Intro: Was ist Künstliche Intelligenz?
TL;DR
KI ist ein altes und modernes Forschungsgebiet, welches periodisch Hype-Zeiten erlebt hat und sich aktuell
wieder in einer Hoch-Phase befindet. Wer heute "KI" sagt, meint meist Maschinelles Lernen oder (noch genauer)
eine Form von Deep Learning. Dabei gibt es in der KI viele weitere Gebiete: Suche (Problemlösen), Spiele,
Constraintprobleme, Entscheidungsbäume, ..., um nur einige zu nennen.
Der Turing-Test (Alan Turin, 1950) hat gewissermaßen die modernen Zweige der KI begründet, u.a.
Wissensrepräsentation, Logisches Schließen, Maschinelles Lernen, Verarbeitung natürlicher Sprache,
Computer Vision und Robotik. Dabei ist zwischen starker KI und schwacher KI zu unterscheiden.
Häufig werden die Gebiete in einem Diagramm eingeordnet, wobei die x-Achse Verhalten vs. Denken und
die y-Achse Rational vs. Menschlich aufspannen. So kann man beispielsweise Logik dem rationalen Denken
zuordnen oder die Erforschung kognitiver Prozesse dem Quadranten menschliches Denken.
Wenn man sich die Geschichte der KI anschaut, beobachtet man bei fast allen Themen, dass sie in der
Vergangenheit eine Hype-Phase erlebt haben und dabei die oft stark überzogenen Erwartungen enttäuscht
haben und danach meist nur wenig Beachtung erfuhren. Nach einer Weile kamen die Themen wieder
"auf die Tagesordnung", diesmal mit vernünftigen Erwartungen.
Videos (HSBI-Medienportal)
Lernziele
- (K1) Aspekte, die zur Intelligenz gerechnet werden
- (K1) Turing-Test: Aufbau, Gebiete, Kritik
- (K1) Gebiete der KI sowie deren Zielsetzung
- (K1) Starke vs. schwache KI
- (K1) Wichtige Strömungen in der KI und ihre zeitliche Einordnung
Was ist (künstliche) Intelligenz?

Quelle: AvB - RoboCup 2013 - Eindhoven by RoboCup2013 on Flickr.com (CC BY 2.0)
- Was ist (künstliche) Intelligenz?
- Ist Commander Data intelligent?
- Woran erkennen Sie das?
Definition Intelligenz
Intelligenz (von lat. intellegere "verstehen", wörtlich "wählen zwischen ..."
von lat. inter "zwischen" und legere "lesen, wählen") ist in der
Psychologie ein Sammelbegriff für die kognitive Leistungsfähigkeit des
Menschen. Da einzelne kognitive Fähigkeiten unterschiedlich stark ausgeprägt
sein können und keine Einigkeit besteht, wie diese zu bestimmen und zu
unterscheiden sind, gibt es keine allgemeingültige Definition der
Intelligenz.
Quelle: "Intelligenz" by Cumtempore and others on Wikipedia (CC BY-SA 3.0)
Das ist spannend: Es gibt keine allgemeingültige Definition für den Begriff "Intelligenz".
Damit wird es schwierig, auch "Künstliche Intelligenz" zu definieren ...
Aber wir können aus dieser Definition auf Wikipedia mitnehmen, dass es um kognitive
Fähigkeiten geht. Verstehen und im weiteren Sinne Denken sind bereits im Begriff enthalten
und damit auch Teil der kognitiven Fähigkeiten.
Schauen wir uns nun noch die Definition von "kognitiven Fähigkeiten" genauer an.
Zu den kognitiven Fähigkeiten eines Menschen zählen die
Wahrnehmung, die Aufmerksamkeit, die Erinnerung, das Lernen, das
Problemlösen, die Kreativität, das Planen, die Orientierung, die
Imagination, die Argumentation, die Introspektion, der Wille, das
Glauben und einige mehr. Auch Emotionen haben einen wesentlichen kognitiven
Anteil.
Quelle: "Kognition" by Arbraxan and others on Wikipedia (CC BY-SA 3.0)
Zu den kognitiven Fähigkeiten und damit zur Intelligenz zählen also eine Reihe von
Fähigkeiten, die man Menschen im allgemeinen zuschreibt. Lernen und Problemlösen
und Planen sind Dinge, die vermutlich jeder direkt mit dem Begriff Intelligenz
verbindet. Interessanterweise gehören auf auch Aufmerksamkeit und Wahrnehmung und
Orientierung mit dazu -- Fähigkeiten, die beispielsweise in der Robotik sehr
wichtig sind. Kreativität und Vorstellung zählen aber auch mit in den Bereich der
kognitiven Fähigkeiten und damit zum Begriff Intelligenz. In der KI werden diese
Gebiete zunehmend interessant, etwa beim Komponieren von Musik und beim Erzeugen
von Bildern oder Texten. Mit Emotionen beschäftigt sich die KI-Forschung aktuell
nur am Rande, etwa bei der Erkennung von Emotionen in Texten. Andere Gebiete der
kognitiven Fähigkeiten wie Glaube und Wille spielen derzeit keine Rolle in der KI.
Versuch einer Definition für "KI"
Ziel der KI ist es, Maschinen zu entwickeln, die sich verhalten, als
verfügten sie über Intelligenz.
-- John McCarthy (1955)
Einwand: Braitenberg-Vehikel zeigen
so etwas wie "intelligentes" Verhalten, sind aber noch lange nicht intelligent! Bezieht
sich nur auf Verhalten!
KI ist die Fähigkeit digitaler Computer oder computergesteuerter Roboter,
Aufgaben zu lösen, die normalerweise mit den höheren intellektuellen
Verarbeitungsfähigkeiten von Menschen in Verbindung gebracht werden ...
-- Encyclopedia Britannica
Einwand: Dann wäre aber auch Auswendig-Lernen oder das Multiplizieren langer
Zahlen als intelligent zu betrachten! Bezieht sich vor allem auf "Denken"!
Artificial Intelligence is the study of how to make computers do things at
which, at the moment, people are better.
-- Elaine Rich ("Artificial Intelligence", McGraw-Hill, 1983)
Quelle: nach [Ertel2017, pp. 1-3]
Dazu gehört auch
- Anpassung an sich verändernde Situationen
- Erkennung von Bildern und Gesichtern und Emotionen
- Erkennung von Sprache
- Umgang mit kontextbehafteten, unvollständigen Informationen
- Ausräumen von Geschirrspülern ;-)
- Über Emotionen und Empathie verfügen
KI-Grundverordnung der EU
Die EU hat am 13. Juni 2024 die sogenannte "KI-Verordnung" verabschiedet ("VERORDNUNG (EU) 2024/1689 DES EUROPÄISCHEN PARLAMENTS UND DES RATES",
Document 32024R1689: Verordnung (EU) 2024/1689 des Europäischen Parlaments und des Rates vom 13. Juni 2024 zur Festlegung harmonisierter Vorschriften für künstliche Intelligenz und zur Änderung der Verordnungen (EG) Nr. 300/2008, (EU) Nr. 167/2013, (EU) Nr. 168/2013, (EU) 2018/858, (EU) 2018/1139 und (EU) 2019/2144 sowie der Richtlinien 2014/90/EU, (EU) 2016/797 und (EU) 2020/1828 (Verordnung über künstliche Intelligenz) (Text von Bedeutung für den EWR)).
Dort finden Sie unter Artikel 3 "Begriffsbestimmungen" unter Absatz 1 eine Begriffsdefinition.
Ein "KI-System" wird darin als ein maschinengestütztes System definiert, in irgendeiner Art für
einen autonomen Betrieb ausgelegt ist und eine gewisse Anpassungsfähigkeit haben kann. Zusätzlich
soll das "KI-System" aus den Eingaben Vorhersagen und Entscheidungen zu treffen oder auch Inhalte
erzeugen und mit der physischen oder digitalen Umwelt interagieren können.
Quelle: VERORDNUNG (EU) 2024/1689 DES EUROPÄISCHEN PARLAMENTS UND DES RATES, Art. 3 Abs. 1
Interessant ist, dass dabei nicht explizit auf Softwaresysteme eingegangen wird. Später im
Text finden sich Hinweise, dass sich ein KI-System vermutlich als Software repräsentiert,
auch kommen Modelle und Daten vor. Bei den Modellen kommt der Begriff des Lernens vor, in
allen derzeit üblichen Varianten (überwachtes Lernen, unüberwachtes Lernen, Reinforcement
Learning). Große Teile des Dokuments beschäftigen sich mit weitreichenden Bestimmungen für
Akteure, die ein KI-System zur Verfügung stellen wollen.
Lesen Sie selbst: VERORDNUNG (EU) 2024/1689 DES EUROPÄISCHEN PARLAMENTS UND DES RATES.
Alan Turing 1950: Turing-Test (begründet Zweige der KI)
- Wann verhält sich eine Maschine intelligent?

Quelle: Turing Test version 3.png by Bilby on Wikimedia Commons (Public Domain)
Zum Bestehen des Turing-Tests ist (u.a.) erforderlich:
- Wissensrepräsentation: Speichern des gesammelten Wissens => Wissensbasierte Systeme
- Logisches Schließen: Beantworten von Fragen mit Hilfe des vorhandenen Wissens => Logik, Resolution
- Maschinelles Lernen: Anpassung an veränderliches Umfeld => Musteranalyse und Mustererkennung und Mustervorhersage
- Verarbeitung natürlicher Sprache: Erfolgreiche Kommunikation, beispielsweise in Englisch => NLP
"Totaler Turing-Test": zusätzlich Computer Vision (Erkennen von Objekten) und
Robotik (Manipulation von Objekten)
Damit begründet der Turing-Test die Gebiete der KI.
Problem: Der Turing-Test ist nicht reproduzierbar, nicht konstruktiv und
nicht mathematisch analysierbar ... Außerdem wird durch den Turing-Test im Wesentlichen
nur Funktionalität geprüft, nicht ob Intention oder Bewusstsein vorhanden ist.
Starke vs. schwache KI
"Schwache KI"
- Simulation intelligenten Verhaltens
- Lösung konkreter Probleme
- Adaptives Verhalten ("Lernen")
- Umgang mit Unsicherheit und unvollständigen Informationen
"Starke KI"
- Eigenschaften der "schwachen KI"
- Intelligenz nach menschlichen Maßstäben (auf "Augenhöhe")
- Bewusstsein
- Emotionen (?)
- Empathie
Frage
Wie würden Sie Systeme wie ChatGPT einordnen? Woran machen Sie das fest?
Typische Ansätze in der KI

Untersuchung von
- Verhalten vs. Denken
- Rational vs. menschlich
Motivation dabei
- Menschliche Intelligenz verstehen
- Intelligente/intelligent wirkende Systeme bauen
Damit erhält man vier Kombinationen:
- Menschliches Denken
- Rationales Denken
- Rationales Verhalten
- Menschliches Verhalten
Menschliches Denken: Kognitive Modellierung
- Welche kognitiven Fähigkeiten sind für intelligentes Verhalten nötig?
Wie laufen Denkprozesse im Gehirn ab?
- Erfordert Theorien über interne Aktivitäten des Gehirns
- Ansätze:
- top-down: Vorhersage und Test von menschlichem Verhalten
- bottom-up: Auswertung neurobiologischer Daten
- Wissenschaftszweige: Kognitionswissenschaft (Verbindung der
Computermodelle der KI mit den Experimenten und Theorien der
Psychologie), Neurobiologie/-informatik
Neuronale bzw. Konnektionistische KI
Die Schule der sogenannten "Neuronalen bzw. Konnektionistischen KI" verfolgt den Ansatz,
die biologischen Prozesse im Gehirn zu verstehen und nachzubauen (bottom-up Ansatz) und auf
reale Probleme anzuwenden.
Dank massiver Rechenleistung, riesigen Datenmengen und geeigneten Modellen (Deep Learning)
kann diese Tradition aktuell große Erfolge vorzeigen.
Rationales Denken: Aristoteles: Was sind korrekte Argumente und Denkprozesse? => Wie sollen wir denken?
Beispiel:
Fakt: Sokrates ist ein Mensch.
Fakt: Alle Menschen sind sterblich.
Folgerung: Sokrates ist sterblich.
- Formalisierte Problembeschreibung
- Problemlösung durch logische Prozesse
- Verbindung von moderner KI zur Mathematik und Philosophie
Symbolische KI
Die Schule der sogenannten "Symbolische KI" verfolgt den top-down-Ansatz, mit Hilfe
formaler Beweise Schlüsse zu ziehen und damit Fragen zu beantworten bzw. Probleme zu lösen.
Dabei wird die betrachtete "Welt", also Gedanken, Konzepte und Beziehungen zwischen Objekten
durch Symbole und Formeln repräsentiert, ähnlich der Art und Weise, wie Menschen logisch
denken und kommunizieren.
Das Hauptproblem dieser Tradition liegt im Aufwand bei der geeigneten Formalisierung der
realen Welt.
Rationales Verhalten: Das "Richtige" tun
-
Das "Richtige": Verhalten zum Erzielen des besten (erwarteten)
Ergebnisses (unter Berücksichtigung der verfügbaren Informationen)
Ein System ist rational, wenn es das seinen Kenntnissen nach "Richtige"
macht.
-
Denken ist nicht unbedingt notwendig (zb. Reflexe können auch rationales
Verhalten sein)
-
Interessant: "richtige" Handlung unter unvollständigen/unsicheren
Informationen
Statistische KI
Die Schule der sogenannten "Statistischen KI" verfolgt einen Ansatz, der sich stark auf
statistische Methoden und Modelle stützt, um Muster in Daten zu erkennen und Entscheidungen zu
treffen, also um aus großen Datenmengen Erkenntnisse zu gewinnen und Vorhersagen zu treffen.
Aus der Analyse von Datenpunkten und deren Merkmalen werden Wahrscheinlichkeiten für bestimmte
Ereignisse berechnet, beispielsweise in Regressionsanalysen, Klassifizierungsverfahren oder
Zeitreihenanalysen.
Diese Tradition spielt eine zentrale Rolle in zahlreichen Anwendungsbereichen wie
Gesundheitswesen, Finanzen, Marketing und vielen weiteren.
Menschliches Verhalten: Na ja, Sie wissen schon ;-)
Modelle, Lernen und Vorhersagen
In der Informatik allgemein und auch in der KI versuchen wir, Probleme der realen Welt mit
Hilfe von künstlichen Systemen (Algorithmen, Software) zu lösen. Dafür brauchen wir zunächst
ein abstraktes mathematisches Modell der Welt, in der wir uns bewegen. Das Modell sollte
alle für das zu lösende Problem relevanten Aspekte der Welt repräsentieren - und möglichst
nicht mehr als diese, um unnötige Komplexität zu vermeiden. Es kommt häufig vor, dass selbst
die relevanten Aspekte zu umfangreich oder teilweise sogar unbekannt sind und nicht
vollständig dargestellt werden können. Modelle stellen also eine Abstraktion der echten Welt
dar und sind verlustbehaftet. Es gibt viele verschiedene Modelle.
Beispiel: Wir möchten von Bielefeld nach Minden fahren. Neben den offensichtlichen
Parametern (Womit wollen wir fahren? Wo genau ist der Startpunkt, wo genau der Zielpunkt? Wann
wollen wir fahren?) spielen in der realen Welt unendlich viele Aspekte eine Rolle: Farben,
Gerüche, Licht, Beschaffenheit der einzelnen Straßen, exakte Positionen auf der Straße/im Ort
... Sind diese wirklich relevant für dieses Problem? Am Ende wird es wichtig sein, eine
abstrakte Darstellung zu finden, die irgendwie die Städte und Dörfer repräsentiert und die
Verbindungen dazwischen. Und vermutlich muss ich wissen, wie lang die Strecken jeweils sind
(oder wie lange ich brauche oder wieviel Geld mich das Abfahren kostet). Es scheint also so zu
sein, dass eine Abstraktion des Problems als Graph sinnvoll ist: Die Knoten entsprechen den
Orten, die Kanten den Straßen (oder Bahnlinien o.ä.). An den Kanten sind Kosten annotiert
(Kilometer, Zeit, ...). Damit ignorieren wir die Komplexität der realen Welt und fokussieren
uns auf die Aspekte, die zur Lösung des Problems wichtig sind. Behalten Sie im Gedächtnis,
dass unser Modell verlustbehaftet ist und wir damit tatsächlich nur das Wegeproblem lösen
können! Wenn wir Wege vergessen haben oder falsch bewertet haben, wird unser Algorithmus
später möglicherweise nicht die gewünschte Lösung finden! Wir schauen uns das Thema
Modellierung am Beispiel des Problemlösens und insbesondere für Suchprobleme in der Lektion
Problemlösen noch genauer an.
Ein Modell kann Parameter haben. Im obigen Beispiel wären dies die Werte an den Kanten. Es
kann sein, dass diese Werte nicht im Vorfeld bekannt sind, sondern aus einem Datensatz
extrahiert werden müssen. Dies nennt man Lernen: Das Modell wird (besser gesagt: die
Parameter des Modells werden) an das Problem angepasst. Dafür gibt es unterschiedliche
Algorithmen. In der Regel benötigt man ein Ziel für den Adaptionsprozess: eine sogenannte
Ziel- oder Kostenfunktion. Anpassen der Modellparameter mit Hilfe von Daten und einer
Zielfunktion bedeutet auch, dass man das Ziel möglicherweise nie zu 100% erreicht, sondern nur
in die Nähe kommt. Je nach Problem kann man auch nur eine Modellfamilie vorgeben und den
konkreten Aufbau des Modells im Trainingsprozess erarbeiten lassen.
Wichtig: Lernen bietet sich immer dann an, wenn eine analytische Lösung nicht möglich ist
(fehlende Informationen, Komplexität des Problems). Das bedeutet im Umkehrschluss aber auch:
Wenn eine analytische Lösung bekannt ist (oder zu finden ist), dann gibt es keinen Grund für
den Einsatz von adaptiven Systemen!
Mit dem Modell der Welt kann nun das Problem gelöst werden. Dazu wird das Modell mit Daten
versorgt (im obigen Beispiel: Start und Ziel) und ein passender Algorithmus kann auf dem
Modell die Lösung berechnen. Dies kann eine Vorhersage sein, welchen Weg ich nehmen soll,
wie lange es dauern wird, welchen Spielzug ich als nächstes machen sollte, ob in einem Bild
eine Katze zu sehen ist, ... Es könnte aber auch im Fall von sogenannten generativen
Modellen ein erzeugter Text oder ein erzeugtes Bild sein.
Hinweis: In manchen Quellen wird dieser Vorgang auch "Inferenz" genannt. Da dieser Begriff
aus der Logik stammt und mit bestimmten Prozessen zur Schlussfolgerung verbunden ist, möchte
ich in diesem Skript diesen Begriff nicht für das Generieren einer Vorhersage nutzen.
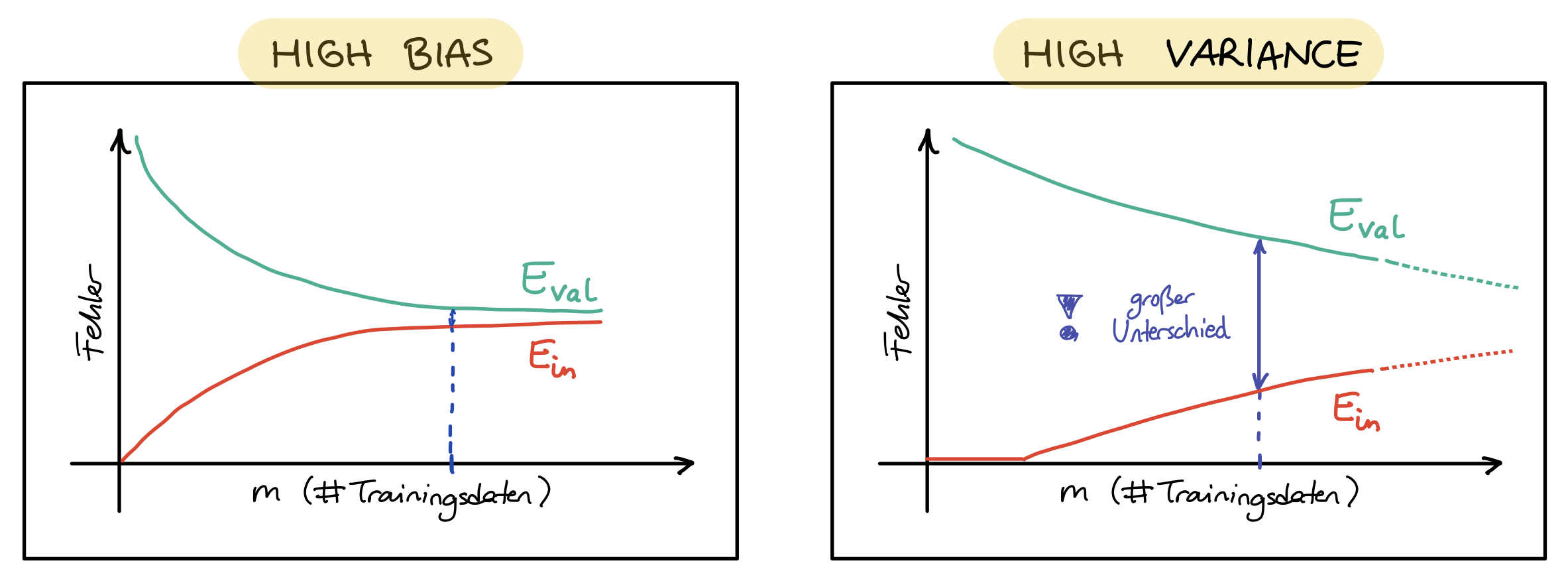
Modellkomplexität
In der KI werden sehr unterschiedliche Modelle betrachtet, die auch eine sehr unterschiedliche
Komplexität aufweisen.
Besonders einfache Modelle sind Modelle, die für einen Input direkt einen Output berechnen.
Für jeden Input wird eine feste Berechnung durchgeführt, es erfolgt kein Backtracking und es
gibt keine (inneren) Zustände. Dies ähnelt dem reflexartigen Verhalten in biologischen
Vorbildern, weshalb diese Modell oft auch "reflex-based models" genannt werden. In diese
Kategorie fallen beispielsweise lineare Regression und das
Perzeptron, aber auch Modelle mit vielen Parametern wie ein
Multilagen-Perzeptron (MLP) oder die daraus abgeleiteten Deep Neural
Networks.
In der nächst komplexeren Stufe haben die Modelle einen internen Zustand ("state-based
models"). Darüber wird ein Zustand der betrachteten Welt modelliert. Zwischen den Zuständen
gibt es Übergänge (sogenannte Aktionen), so dass sich hier ein Graph aufspannt (der sogenannte
Problemgraph, vgl. Problemlösen). In diese Klasse fallen die
typischen Suchprobleme (wie Breitensuche,
Tiefensuche, A*), aber auch
Spiele mit Zufallskomponente oder mit gegnerischen Mitspielern.
Noch eine Stufe komplexer sind Modelle mit Variablen ("variable-based models"). Während es
bei den zustandsbasierten Modellen immer (auch) um den Weg zwischen den Zuständen geht und
damit um eine prozedurale Beschreibung, wie von einem Startzustand zu einem Zielzustand zu
gelangen ist, steht bei Modellen mit Variablen nur die Lösung im Vordergrund: Das Modell
enthält verschiedene Variablen, denen ein passender Wert aus einem Wertebereich zugeordnet
werden muss. Wie diese Belegung entsteht, ist am Ende nicht mehr so interessant. Denken Sie
beispielsweise an ein Sudoku oder die Erstellung eines Stundenplans. Die Variablen sind
entsprechend die einzelnen Felder, gesucht ist eine insgesamt korrekte Belegung aller Felder.
In diese Klasse fallen Constraint Satisfaction Probleme (CSP), aber auch
Bayes'sche Netze und die sogenannte “lokale Suche”.
Auf der höchsten Komplexitätsstufe stehen logische Modelle. Hier wird Wissen über die Welt in
Form von Fakten und Regeln modelliert, und über eine entsprechende Anfrage wird daraus mit
Hilfe von formal definierten Beweisen eine korrekte Antwort generiert. Dies nennt man auch
"Inferenz". Hier kommt beispielsweise das Prädikatenkalkül zum Einsatz oder die
Programmiersprache Prolog.
Kurzer Geschichtsüberblick -- Wichtigste Meilensteine
- 1943: McCulloch/Pitts: binäres Modell eines Neurons
- 1950: Turing-Test
- 1956: Dartmouth Workshop (Minsky, McCarthy, ...) -- McCarthy schlägt den Begriff "Artificial Intelligence" vor
- 1960er: Symbolische KI (Theorembeweiser), Blockwelt, LISP
- 1970er: Wissensbasierte System (Expertensysteme)
- 1980er: zunächst kommerzieller Erfolg der Expertensysteme, später
Niedergang ("KI-Eiszeit"); Zuwendung zu Neuronalen Netzen
- 1990er: Formalisierung der KI-Methoden, Einführung probabilistischer
Methoden (Bayes'sches Schließen), verstärkte mathematische Fundierung
- heute: friedliche Koexistenz verschiedener Paradigmen und Methoden;
Rückkehr zu "Human-Level AI" (McCarthy, Minsky, Nilsson, Winston); Rückkehr
zu Neuronalen Netzen (CNN/RNN)
Siehe auch Abbildung 1.3 in [Ertel2017, S.8] ...
Wrap-Up
- Definition von "Intelligenz" nicht ganz einfach
- Dimensionen: Denken vs. Verhalten, menschlich vs. rational
- Ziele der KI: Verständnis menschlicher Fähigkeiten, Übertragen auf künstliche Systeme
Schauen Sie sich zur Einführung auch gern das YouTube-Video
Overview Artificial Intelligence Course | Stanford CS221
an. (Vorsicht: Das ist recht lang.)
Problemlösen
TL;DR
Um ein Problem lösen zu können, muss es zunächst geeignet dargestellt werden. In der KI
betrachten wir Zustände einer Welt, auf die Aktionen angewendet werden können und die die
betrachtete Welt in den/einen Folgezustand bringen. Hier muss unterschieden werden zwischen
deterministischen und stochastischen Welten, ebenso spielt die Beobachtbarkeit durch den
Agenten (die die Welt betrachtende und durch die Aktionen auf die Welt einwirkende Instanz)
eine Rolle: Kann der Agent die Welt komplett beobachten, nur einen Teil davon oder gar nichts?
Es spielt auch eine Rolle, ob es diskrete Zustände gibt, oder ob man mit kontinuierlichen
Variablen zu tun hat. Gibt es nur einen Agenten oder können mehrere Agenten beteiligt sein ...
(In dieser Veranstaltung werden wir uns auf deterministische und voll beobachtbare Welten
mit diskreten Zuständen konzentrieren.)
Dies alles muss bei der Modellierung betrachtet werden. Es empfiehlt sich, die Zustände und
die Aktionen so abstrakt wie möglich zu beschreiben. Anderenfalls kann später die Lösung des
Problems zumindest stark erschwert werden.
Durch das wiederholte Anwenden der Aktionen auf den Startzustand bzw. auf die sich daraus
ergebenden Folgezustände wird der Zustandsraum aufgebaut. Dabei ist zu beachten, dass Aktionen
Vorbedingungen haben können, d.h. unter Umständen nicht auf alle Zustände angewendet werden
können. Die entstehende Struktur (Zustandsraum) kann man formal als Graph repräsentieren: Die
Zustände werden durch die Knoten und die Aktionen als (gerichtete) Kanten im Graph dargestellt
(=> Problemgraph).
Das Problemlösen entspricht nun einer Suche im Problemgraphen: Man sucht einen Weg von einem
Startknoten zu einem Zielknoten, d.h. eine Folge von Aktionen, die den Start- in den Zielzustand
überführen. Der Weg entspricht dann der Lösung des Problems. Normalerweise will man eine bestimmte
Qualität der Lösungen haben: Es sollen die kürzesten Wege (also die mit den wenigsten
Zwischenstationen/Knoten) oder die billigsten Wege (die Summe der an den Kanten annotierten Gewichte
soll minimal sein) gefunden werden.
Zur Suche kann man bei den in dieser Veranstaltung betrachteten deterministischen Problemen mit
diskreten Zuständen den einfachen "Tree-Search"-Algorithmus (Benennung in Anlehnung an [Russell2020])
einsetzen, der allerdings Wiederholungen und Schleifen zulässt. Mit zwei Erweiterungen wird daraus
der "Graph-Search"-Algorithmus (Benennung in Anlehnung an [Russell2020]), der die wiederholte
Untersuchung von bereits besuchten Knoten vermeidet. In beiden Algorithmen wird eine zentrale
Datenstruktur eingesetzt (im [Russell2020] auch "Frontier" genannt), die die als Nächstes zu
untersuchenden Knoten hält und die damit die Grenze zwischen dem bereits untersuchten Teil des Graphen
und dem unbekannten Teil des Graphen bildet. Je nach Art der Datenstruktur und je nach den betrachteten
Kosten ergeben sich eine Reihe unterschiedlicher Suchalgorithmen, die wir in einer späteren Sitzung
betrachten.
Die Suchverfahren können im Hinblick auf Optimalität, Vollständigkeit und Komplexität beurteilt
werden.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Definition Problem: Begriffe Zustand, Aktion, Zustandsraum, Problemgraph, Suchbaum
- (K2) Problemlösen als Suche nach Wegen im Problemgraph => Suchbaum
- (K2) Unterschied zw. Tree-Search und Graph-Search
Motivation: Roboter in einer Bibliothek

Aktionen:
- Right (R)
- Left (L)
- Take (T)
- Drop (D)
Wahrnehmungen:
- In welchem Raum bin ich?
- Habe ich das Buch?
Aufgabe: Das Buch aus der Bibliothek holen und in den Kopiererraum bringen.
Bemerkungen zur Umwelt:
- Beobachtbarkeit der Umwelt kann variieren: "voll beobachtbar" bis zu "unbeobachtbar"
- Umwelt kann "deterministisch" oder "stochastisch" sein: Führt eine Aktion in
einem Zustand immer zum selben Folgezustand?
- Wann erfolgt die Rückmeldung an den Agenten über die Auswirkung der
Aktionen? Sofort ("sequentiell") oder erst am Ende einer Aktionsfolge
("episodisch")?
- Wird die Umwelt nur durch die Aktionen des Agenten verändert ("statisch")?
Oder verändert sich die Umwelt zwischen den Aktionen eines Agenten,
beispielsweise durch andere Agenten ("dynamisch")?
- Gibt es diskrete Zustände (wie im Beispiel)?
Zustände der Bibliotheks-Welt

Problem: Gegeben einen Startzustand, wie komme ich zum Ziel?
- Welche Aktionen können in einem Zustand (zb. Nr. 4) angewendet werden?
- Welche Aktionen können in den Folgezuständen angewendet werden?
Ergebnis:
- Zustandsraum: Menge aller von den Startzuständen aus erreichbaren Zustände
- Problemgraph: Repräsentation der Zustände und Aktionen als Knoten und (gerichtete) Kanten
Suche im Problemgraphen

- Durch die Suche im Problemgraphen wird ein Suchbaum aufgespannt
- Varianten: Zustände können in einem Pfad wiederholt vorkommen vs.
Wiederholungen werden ausgeschlossen
Definition Zustand und Aktion
- Zustand:
- (Formale) Beschreibung eines Zustandes der Welt
- Aktion:
-
(Formale) Beschreibung einer durch Agenten ausführbaren Aktion
- Anwendbar auf bestimmte Zustände
- Überführt Welt in neuen Zustand ("Nachfolge-Zustand")
Geeignete Abstraktionen wählen für Zustände und Aktionen!
Anmerkung:
[Russell2020] unterscheidet zw. Aktionen und Transitionsmodell; hier nur Aktionen!
D.h. die Aktionen und das Übergangsmodell aus dem [Russell2020] werden direkt zusammen
betrachtet. Bei den hier diskutierten Problemen ist das ohne Nachteile möglich, es
wird lediglich etwas Flexibilität genommen bzw. Komplexität vermieden (je nach Sichtweise :-) ...
Definition Problem
Ein Problem besteht aus:
- Startzustände
- Menge
- Aktionen
- Menge von Funktionen
- Zustandsraum
- Menge aller Zustände , die durch (wiederholte) Anwendung von Aktionen
von den Startzuständen aus erreichbar sind
- Zieltest
- Funktion
- Zielzustände
- Menge mit
- Kosten
-
Gesamtkosten:
- auf dem aktuellen Weg erreichter Knoten
- tatsächliche Kosten für den Weg vom Start bis zu Knoten
- geschätzte Restkosten für den Weg von Knoten zum Ziel
Hinweis: Unterschied Zustand und Knoten bzw. Zustandsraum und Problemgraph
- Zustände und Aktionen kann man als einen Graph darstellen: Problemgraph
- Zustände werden als Knoten im Graphen abgebildet
- Aktionen werden als (gerichtete) Kanten im Graphen abgebildet
- Unterscheidung "Zustand" und "Knoten":
- Zustand: Beschreibung/Modellierung eines Zustandes der Welt
- Knoten: Datenstruktur, Bestandteil des Graphen,
symbolisiert einen Zustand
Das bedeutet, dass der Problemgraph eine Repräsentation des Zustandsraumes ist.
Die beiden Begriffe werden normalerweise synonym verwendet, sofern eindeutig ist,
was gemeint ist.
Definition Problemlösen
- Problemlösen
-
Wegesuche im Graph vom Startknoten zu einem Zielknoten
- Lösung
-
Folge von Aktionen, die Start- in Zielzustand überführen
Ergebnis des Problemlösens
Suche: Einfache Basisvariante
- Füge Startknoten in leere Datenstruktur (Stack, Queue, ...) ein
- Entnehme Knoten aus der Datenstruktur:
- Knoten ist gesuchtes Element: Abbruch, melde "gefunden"
- Expandiere alle Nachfolger des Knotens und füge diese in die
Datenstruktur ein
- Falls die Datenstruktur leer ist: Abbruch, melde "nicht gefunden"
- Gehe zu Schritt 2
Für die in dieser Veranstaltung betrachteten deterministischen Probleme mit
diskreten Zuständen ist diese Basisvariante der Suche eine Art generischer
Suchalgorithmus: Durch die Variation der eingesetzten Datenstruktur und durch
die Betrachtung unterschiedlicher Kosten erhält man die in den nächsten
Sitzungen betrachteten verschiedenen klassischen Suchalgorithmen.
Anmerkung: Für Handsimulation besserer Überblick, wenn statt der Knoten
immer partielle Wege in Datenstruktur gespeichert werden!
Anmerkung: Im [Russell2020, Abschnitt 3.3.3, S.92] wird ein Algorithmus
mit den vorgestellten Eigenschaften als "tree-like search" bezeichnet.
In Anlehnung an [Russell2020] wird diese Basisvariante der Suche in dieser
Lehrveranstaltung kurz als "Tree-Search"-Algorithmus bezeichnet.
Anmerkung: Im [Russell2020] wird für die Datenstruktur, mit der die
Suche arbeitet, auch "Frontier" genannt. Hier werden alle Knoten gehalten,
die in einem der nächsten Schritte betrachtet werden sollen, d.h. diese Knoten
bilden die Grenze zwischen dem bereits untersuchten Teil des Graphen und dem
noch unbekannten Teil des Graphen (deshalb auch "Frontier").
Erweiterung der Suche: Vermeiden von Wiederholungen
- Füge Startknoten in leere Datenstruktur (Stack, Queue, ...) ein
- Entnehme Knoten aus der Datenstruktur:
- Knoten ist gesuchtes Element: Abbruch, melde "gefunden"
- Markiere aktuellen Knoten, und
- Expandiere alle Nachfolger des Knotens und füge alle unmarkierten
Nachfolger, die noch nicht in der Datenstruktur sind, in die
Datenstruktur ein
- Falls die Datenstruktur leer ist: Abbruch, melde "nicht gefunden"
- Gehe zu Schritt 2
Dieser Algorithmus ist eine Erweiterung der einfachen Basisvariante der
Suche:
- Man markiert bereits besuchte (expandierte) Knoten und besucht diese nie wieder
(man würde diese bei einer Expansion nicht wieder in die Datenstruktur aufnehmen).
- Außerdem vermeidet man, dass ein Knoten mehrfach in der Datenstruktur vorkommt: Dies
würde bedeuten, dass man hier verschiedene Wege vom Start zu diesem Knoten in der
Datenstruktur hat, die dann auch alle weiter untersucht werden müssten. In der Regel
reicht aber ein Weg vom Start zu einem Zwischenknoten (meist wird der kürzeste
genommen, dazu in einer späteren Sitzung mehr).
Anmerkung: Für Handsimulation besserer Überblick, wenn statt der Knoten
immer partielle Wege in Datenstruktur gespeichert werden!
Anmerkung: Im [Russell2020, Abschnitt 3.3.3, S.92] wird ein Algorithmus
mit den vorgestellten Eigenschaften als "graph search" bezeichnet.
In Anlehnung an [Russell2020] wird diese erweiterter Variante der Suche in dieser
Lehrveranstaltung kurz als "Graph-Search"-Algorithmus bezeichnet.
Bewertung von Suchalgorithmen
- Vollständigkeit
- Findet der Algorithmus eine Lösung, wenn es eine gibt?
- Optimalität
- Findet der Algorithmus die beste Lösung?
- Zeitkomplexität
- Wie lange dauert es eine Lösung zu finden?
- Speicherkomplexität
- Wieviel Speicher benötigt die Suche?
Größen zur Bewertung:
- b: Verzweigungsfaktor
- d: Ebene (Tiefe) des höchsten Lösungsknotens
- m: Länge des längsten Pfades
Wrap-Up
-
Begriffe "Problem", "Zustand", "Aktion", "Zustandsraum", "Problemgraph", "Suchbaum"
-
Problemlösen: Suche in Graphen nach Weg vom Start zum Ziel
- Suche spannt einen Suchbaum auf
- Unterschiedliche Kostenfunktionen möglich
- Suchalgorithmen: Einfache Basisvariante, Erweiterung mit Vermeidung von Redundanzen
- Beurteilung der Suchverfahren: Optimalität, Vollständigkeit, Komplexität
Challenges
Drei Elben und drei Orks befinden sich an einem Ufer eines Flusses und wollen diesen überqueren. Es steht dazu ein Pferd zur Verfügung, welches maximal zwei Wesen tragen kann. Das Pferd kann den Fluss nicht allein überqueren.
Gesucht ist eine Möglichkeit, alle Elben und Orks über den Fluss zu bringen. Dabei darf zu keiner Zeit an keinem Ufer die Anzahl der sich dort befindlichen Orks größer sein als die der dort wartenden Elben, da es sonst zu Konflikten zwischen beiden Gruppen kommt.
- Formalisieren Sie das Problem (Zustände, Aktionen, Start- und Endzustand).
- Skizzieren Sie den Problemgraph.