ziel dieses Projekts ist die Entwicklung eines Frameworks für die effiziente Implementierung von KI- und ML-Algorithmen auf stark ressourcenbeschränkten Hardwarearchitekturen. Basierend auf dem Framework werden automatisierte Methoden zur Exploration des Entwurfsraums geeigneter Kombinationen von KI-Algorithmen und Hardware im Sinne von HW/KI-Co-Design erforscht.
Insbesondere industrielle Anwendungen mit hohen Latenzanforderungen werden angesprochen. Dabei wird nicht nur die gesamte Kette als linearer Prozess vom Modelltraining bis zur Inferenz berücksichtigt, sondern auch der Einfluss der Wahl möglicher Hardwarekonfigurationen auf die ursprüngliche Modellentwicklung.
KurzbeschreibungFür die effiziente Ausführung von KI-Algorithmen haben Techniken wie Föderales Lernen (FL) und Cognitive Edge Computing (CEC) bereits die Last des Trainings und der Inferenz neuronaler Netze von der Cloud an den Rand der Datenentstehung verlagert. Die Partitionierung der Ausführung der Anwendung hat einen erheblichen Einfluss auf die Performance und Ressourceneffizienz des Gesamtsystems. So kann hier zwischen grundlegend unterschiedlichen Ansätzen der dezentralen
Merkmalsextraktion möglichst nah am Sensor mit anschließender Fusion versus zentraler
Verarbeitung in der Cloud unterschieden werden. Der erste Ansatz erfordert leistungsstarke Edge-Hardware für die Vorverarbeitung und bietet potenziell Vorteile für hohe Echtzeitanforderungen. Der zweite Ansatz stellt höhere Anforderungen an die Kommunikationsinfrastruktur, ermöglicht aber möglicherweise die Ausführung komplexerer Netzwerke. Das Hauptziel dieses Projekts ist es daher, automatisierte Methoden zur Exploration des Entwurfsraums geeigneter Kombinationen von KI-Methoden und ressourcenbeschränkter Hardware im Sinne von HW/KI-Codesign zu erforschen.
Im Bereich der effizienten Ausführung von KI-Verfahren auf eingebetteten Systemen (Cognitive Edge Computing) wurden in der Vergangenheit große Fortschritte erzielt. Auf allen Ebenen der unterschiedlichen Verarbeitungskonzepte (Cloud, Fog, Edge, Very Edge) in der Produktionskette findet sich eine Vielzahl potenzieller Hardwarearchitekturen und KI-Beschleuniger, die sich in den verfügbaren Systemressourcen (z.B. Leistung oder Stromverbrauch) unterscheiden. Beispiele für relevante Hardwarearchitekturen sind eingebettete Mikrocontroller mit integrierter KI-Beschleunigung, eingebettete GPUs/FPGAs, dedizierte KI-Hardwarebeschleuniger oder High-EndGPUs/FPGAs aus dem HPC-Bereich.
Wir betrachten die gesamte Verarbeitungskette, beginnend mit der sensornahen Vorverarbeitung (very edge), über die Verbindung der Sensorgruppen und ihrer Informationen in der Edge, über lokale dezentrale Cloud-Instanzen (Fog), bis hin zur zentralen Station aller relevanten Informationen (Cloud). Auf jeder Ebene der Verarbeitungskette existieren individuelle Ansätze, um die Ressourceneffizienz von KI-Prozessen lokal zu optimieren, z. B. durch Reduzierung der numerischen Präzision (z. B. von 32 auf 16 oder 8 Bit), um eine effizientere Ausführung auf spezialisierter Hardware zu ermöglichen oder den lokalen Speicherplatz zu minimieren. Ziel ist es, eine optimale Kombination von Hard- und Software (d.h. KI-Algorithmus) im Rahmen einer ganzheitlichen Entwurfsraumexploration auf allen Verarbeitungsebenen zu ermitteln.
AufgabenstellungIn diesem Projekt werden die Studierenden ein automatisiertes Toolkit für die Entwurfsraumexploration entwickeln, das den Benutzer beim HW/KI-Codesign unterstützen kann. Um den nachhaltigen Einsatz der entwickelten Methoden und Frameworks durch den Industriepartner zu unterstützen, sollen in diesem Projekt universell einsetzbare Modelle und automatisierte Entwurfswerkzeuge in Form eines Entwicklungsbaukastens zur Verfügung gestellt werden, der von den konkreten Anwendungsfällen abstrahiert und es ermöglicht, anhand eines zukünftigen Anwendungsszenarios Empfehlungen für eine optimale Kombination von KI-Methoden und geeigneter (Edge-)Hardwarearchitektur zu erhalten. Ziel ist es, dem Anwender vorläufige Modelle und automatisierte Entwurfswerkzeuge zur Verfügung zu stellen, die Empfehlungen für eine Kombination aus KI-Methoden und geeigneter (Edge-) Hardwarearchitektur auf Basis eines gegebenen Anwendungsszenarios und Bewertungsmaßnahmen ermöglichen.
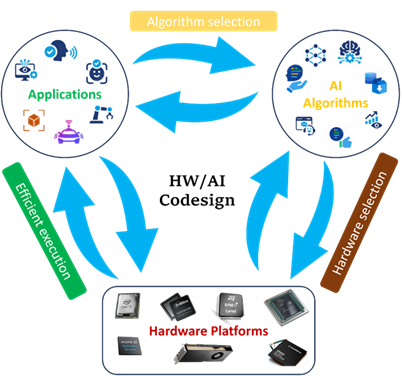
Bild 1 veranschaulicht das allgemeine Konzept der Exploration des Entwurfsraums für das Hardware-AI-Codesign. Die erste Hauptherausforderung ist die Komprimierung/Optimierung des neuronalen
Netzes, um die Größe zu reduzieren und dennoch eine akzeptable Genauigkeit zu erreichen, indem KI-Approximationstechniken verwendet werden. Die nächste Herausforderung besteht in der Entwicklung ressourceneffizienter Techniken zur Abbildung des komprimierten (KI-)Modells auf eine geeignete Hardwareplattform wie GPUs, CPUs, ASICs und FPGAs unter Berücksichtigung der Ressourcennutzung in Bezug auf Fläche, Leistung/Energie und Latenz/Durchsatz.
Bezug zum Thema Data ScienceDie Evaluierung und Anwendung von KI/ML-Methoden im Bereich "Maschinelle Sehens", z.B. der Einsatz von CNNs in der Objektklassifikation, sind ein Kernthema der Data Science und werden z.B. in den Modulen "Data Mining & Machine Learning" und "Künstliche Intelligenz" behandelt. KI-gestützte Bildverarbeitung stellt hohe Anforderungen an die Organisation und Verarbeitung von Daten auf allen Ebenen von IoT-Verarbeitungskonzepten (Edge/Fog/Cloud). Dies ist der Kern des Moduls "Big Data Architekturen". Die Betrachtung des gesamten Systemprozesses vom bildgebenden Sensor bis zur Cloud erfordert eine ganzheitliche Betrachtung des gesamten Data Science Prozesses, die im Modul "Data Science" behandelt wird.
Verfügbare RessourcenSicherstellung der Verfügbarkeit von Daten, Rechenressourcen, Hardware, Anwendungsexperten
- Sicherstellung der Verfügbarkeit von Daten, Rechenressourcen, Hardware, Anwendungsexperten
- Bereitstellung der für die Erstellung des Szenarios erforderlichen Informationen (Systembeschreibung, Schnittstellen, Dokumentation, relevante Kennzahlen etc.)
- Steinel GmbH stellt umfangreiche Testdatensätze aus realen Produktionsumgebungen zur Verfügung
- Der Ansprechpartner der Steinel GmbH steht während der gesamten Projektlaufzeit zur Verfügung
- Die Steinel GmbH stellt die für die Prototyp-Entwicklung benötigten Komponenten sowie weitere benötigte Materialien zur Verfügung
- Hardware für das komplexere maschinelle Lernen ist über das Data Science Lab, den CfADS und den KI-Computing-Cluster yourAI an der Hochschule Bielefeld verfügbar
Erstes Semester: Erstellung eines Forschungsexposés als Prüfungsleistung. Einarbeitung in das Konzept der KI-Algorithmen (CNN, DNN), insbesondere der Objekterkennung und Bilderkennung, der verwendeten Hardware-Plattformen und Design-Flow-Tools.
Zweites Semester: Erstellung des Systemkonzepts für die Design Space Exploration von Cognitive Edge
Computing Architekturen. Recherche zu relevanten Arbeiten im Bereich der Nutzung von KI/ML-Methoden zur Datenverarbeitung und Modellkompression im oben genannten Kontext. Erstellung eines Papers, das einen Überblick über das jeweilige Forschungsgebiet gibt, als Prüfungsleistung.
Drittes Semester: Entwicklung eines ersten Demonstrators und Proof-of-Concept für die Hardware-Beschleunigung einer relevanten Anwendung. Vergleich eines KI-Prozesses mit einer klassischen Implementierung.
Viertes Semester: Masterarbeit und Kolloquium. Implementierung und Vergleich verschiedener Kombinationen von KI/ML-Verfahren und Hardwarebeschleunigern. Systematische Evaluierung und Erforschung der Effizienz der Kombinationen. Vergleich verschiedener Verarbeitungskonzepte (Embedded AI, Edge, Cloud). Abschließende Bewertung durch Vergleich der implementierten Strategien. Erstellung eines Papers mit den ersten quantitativen Ergebnissen als Prüfung.
EignungskriterienMandatory:
- Gute Kenntnisse in Python, Pytorch
- Gute Kenntnisse von C++ Optional:
- Erfahrung mit Hardware-Design-Flow-Tools
- Programmierung von Mikrocontrollern/FPGAs
- Grundkenntnisse in HDL (Verilog, VHDL)
- Erfahrung mit IoT-Geräten
- Erfahrung mit dem Versionskontrollsystem "git".
- Ressourceneffiziente Informationsverarbeitung am Edge (eingebettete Mikrocontroller,
FPGAs) im Einklang mit dem IoT-Verarbeitungskonzept
- Sensorbezogene Informationsverarbeitung
- AI/ML-Methoden
- Nutzung von eingebetteter Hardware zur Beschleunigung von AI/ML-Prozessen