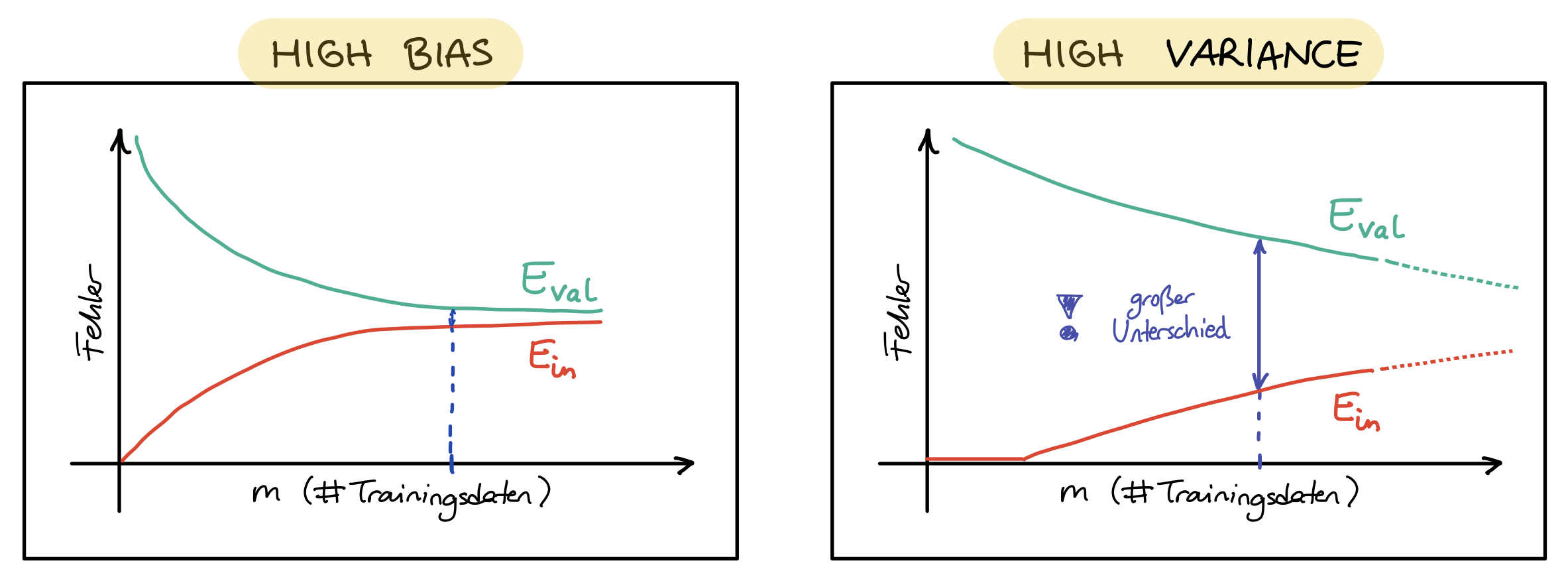
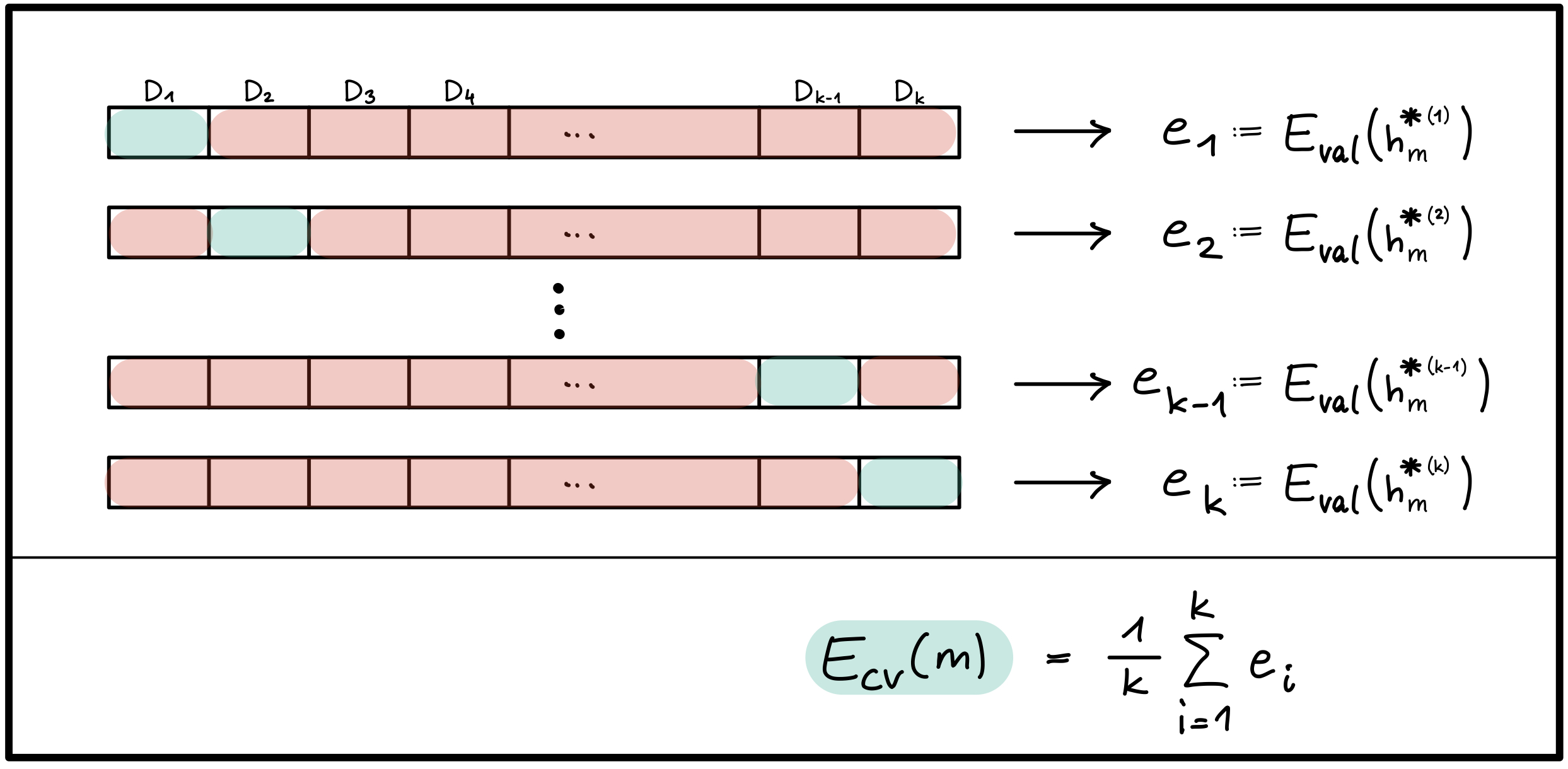
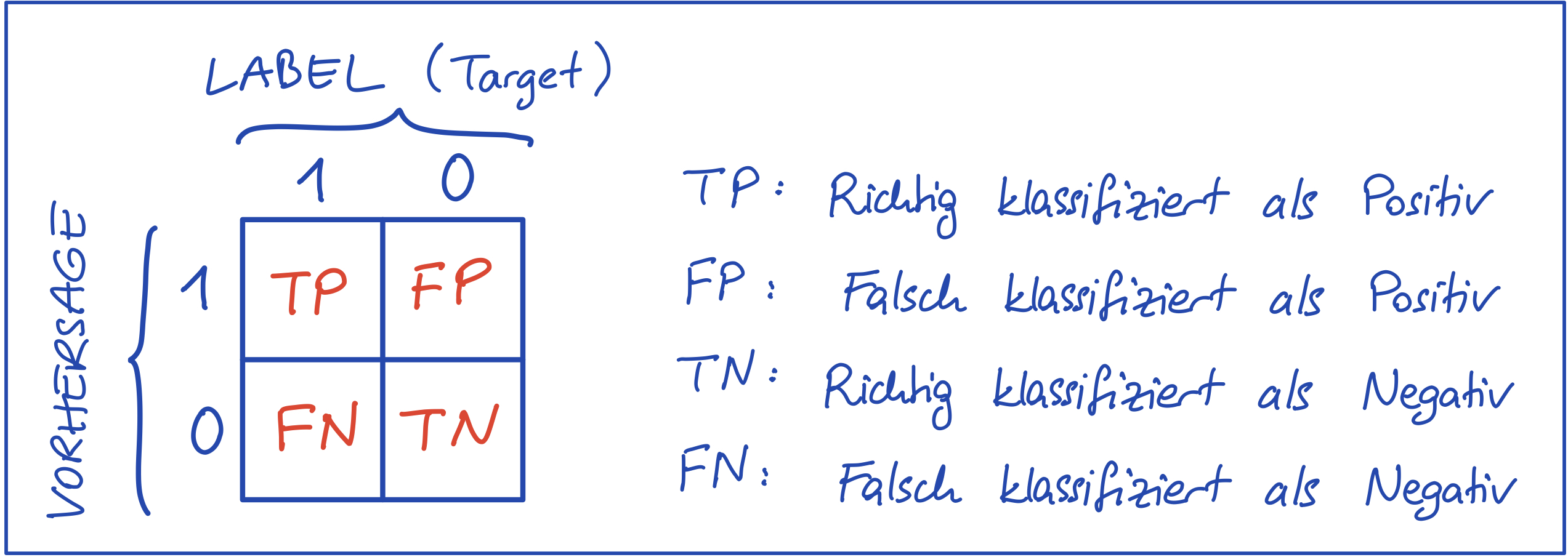
Lineares MLP
Gegeben sei ein MLP mit linearen Aktivierungsfunktionen, d.h. für jedes Neuron berechnet sich der
Output durch die gewichtete Summe der Inputs: $y = g(w^T x)$, wobei $g(z) = z$ gilt, also $y = w^T x$.
Zeigen Sie, dass dieses Netz durch eine einzige Schicht mit linearen Neuronen ersetzt werden kann.
Betrachten Sie dazu ein zwei-schichtiges Netz (i.e. bestehend aus Eingabe-Schicht, Ausgabe-Schicht und einer versteckten Schicht)
und schreiben Sie die Gleichung auf, die die Ausgabe als Funktion der Eingabe darstellt.
Als Beispiel sei das zwei-schichtige MLP mit den folgenden Gewichten und Bias-Werten gegeben:
Schicht 1: $W_1 = [[2, 2],[3, -2]]$, $b_1 = [[1],[-1]]$
Schicht 2: $W_2 = [[-2, 2]]$, $b_2 = [[-1]]$
- Stellen Sie dieses Netzwerk graphisch dar. Was ist die Anzahl der Zellen in den einzelnen Schichten?
- Berechnen Sie die Ausgabe für eine Beispiel-Eingabe Ihrer Wahl.
- Stellen Sie ein ein-schichtiges Netz auf, das für jede Eingabe die gleiche Ausgabe wie das obige Netzwerk berechnet und es somit ersetzen könnte.