- Home
- Hochschule
-
Studium
- Studienangebote
-
Beratung
- Studienorientierung
- Zentrale Studienberatung
- Studienfachberatung
- Psychosoziale Beratung
- Studienfinanzierungsberatung und Stipendien
- Schreibberatung
- Studieren mit beruflicher Qualifikation
- Studieren mit ausländischen Zeugnissen
- Studieren mit Handicap
- Studieren mit Familie
- Informationen für Schulen
- Auslandsaufenthalt
-
Bewerbung
- Auswahlgrenzen und Vergabeverfahren (NC)
- Bewerbungsportal
- Bewerbung Schritt für Schritt: Von der Bewerbung bis zur Einschreibung
- Bewerbung für ein höheres Fachsemester
- Bewerbung mit beruflicher Qualifikation
- Gasthörerschaft und Zweithörerschaft
- Kontakt Studierendenservice
- Losverfahren
- Promotion
- Sonderanträge
- Studiengang wählen
- Wer kann an der HSBI studieren?
- Studienstart
-
Studium organisieren
- Studierendenservice
- Abschlussunterlagen
- Anerkennung von Leistungen
- Anträge einreichen
- Beurlaubung
- CampusCard
- Einreichung schriftliche Arbeiten
- Erstattung
- Exmatrikulation
- IT-Services
- Online-Serviceportale (LSF/CAT)
- Prüfungsangelegenheiten: Ordnungen, Modulhandbücher
- Rücktritt von einer Modulprüfung
- Rückmeldung
- Semesterbeitrag
- Semesterticket (Studi-Deutschlandticket)
- Semester-, Vorlesungs- und Prüfungszeiten
- Studienbezogene Auslandserfahrung
- Studiengebühren
- Vorlesungsverzeichnis
- Rund ums Studium
- Fachbereiche
- Forschung
- Transfer
- Weiterbildung
- Internationales
- Karriere an der HSBI
- Hochschule
- Studium
- Studium
- Studienangebote
-
Beratung
- Studienorientierung
- Zentrale Studienberatung
- Studienfachberatung
- Psychosoziale Beratung
- Studienfinanzierungsberatung und Stipendien
- Schreibberatung
- Studieren mit beruflicher Qualifikation
- Studieren mit ausländischen Zeugnissen
- Studieren mit Handicap
- Studieren mit Familie
- Informationen für Schulen
- Auslandsaufenthalt
-
Bewerbung
- Auswahlgrenzen und Vergabeverfahren (NC)
- Bewerbungsportal
- Bewerbung Schritt für Schritt: Von der Bewerbung bis zur Einschreibung
- Bewerbung für ein höheres Fachsemester
- Bewerbung mit beruflicher Qualifikation
- Gasthörerschaft und Zweithörerschaft
- Kontakt Studierendenservice
- Losverfahren
- Promotion
- Sonderanträge
- Studiengang wählen
- Wer kann an der HSBI studieren?
- Studienstart
-
Studium organisieren
- Studierendenservice
- Abschlussunterlagen
- Anerkennung von Leistungen
- Anträge einreichen
- Beurlaubung
- CampusCard
- Einreichung schriftliche Arbeiten
- Erstattung
- Exmatrikulation
- IT-Services
- Online-Serviceportale (LSF/CAT)
- Prüfungsangelegenheiten: Ordnungen, Modulhandbücher
- Rücktritt von einer Modulprüfung
- Rückmeldung
- Semesterbeitrag
- Semesterticket (Studi-Deutschlandticket)
- Semester-, Vorlesungs- und Prüfungszeiten
- Studienbezogene Auslandserfahrung
- Studiengebühren
- Vorlesungsverzeichnis
- Rund ums Studium
- Fachbereiche

- Forschung
- Transfer
- Weiterbildung
- Internationales
- Karriere an der HSBI
FDM im Forschungsprozess
Der Forschungsdatenlebenszyklus ist ein Modell, welches die verschiedenen Stationen darstellt, welche Forschungsdaten während eines Forschungsprozesses durchlaufen. Hierbei handelt es sich um eine idealisierte Darstellung, da die verschiedenen Schritte oft eng miteinander verknüpft sind und sich teilweise überschneiden.
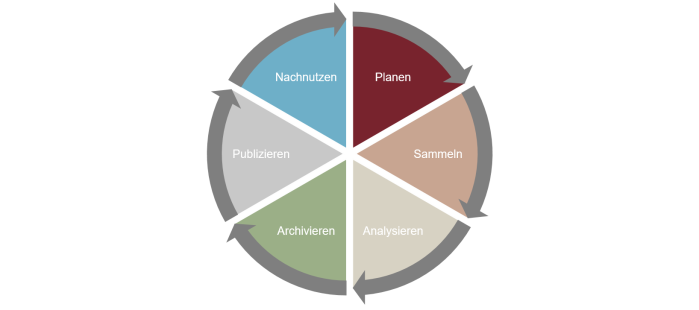
Planen
Sammeln
Analysieren
Archivieren
Publizieren
Nachnutzen