Subsections of Versionierung mit Git
Intro: Versionskontrolle in der Softwareentwicklung
TL;DR
In der Softwareentwicklung wird häufig ein Versionsmanagementsystem (VCS) eingesetzt, welches die Verwaltung
von Versionsständen und Änderungen ermöglicht. Ein Repository sammelt dabei die verschiedenen Änderungen
(quasi wie eine Datenbank der Software-Versionsstände). Die Software Git ist verbreiteter Vertreter und
arbeitet mit dezentralen Repositories.
Ein neues lokales Repository kann man mit git init anlegen. Der Befehl legt den Unterordner .git/ im
aktuellen Ordner an, darin befindet sich das lokale Repository und weitere von Git benötigte Dateien
(FINGER WEG!). Die Dateien und anderen Unterordner im aktuellen Ordner können nun der Versionskontrolle
hinzugefügt werden.
Den lokal vorliegenden (Versions-) Stand der Dateien im aktuellen Ordner nennt man auch "Workingcopy".
Ein bereits existierendes Repo kann mit git clone <url> geklont werden.
GitHub ist nicht Git, sondern ein kommerzieller Anbieter, der das Hosten von
Git-Repositories und weitere Features anbietet.
Videos (HSBI-Medienportal)
Lernziele
- (K1) Varianten der Versionierung
- (K1) Begriffe Workingcopy und Repository
- (K2) Github ist nicht Git
- (K2) Erstellung von lokalen Git-Repositories
- (K3) Umgang mit entsprechenden Git-Befehlen auf der Konsole
Typische Probleme bei SW-Entwicklung
- Was hat wer wann (und wo) geändert? Und warum?
- Ich brauche den Stand von gestern/letzter Woche/...
- Ich will schnell mal eine neue Idee ausprobieren ...
- Ich arbeite an mehreren Rechnern (Synchronisation)
- Wir müssen gemeinsam an der gleichen Codebasis arbeiten.
- Wir arbeiten am Release v42, aber Kunde braucht schnell einen Fix für v40
Folgen SW-Entwicklung ohne Versionsverwaltung

- Filesystem müllt voll mit manuell versionierten
Dateien/Sicherungen ala
file_20120507_version2_cagi.txt
- Ordner/Projekte müssen dupliziert werden für neue Ideen
- Code müllt voll mit auskommentierten Zeilen ("Könnte ja noch gebraucht werden")
- Unklar, wann welche Änderung von wem warum eingeführt wurde
- Unbeabsichtigtes Überschreiben mit älteren Versionen beim Upload
in gemeinsamen Filesharing-Bereich
Prinzip Versionsverwaltung
-
Repository:
Datenbank mit verschiedenen Versionsständen, Kommentaren, Tags etc.
-
Workingcopy:
Arbeitskopie eines bestimmten Versionsstandes
Varianten: Zentrale Versionsverwaltung (Beispiel SVN)

Es gibt ein zentrales Repository (typischerweise auf einem Server), von dem die Developer einen
bestimmten Versionsstand "auschecken" (sich lokal kopieren) und in welches sie Änderungen wieder
zurück "pushen".
Zur Abfrage der Historie und zum Veröffentlichen von Änderungen benötigt man entsprechend immer
eine Verbindung zum Server.
Varianten: Verteilte Versionsverwaltung (Beispiel Git)

In diesem Szenario hat jeder Developer nicht nur die Workingcopy, sondern auch noch eine Kopie
des Repositories. Zusätzlich kann es einen oder mehrere Server geben, auf denen dann nur das
Repository vorgehalten wird, d.h. dort gibt es normalerweise keine Workingcopy. Damit kann
unabhängig voneinander gearbeitet werden.
Allerdings besteht nun die Herausforderung, die geänderten Repositories miteinander abzugleichen.
Das kann zwischen dem lokalen Rechner und dem Server passieren, aber auch zwischen zwei "normalen"
Rechnern (also zwischen den Developern).
Hinweis: GitHub ain't no Git! Git ist eine Technologie zur Versionsverwaltung. Es gibt verschiedene
Implementierungen und Plugins für IDEs und Editoren. GitHub ist dagegen ein
Dienstleister, wo man Git-Repositories ablegen kann und auf diese mit Git (von der Konsole oder aus der
IDE) zugreifen kann. Darüber hinaus bietet der Service aber zusätzliche Features an, beispielsweise
ein Issue-Management oder sogenannte Pull-Requests. Dies hat aber zunächst mit Git nichts zu tun.
Weitere populäre Anbieter sind beispielsweise Bitbucket oder Gitlab
oder Gitea, wobei einige auch selbst gehostet werden können.
Versionsverwaltung mit Git: Typische Arbeitsschritte
-
Repository anlegen (oder clonen)
-
Dateien neu erstellen (und löschen, umbenennen, verschieben)
-
Änderungen einpflegen ("committen")
-
Änderungen und Logs betrachten
-
Änderungen rückgängig machen
-
Projektstand markieren ("taggen")
-
Entwicklungszweige anlegen ("branchen")
-
Entwicklungszweige zusammenführen ("mergen")
-
Änderungen verteilen (verteiltes Arbeiten, Workflows)
(Globale) Konfiguration
Minimum:
git config --global user.name <name>git config --global user.email <email>
Diese Konfiguration muss man nur einmal machen.
Wenn man den Schalter --global weglässt, gelten die Einstellungen nur
für das aktuelle Projekt/Repo.
Zumindest Namen und EMail-Adresse muss man setzen, da Git diese
Information beim Anlegen der Commits speichert (== benötigt!).
Aliase:
git config --global alias.ci commitgit config --global alias.co checkoutgit config --global alias.br branchgit config --global alias.st statusgit config --global alias.ll 'log --all --graph --decorate --oneline'
Zusätzlich kann man weitere Einstellungen vornehmen, etwa auf bunte
Ausgabe umschalten: git config --global color.ui auto oder Abkürzungen
(Aliase) für Befehle definieren: git config --global alias.ll 'log --all --oneline --graph --decorate' ...
Git (und auch GitHub) hat kürzlich den Namen des Default-Branches von master
auf main geändert. Dies kann man in Git ebenfalls selbst einstellen:
git config --global init.defaultBranch <name>.
Anschauen kann man sich die Einstellungen in der Textdatei ~/.gitconfig
oder per Befehl git config --global -l.
Neues Repo anlegen
Wrap-Up
- Git: Versionsmanagement mit dezentralen Repositories
- Anlegen eines lokalen Repos mit
git init
- Clonen eines existierenden Repos mit
git clone <url>
Basics der Versionsverwaltung mit Git (lokale Repos)
TL;DR
Änderungen an Dateien (in der Workingcopy) werden mit git add zum "Staging" (Index) hinzugefügt.
Dies ist eine Art Sammelbereich für Änderungen, die mit dem nächsten Commit in das Repository
überführt werden. Neue (bisher nicht versionierte Dateien) müssen ebenfalls zunächst mit
git add zum Staging hinzugefügt werden.
Änderungen kann man mit git log betrachten, dabei erhält man u.a. eine Liste der Commits und der
jeweiligen Commmit-Messages.
Mit git diff kann man gezielt Änderungen zwischen Commits oder Branches betrachten.
Mit git tag kann man bestimmte Commits mit einem "Stempel" (zusätzlicher Name) versehen, um diese
leichter finden zu können.
Wichtig sind die Commit-Messages: Diese sollten eine kurze Zusammenfassung haben, die aktiv
formuliert wird (was ändert dieser Commit: "Formatiere den Java-Code entsprechend Style"; nicht aber
"Java-Code nach Style formatiert"). Falls der Kommentar länger sein soll, folgt eine Leerzeile auf
die erste Zeile (Zusammenfassung) und danach ein Block mit der längeren Erklärung.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Umgang mit Dateien: Hinzufügen zum und Löschen aus Repo
- (K3) Umgang mit Änderungen: Hinzufügen zum Staging und Commit
- (K3) Herausfinden von Unterschieden, Ansehen der Historie
- (K3) Ignorieren von Dateien und Ordnern
Versionsverwaltung mit Git: Typische Arbeitsschritte
-
Repository anlegen (oder clonen)
-
Dateien neu erstellen (und löschen, umbenennen, verschieben)
-
Änderungen einpflegen ("committen")
-
Änderungen und Logs betrachten
-
Änderungen rückgängig machen
-
Projektstand markieren ("taggen")
-
Entwicklungszweige anlegen ("branchen")
-
Entwicklungszweige zusammenführen ("mergen")
-
Änderungen verteilen (verteiltes Arbeiten, Workflows)
Dateien unter Versionskontrolle stellen

-
git add . (oder git add <file>)
=> Stellt alle Dateien (bzw. die Datei <file>)
im aktuellen Verzeichnis unter Versionskontrolle
-
git commit
=> Fügt die Dateien dem Repository hinzu
Abfrage mit git status
Änderungen einpflegen

- Abfrage mit:
git status
- "Staging" von modifizierten Dateien:
git add <file>
- Committen der Änderungen im Stage:
git commit
Anmerkung: Alternativ auch mit git commit -m "Kommentar", um das Öffnen
des Editors zu vermeiden ... geht einfach schneller ;)
Das "staging area" stellt eine Art Zwischenebene zwischen Working Copy und
Repository dar: Die Änderungen sind temporär "gesichert", aber noch nicht
endgültig im Repository eingepflegt ("committed").
Man kann den Stage dazu nutzen, um Änderungen an einzelnen Dateien zu sammeln
und diese dann (in einem Commit) gemeinsam einzuchecken.
Man kann den Stage in der Wirkung umgehen, indem man alle in der Working Copy
vorliegenden Änderungen per git commit -a -m "Kommentar" eincheckt. Der
Schalter "-a" nimmt alle vorliegenden Änderungen an bereits versionierten
Dateien, fügt diese dem Stage hinzu und führt dann den Commit durch. Das ist
das von SVN bekannte Verhalten. Achtung: Nicht versionierte Dateien bleiben
dabei außen vor!
Letzten Commit ergänzen
-
git commit --amend -m "Eigentlich wollte ich das so sagen"
Wenn keine Änderungen im Stage sind, wird so die letzte Commit-Message geändert.
-
git add <file>; git commit --amend
Damit können vergessene Änderungen an der Datei <file>
zusätzlich im letzten Commit aufgezeichnet werden.
In beiden Fällen ändert sich die Commit-ID!
Weitere Datei-Operationen: hinzufügen, umbenennen, löschen
- Neue (unversionierte) Dateien und Änderungen an versionierten Dateien zum Staging hinzufügen:
git add <file>
- Löschen von Dateien (Repo+Workingcopy):
git rm <file>
- Löschen von Dateien (nur Repo):
git rm --cached <file>
- Verschieben/Umbenennen:
git mv <fileAlt> <fileNeu>
Aus Sicht von Git sind zunächst alle Dateien "untracked", d.h. stehen nicht
unter Versionskontrolle.
Mit git add <file> (und git commit) werden Dateien in den Index (den
Staging-Bereich, d.h. nach dem Commit letztlich in das Repository) aufgenommen.
Danach stehen sie unter "Beobachtung" (Versionskontrolle). So lange, wie eine
Datei identisch zur Version im Repository ist, gilt sie als unverändert
("unmodified"). Eine Änderung führt entsprechend zum Zustand "modified", und
ein git add <file> speichert die Änderungen im Stage. Ein Commit überführt
die im Stage vorgemerkte Änderung in das Repo, d.h. die Datei gilt wieder
als "unmodified".
Wenn eine Datei nicht weiter versioniert werden soll, kann sie aus dem Repo
entfernt werden. Dies kann mit git rm <file> geschehen, wobei die Datei auch
aus der Workingcopy gelöscht wird. Wenn die Datei erhalten bleiben soll, aber
nicht versioniert werden soll (also als "untracked" markiert werden soll), dann
muss sie mit git rm --cached <file> aus der Versionskontrolle gelöscht werden.
Achtung: Die Datei ist dann nur ab dem aktuellen Commit gelöscht, d.h. frühere
Revisionen enthalten die Datei noch!
Wenn eine Datei umbenannt werden soll, geht das mit git mv <fileAlt> <fileNeu>.
Letztlich ist dies nur eine Abkürzung für die Folge git rm --cached <fileAlt>,
manuelles Umbenennen der Datei in der Workingcopy und git add <fileNeu>.
Commits betrachten
Änderungen und Logs betrachten
-
git diff [<file>]
Änderungen zwischen Workingcopy und letztem Commit (ohne Stage)
Das "staging area" wird beim Diff von Git behandelt, als wären die dort
hinzugefügten Änderungen bereits eingecheckt (genauer: als letzter Commit
im aktuellen Branch im Repo vorhanden).
D.h. wenn Änderungen in einer Datei mittels git add <datei> dem Stage
hinzugefügt wurden, zeigt git diff <datei> keine Änderungen an!
-
git diff commitA commitB
Änderungen zwischen Commits
-
Blame: git blame <file>
Wer hat was wann gemacht?
Dateien ignorieren: .gitignore
- Nicht alle Dateien gehören ins Repo:
- generierte Dateien:
.class
- temporäre Dateien
- Datei
.gitignore anlegen und committen
- Wirkt auch für Unterordner
- Inhalt: Reguläre Ausdrücke für zu ignorierende Dateien und Ordner
# Compiled source #
*.class
*.o
*.so
# Packages #
*.zip
# All directories and files in a directory #
bin/**/*
Zeitmaschine
-
Änderungen in Workingcopy rückgängig machen
- Änderungen nicht in Stage:
git checkout <file> oder git restore <file>
- Änderungen in Stage:
git reset HEAD <file> oder git restore --staged <file>
=> Hinweise von git status beachten!
-
Datei aus altem Stand holen:
git checkout <commit> <file>, odergit restore --source <commit> <file>
-
Commit verwerfen, Geschichte neu: git revert <commit>
Hinweis: In den neueren Versionen von Git ist der Befehl git restore hinzugekommen, mit
dem Änderungen rückgängig gemacht werden können. Der bisherige Befehl git checkout steht
immer noch zur Verfügung und bietet über git restore hinaus weitere Anwendungsmöglichkeiten.
- Stempel (Tag) vergeben:
git tag <tagname> <commit>
- Tags anzeigen:
git tag und git show <tagname>
Wann und wie committen?
Jeder Commit stellt einen Rücksetzpunkt dar!
Typische Regeln:
- Kleinere "Häppchen" einchecken: ein Feature oder Task
(das nennt man auch atomic commit: das kleinste Set an Änderungen, die
gemeinsam Sinn machen und die ggf. gemeinsam zurückgesetzt werden können)
- Logisch zusammenhängende Änderungen gemeinsam einchecken
- Projekt muss nach Commit compilierbar sein
- Projekt sollte nach Commit lauffähig sein
Ein Commit sollte in sich geschlossen sein, d.h. die kleinste Menge an Änderungen
enthalten, die gemeinsam einen Sinn ergeben und die (bei Bedarf) gemeinsam
zurückgesetzt oder verschoben werden können. Das nennt man auch atomic commit.
Wenn Sie versuchen, die Änderungen in Ihrem Commit zu beschreiben (siehe nächste Folie
"Commit-Messages"), dann werden Sie einen atomic commit mit einem kurzen Satz (natürlich
im Imperativ!) beschreiben können. Wenn Sie mehr Text brauchen, haben Sie wahrscheinlich
keinen atomic commit mehr vor sich.
Lesen Sie dazu auch How atomic Git commits dramatically increased my productivity - and will increase yours too.
Schreiben von Commit-Messages: WARUM?!
Schauen Sie sich einmal einen Screenshot eines git log --oneline 61e48f0..e2c8076
im Dungeon-CampusMinden/Dungeon an:

Nun stellen Sie sich vor, Sie sind auf der Suche nach Informationen, suchen einen
bestimmten Commit oder wollen eine bestimmte Änderung finden ...
Wenn man das genauer analysiert, dann stören bestimmte Dinge:
- Mischung aus Deutsch und Englisch
- "Vor-sich-hin-Murmeln": "Layer system 5"
- Teileweise werden Tags genutzt wie
[BUG], aber nicht durchgängig
- Mischung zwischen verschiedenen Formen: "Repo umbenennen", "Benenne Repo um", "Repo umbenannt"
- Unterschiedliche Groß- und Kleinschreibung
- Sehr unterschiedlich lange Zeilen/Kommentare
Das Beachten einheitlicher Regeln ist enorm wichtig!
Leider sagt sich das so leicht - in der Praxis macht man es dann
doch schnell wieder unsauber. Dennoch, auch im Dungeon-Repo gibt
es einen positiven Trend (git log --oneline 8039d6c..7f49e89):

Typische Regeln und Konventionen tauchen überall auf, beispielsweise
in [Chacon2014] oder bei Tim Pope (siehe nächstes Beispiel) oder bei
"How to Write a Git Commit Message".
Short (50 chars or less) summary of changes
More detailed explanatory text, if necessary. Wrap it to about
72 characters or so. In some contexts, the first line is treated
as the subject of an email and the rest of the text as the body.
The blank line separating the summary from the body is critical
(unless you omit the body entirely); tools like rebase can get
confused if you run the two together.
Further paragraphs come after blank lines.
- Bullet points are okay, too
- Typically a hyphen or asterisk is used for the bullet, preceded
by a single space, with blank lines in between, but conventions
vary here
Quelle: "A Note About Git Commit Messages" by Tim Pope on tbaggery.com
Denken Sie sich die Commit-Message als E-Mail an einen zukünftigen Entwickler,
der das in fünf Jahren liest!
Vom Aufbau her hat eine E-Mail auch eine Summary und dann den eigentlichen Inhalt ...
Erklären Sie das "WARUM" der Änderung! (Das "WER", "WAS", "WANN" wird bereits
automatisch von Git aufgezeichnet ...)
Wrap-Up
- Änderungen einpflegen zweistufig (
add, commit)
- Status der Workingcopy mit
status ansehen
- Logmeldungen mit
log ansehen
- Änderungen auf einem File mit
diff bzw. blame ansehen
- Projektstand markieren mit
tag
- Ignorieren von Dateien/Ordnern: Datei
.gitignore
Challenges
Versionierung 101
- Legen Sie ein Repository an.
- Fügen Sie Dateien dem Verzeichnis hinzu und stellen Sie einige davon
unter Versionskontrolle.
- Ändern Sie eine Datei und versionieren Sie die Änderung.
- Was ist der Unterschied zwischen "
git add .; git commit" und
"git commit -a"?
- Wie finden Sie heraus, welche Dateien geändert wurden?
- Entfernen Sie eine Datei aus der Versionskontrolle, aber nicht aus dem
Verzeichnis!
- Entfernen Sie eine Datei komplett (Versionskontrolle und Verzeichnis).
- Ändern Sie eine Datei und betrachten die Unterschiede zum letzten Commit.
- Fügen Sie eine geänderte Datei zum Index hinzu. Was erhalten Sie bei
git diff <datei>?
- Wie können Sie einen früheren Stand einer Datei wiederherstellen? Wie
finden Sie überhaupt den Stand?
- Legen Sie sich ein Java-Projekt in Ihrer IDE an an. Stellen Sie dieses
Projekt unter Git-Versionskontrolle. Führen Sie die vorigen Schritte mit
Ihrer IDE durch.
Interaktive Git-Tutorials: Schaffen Sie die Rätsel?
Git Branches: Features unabhängig entwickeln und mit Git verwalten
TL;DR
Die Commits in Git bauen aufeinander auf und bilden dabei eine verkettete "Liste". Diese "Liste" nennt man
auch Branch (Entwicklungszweig). Beim Initialisieren eines Repositories wird automatisch ein Default-Branch
angelegt, auf dem die Commits dann eingefügt werden.
Weitere Branches kann man mit git branch anlegen, und die Workingcopy kann mit git switch oder git checkout
auf einen anderen Branch umgeschaltet werden. Auf diese Weise kann man an mehreren Features parallel arbeiten,
ohne dass die Arbeiten sich gegenseitig stören.
Zum Mergen (Vereinigen) von Branches gibt es git merge. Dabei werden die Änderungen im angegebenen Branch in
den aktuell in der Workingcopy ausgecheckten Branch integriert und hier ggf. ein neuer Merge-Commit erzeugt. Falls
es in beiden Branches inkompatible Änderungen an der selben Stelle gab, entsteht beim Mergen ein Merge-Konflikt.
Dabei zeigt Git in den betroffenen Dateien jeweils an, welche Änderung aus welchem Branch stammt und man muss
diesen Konflikt durch Editieren der Stellen manuell beheben.
Mit git rebase kann die Wurzel eines Branches an eine andere Stelle verschoben werden. Dies wird später bei
Workflows eine Rolle spielen.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Erzeugen von Branches
- (K3) Mergen von Branches, Auflösen möglicher Konflikte
- (K3) Rebasen von Branches
Neues Feature entwickeln/ausprobieren
A---B---C master
- Bisher nur lineare Entwicklung: Commits bauen aufeinander auf (lineare Folge von Commits)
master ist der (Default-) Hauptentwicklungszweig
- Pointer auf letzten Commit
- Default-Name: "
master" (muss aber nicht so sein bzw. kann geändert werden)
Anmerkung: Git und auch Github haben den Namen für den Default-Branch von master
auf maingeändert. Der Name an sich ist aber für Git bedeutungslos und kann mittels
git config --global init.defaultBranch <name> geändert werden. In Github hat der
Default-Branch eine gewisse Bedeutung, beispielsweise ist der Default-Branch das
automatische Ziel beim Anlegen von Pull-Requests. In Github kann man den Default-Namen
global in den User-Einstellungen (Abschnitt "Repositories") und für jedes einzelne
Repository in den Repo-Einstellungen (Abschnitt "Branches") ändern.
Entwicklung des neuen Features soll stabilen master-Branch nicht beeinflussen
=> Eigenen Entwicklungszweig für die Entwicklung des Features anlegen:
- Neuen Branch erstellen:
git branch wuppie
- Neuen Branch auschecken:
git checkout wuppie oder git switch wuppie
Alternativ: git checkout -b wuppie oder git switch -c wuppie (neuer Branch und auschecken in einem Schritt)
A---B---C master, wuppie
Startpunkt: prinzipiell beliebig (jeder Commit in der Historie möglich).
Die gezeigten Beispiel zweigen den neuen Branch direkt vom aktuell ausgecheckten
Commit/Branch ab. Also aufpassen, was gerade in der Workingcopy los ist!
Alternativ nutzen Sie die Langform: git branch wuppie master (mit master als
Startpunkt; hier kann jeder beliebige Branch, Tag oder Commit genutzt werden).
Nach Anlegen des neuen Branches zeigen beide Pointer auf den selben Commit.
Anmerkung: In neueren Git-Versionen wurde der Befehl "switch" eingeführt,
mit dem Sie in der Workingcopy auf einen anderen Branch wechseln können. Der
bisherige Befehl "checkout" funktioniert aber weiterhin.
Arbeiten im Entwicklungszweig ...
D wuppie
/
A---B---C master
- Entwicklung des neuen Features erfolgt im eigenen Branch: beeinflusst den
stabilen
master-Branch nicht
- Wenn in der Workingcopy der Feature-Branch ausgecheckt ist, gehen die
Commits in den Feature-Branch; der
master bleibt auf dem alten Stand
- Wenn der
master ausgecheckt wäre, würden die Änderungen in den master
gehen, d.h. der master würde sich ab Commit C parallel zu wuppie
entwickeln
Problem: Fehler im ausgelieferten Produkt
D wuppie
/
A---B---C master
Fix für master nötig:
git checkout mastergit checkout -b fix- Änderungen in
fix vornehmen ...
Das führt zu dieser Situation:
D wuppie
/
A---B---C master
\
E fix
git checkout <branchname> holt den aktuellen Stand des jeweiligen
Branches in die Workingcopy. (Das geht in neueren Git-Versionen auch
mit git switch <branchname>.)
Man kann weitere Branches anlegen, d.h. hier im Beispiel ein neuer
Feature-Branch fix, der auf dem master basiert. Analog könnte man
auch Branches auf der Basis von wuppie anlegen ...
Fix ist stabil: Integration in master
D wuppie
/
A---B---C master
\
E fix
git checkout mastergit merge fix => fast forward von mastergit branch -d fix
Der letzte Schritt entfernt den Branch fix.
D wuppie
/
A---B---C---E master
-
Allgemein: git merge <branchname> führt die Änderungen im angegebenen Branch
<branchname> in den aktuell in der Workingcopy ausgecheckten Branch ein. Daraus
resultiert für den aktuell ausgecheckten Branch ein neuer Commit, der Branch
<branchname> bleibt dagegen auf seinem bisherigen Stand.
Beispiel:
- Die Workingcopy ist auf
A
git merge B führt A und B zusammen: B wird in A gemergt- Wichtig: Der Merge-Commit (sofern nötig) findet hierbei in
A statt!
In der Abbildung ist A der master und B der fix.
-
Nach dem Merge existieren beide Branches weiter (sofern sie nicht explizit
gelöscht werden)
-
Hier im Beispiel findet ein sogenannter "Fast forward" statt.
"Fast forward" ist ein günstiger Spezialfall beim Merge: Beide Branches
liegen in einer direkten Kette, d.h. der Zielbranch kann einfach
"weitergeschaltet" werden. Ein Merge-Commit ist in diesem Fall nicht
notwendig und wird auch nicht angelegt.
Feature weiter entwickeln ...
D---F wuppie
/
A---B---C---E master
git switch wuppie- Weitere Änderungen im Branch
wuppie ...
git switch <branchname> holt den aktuellen Stand des jeweiligen Branches in
die Workingcopy. Man kann also jederzeit in der Workingcopy die Branches wechseln
und entsprechend weiterarbeiten.
Hinweis: Während der neue git switch-Befehl nur Branches umschalten kann,
funktioniert git checkout sowohl mit Branchnamen und Dateinamen - damit kann
man also auch eine andere Version einer Datei in der Workingcopy "auschecken".
Falls gleiche Branch- und Dateinamen existieren, muss man für das Auschecken
einer Datei noch "--" nutzen: git checkout -- <dateiname>.
Feature ist stabil: Integration in master
D---F wuppie D---F wuppie
/ => / \
A---B---C---E master A---B---C---E---G master
git checkout mastergit merge wuppie => Kein fast forward möglich: Git sucht nach gemeinsamen Vorgänger
Hier im Beispiel ist der Standardfall beim Mergen dargestellt: Die beiden
Branches liegen nicht in einer direkten Kette von Commits, d.h. hier wurde
parallel weitergearbeitet.
Git sucht in diesem Fall nach dem gemeinsamen Vorgänger beider Branches und
führt die jeweiligen Änderungen (Differenzen) seit diesem Vorgänger in einem
Merge-Commit zusammen.
Im master entsteht ein neuer Commit, da kein fast forward beim
Zusammenführen der Branches möglich!
Anmerkung: git checkout wuppie; git merge master würde den master in den
wuppie mergen, d.h. der Merge-Commit wäre dann in wuppie.
Beachten Sie dabei die "Merge-Richtung":
- Die Workingcopy ist auf
A
git merge B führt A und B zusammen: B wird in A gemergt- Wichtig: Der Merge-Commit (sofern nötig) findet hierbei in
A statt!
In der Abbildung ist A der master und B der wuppie.
Achtung: Richtung beachten! git checkout A; git merge B führt beide Branches zusammen,
genauer: führt die Änderungen von B in A ein, d.h. der entsprechende Merge-Commit ist in A!
Konflikte beim Mergen
(Parallele) Änderungen an selber Stelle => Merge-Konflikte
$ git merge wuppie
Auto-merging hero.java
CONFLICT (content): Merge conflict in hero.java
Automatic merge failed; fix conflicts and then commit the result.
Git fügt Konflikt-Marker in die Datei ein:
<<<<<<< HEAD:hero.java
public void getActiveAnimation() {
return null;
=======
public Animation getActiveAnimation() {
return this.idleAnimation;
>>>>>>> wuppie:hero.java
- Der Teil mit
HEAD ist aus dem aktuellen Branch in der Workingcopy
- Der Teil aus dem zu mergenden Branch ist unter
wuppie notiert
- Das
======= trennt beide Bereiche
Merge-Konflikte auflösen
Manuelles Editieren nötig (Auflösung des Konflikts):
- Entfernen der Marker
- Hinzufügen der Datei zum Index
- Analog für restliche Dateien mit Konflikt
- Commit zum Abschließen des Merge-Vorgangs
Alternativ: Nutzung graphischer Oberflächen mittels git mergetool
Rebasen: Verschieben von Branches
D---F wuppie D---F wuppie
/ => / \
A---B---C---E master A---B---C---E---G master
Bisher haben wir Branches durch Mergen zusammengeführt. Dabei entsteht in der Regel ein extra
Merge-Commit (im Beispiel G), außer es handelt sich um ein fast forward. Außerdem erkennt
man in der Historie sehr gut, dass hier in einem separaten Branch gearbeitet wurde, der irgendwann
in den master gemergt wurde.
Leider wird dieses Vorgehen in großen Projekten recht schnell sehr unübersichtlich. Außerdem
werden Merges in der Regeln nur von besonders berechtigten Personen (Manager) durchgeführt, die im
Falle von Merge-Konflikten diese dann selbst auflösen müssten (ohne aber die fachliche Befähigung
zu haben). Hier greift man dann häufig zur Alternative Rebase. Dabei wird der Ursprung eines
Branches auf einen bestimmten Commit verschoben. Im Anschluss ist dann ein Merge mit fast forward,
also ohne die typischen rautenförmigen Ketten in der Historie und ohne extra Merge-Commit möglich.
Dies kann aber auch als Nachteil gesehen werden, da man in der Historie den früheren Branch nicht
mehr erkennt! Ein weiterer schwerwiegender Nachteil ist, dass alle Commits im verschobenen Branch
umgeschrieben werden und damit neue Commit-IDs bekommen. Das verursacht bei der Zusammenarbeit in
Projekten massive Probleme! Als Vorteil gilt, dass man mögliche Merge-Konflikte bereits beim Rebasen
auflösen muss, d.h. hier muss derjenige, der den Merge "beantragt", durch einen vorherigen Rebase den
konfliktfreien Merge sicherstellen. Mehr dazu in “Branching-Strategien”
und “Workflows”.
git rebase master wuppie
führt zu
D'---F' wuppie
/
A---B---C---E master
Nach dem Rebase von wuppie auf master sieht es so aus, als ob der Branch wuppie
eben erst vom master abgezweigt wurde. Damit ist dann ein fast forward Merge von wuppie
in den master möglich, d.h. es gibt keine Raute und auch keinen extra Merge-Commit (hier nicht
gezeigt).
Man beachte aber die Änderung der Commit-IDs von wuppie: Aus D wird D'! (Datum, Ersteller
und Message bleiben aber erhalten.)
Don't lose your HEAD
Wrap-Up
- Anlegen von Branches mit
git branch
- Umschalten der Workingcopy auf anderen Branch:
git checkout oder git switch
- Mergen von Branches und Auflösen von Konflikten:
git merge
- Verschieben von Branches mit
git rebase
Challenges
Branches und Merges
-
Legen Sie in Ihrem Projekt einen Branch an. Ändern Sie einige Dateien
und committen Sie die Änderungen. Checken Sie den Master-Branch aus und
mergen Sie die Änderungen. Was beobachten Sie?
-
Legen Sie einen weiteren Branch an. Ändern Sie einige Dateien und
committen Sie die Änderungen. Checken Sie den Master-Branch aus und
ändern Sie dort ebenfalls:
- Ändern Sie eine Datei an einer Stelle, die nicht bereits im Branch
modifiziert wurde.
- Ändern Sie eine Datei an einer Stelle, die bereits im Branch
manipuliert wurde.
Committen Sie die Änderungen.
Mergen Sie den Branch jetzt in den Master-Branch. Was beobachten Sie? Wie
lösen Sie Konflikte auf?
Interaktive Git-Tutorials: Schaffen Sie die Rätsel?
Branching-Strategien mit Git
TL;DR
Das Erstellen und Mergen von Branches ist in Git besonders einfach. Dies kann man sich in der Entwicklung zunutze machen
und die einzelnen Features unabhängig voneinander in eigenen Hilfs-Branches ausarbeiten.
Es haben sich zwei grundlegende Modelle etabliert: "Git-Flow" und "GitHub Flow".
In Git-Flow gibt es ein umfangreiches Konzept mit verschiedenen Branches für feste Aufgaben, welches sich besonders
gut für Entwicklungmodelle mit festen Releases eignet. Es gibt zwei langlaufende Branches: master enthält den stabilen
veröffentlichten Stand, in develop werden die Ergebnisse der Entwicklung gesammelt. Features werden in kleinen Feature-Branches
entwickelt, die von develop abzweigen und dort wieder hineinmünden. Für Releases wird von develop ein eigener Release-Branch
angelegt und nach Finalisierung in den master und in develop gemergt. Fixes werden vom master abgezweigt, und wieder
in den master und auch nach develop integriert. Dadurch stehen auf dem master immer die stabilen Release-Stände zur
Verfügung, und im develop sammeln sich die Entwicklungsergebnisse.
Der GitHub Flow basiert auf einem deutlich schlankeren Konzept und passt gut für die kontinuierliche Entwicklung ohne
echte Releases. Hier hat man auch wieder einen master als langlaufenden Branch, der die stabilen Release-Stände enthält.
Vom master zweigen direkt die kleinen Feature-Branches ab und werden auch wieder direkt in den master integriert.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Einsatz von Themenbranches in der Entwicklung
- (K3) Git-Flow-Modell anwenden
- (K3) GitHub Flow-Modell anwenden
Nutzung von Git in Projekten: Verteiltes Git (und Workflows)

Git ermöglicht ein einfaches und schnelles Branchen. Dies kann man mit
entsprechenden Branching-Strategien sinnvoll für die SW-Entwicklung einsetzen.
Im Folgenden sollen also die Frage betrachtet werden: Wie setze ich Branches sinnvoll ein?
Umgang mit Branches: Themen-Branches
I---J---K wuppieV1
/
D---F wuppie
/
A---B---C---E master
\
G---H test
Branchen ist in Git sehr einfach und schnell. Deshalb wird (gerade auch im Vergleich mit
SVN) gern und viel gebrancht.
Ein häufiges anzutreffendes Modell ist dabei die Nutzung von
Themen-Branches: Man hat einen Hauptzweig (master). Wann immer eine neue
Idee oder ein Baustein unabhängig entwickelt werden soll/kann, wird ein
entsprechender Themen-Branch aufgemacht. Dabei handelt es sich normalerweise
um kleine Einheiten!
Themenbranches haben in der Regel eine kurze Lebensdauer: Wenn die Entwicklung
abgeschlossen ist, wird die Idee bzw. der Baustein in den Hauptzweig integriert
und der Themenbranch gelöscht.
Umgang mit Branches: Langlaufende Branches
A---B---D master
\
C---E---I develop
\
F---G---H topic
Häufig findet man in (größeren) Projekten Branches, die über die gesamte
Lebensdauer des Projekts existieren, sogenannte "langlaufende Branches".
Normalerweise gibt es einen Branch, in dem stets der stabile Stand des Projekts
enthalten ist. Dies ist häufig der master. In diesem Branch gibt es nur
sehr wenige Commits: normalerweise nur Merges aus dem develop-Branch (etwa
bei Fertigstellung einer Release-Version) und ggf. Fehlerbehebungen.
Die aktive Entwicklung findet in einem separaten Branch statt: develop. Hier
nutzt man zusätzlich Themen-Branches für die Entwicklung einzelner Features,
die nach Fertigstellung in den develop gemergt werden.
Kleinere Projekte kommen meist mit den zwei langlaufenden Branches in der
obigen Darstellung aus. Bei größeren Projekten finden sich häufig noch etliche
weitere langlaufende Branches, beispielsweise "Proposed Updates" etc. beim
Linux-Kernel.
- Vorteile:
- Mehr Struktur im Projekt durch in ihrer Semantik wohldefinierte
Branches
- Durch weniger Commits pro Branch lässt sich die Historie leichter
verfolgen (u.a. auch aus bestimmter Rollen-Perspektive: Entwickler,
Manager, ...)
- Nachteile: Bestimmte "ausgezeichnete" Branches; zusätzliche Regeln zum
Umgang mit diesen beachten
Komplexe Branching-Strategie: Git-Flow
A---B---------------------G---J1 master
\ / \ /
\ / X fix
\ / \
C-------------F----I--J2 develop
\ / \ /
\ / H1 featureB
\ /
D1----D2 featureA
\
E1---E2---E3---E4---E5 featureC
Das Git-Flow-Modell von Vincent Driessen
(nvie.com/posts/a-successful-git-branching-model)
zeigt einen in der Praxis überaus bewährten Umgang mit Branches. Lesen Sie an
der angegebenen Stelle nach, besser kann man die Nutzung dieses eleganten
Modells eigentlich nicht erklären :-)
Git-Flow: Hauptzweige master und develop
A---B-------E---------------J master
\ / /
C---D---F---G---H---I---K develop
Bei Git-Flow gibt es zwei langlaufende Branches: Den master, der immer den stabilen
Stand enthält und in den nie ein direkter Commit gemacht wird, sowie den develop,
wo letztlich (ggf. über Themenbranches) die eigentliche Entwicklung stattfindet.
Änderungen werden zunächst im develop erstellt und getestet. Wenn die Features
stabil sind, erfolgt ein Merge von develop in den master. Hier kann noch der
Umweg über einen release-Branch genommen werden: Als "Feature-Freeze" wird vom
develop ein release-Branch abgezweigt. Darin wird das Release dann aufpoliert,
d.h. es erfolgen nur noch kleinere Korrekturen und Änderungen, aber keine echte
Entwicklungsarbeit mehr. Nach Fertigstellung wird der release dann sowohl in den
master als auch develop gemergt.
Git-Flow: Weitere Branches als Themen-Branches
A---B---------------------I-------------K master
\ / /
C------------F----H-------------J---L develop
\ / \ / /
\ / G1 featureB /
\ / /
D1---D2 featureA /
\ /
E1---E2---E3---E4---E5 featureC
Für die Entwicklung eigenständiger Features bietet es sich auch im
Git-Flow an, vom develop entsprechende Themenbranches abzuzweigen
und darin jeweils isoliert die Features zu entwickeln. Wenn diese
Arbeiten eine gewisse Reife haben, werden die Featurebranches in den
develop integriert.
Git-Flow: Merging-Detail
---C--------E develop
\ / git merge --no-ff
D1---D2 featureA
vs.
---C---D1---D2 develop git merge
Wenn beim Mergen ein "fast forward" möglich ist, würde Git beim Mergen
eines (Feature-) Branches in den develop (oder allgemein in einen anderen
Branch) keinen separaten Commit erzeugen (Situation rechts in der Abbildung).
Damit erscheint der develop-Branch wie eine lineare Folge von Commits. In
manchen Projekten wird dies bevorzugt, weil die Historie sehr übersichtlich
aussieht.
Allerdings verliert man die Information, dass hier ein Feature entwickelt wurde
und wann es in den develop integriert wurde (linke Seite in obiger Abbildung).
Häufig wird deshalb ein extra Merge-Commit mit git merge --no-ff <branch>
(extra Schalter "--no-ff") erzwungen, obwohl ein "fast forward" möglich wäre.
Anmerkung: Man kann natürlich auch über Konventionen in den Commit-Kommentaren
eine gewisse Übersichtlichkeit erzwingen. Beispielsweise könnte man vereinbaren,
dass alle Commit-Kommentare zu einem Feature "A" mit "feature a:" starten müssen.
Git-Flow: Umgang mit Fehlerbehebung
A---B---D--------F1 master
\ \ /
\ E1---E2 fix
\ \
C1-------F2 develop
Wenn im stabilen Branch (also dem master) ein Problem bekannt wird,
darf man es nicht einfach im master fixen. Stattdessen wird ein extra
Branch vom master abgezweigt, in dem der Fix entwickelt wird. Nach
Fertigstellung wird dieser Branch sowohl in den master als auch den
develop gemergt, damit auch im Entwicklungszweig der Fehler behoben ist.
Dadurch entspricht jeder Commit im master einem Release.
Vereinfachte Braching-Strategie: GitHub Flow
A---B---C----D-----------E master
\ \ / /
\ ta1 topicA /
\ /
tb1---tb2---tb3 topicB
Github verfolgt eine deutlich vereinfachte Strategie: "GitHub Flow"
(vgl. "GitHub Flow" (S. Chacon)
bzw. "GitHub flow" (GitHub, Inc.)).
Hier ist der stabile Stand ebenfalls immer im master. Features werden ebenso
wie im Git-Flow-Modell in eigenen Feature-Branches entwickelt.
Allerdings zweigen Feature-Branches immer direkt vom master ab und werden nach
dem Test auch immer dort wieder direkt integriert (es gibt also keine weiteren
langlaufenden Branches wie develop oder release).
In der obigen Abbildung ist zu sehen, dass für die Entwicklung eines Features ein
entsprechender Themenbranch vom master abgezweigt wird. Darin erfolgt dann die
Entwicklung des Features, d.h. mehrere Commits. Das Mergen des Features in den
master erfolgt dann aber nicht lokal, sondern mit einem "Pull-Request" auf dem
Server: Sobald man im Feature-Branch einen "diskussionswürdigen" Stand hat, wird ein
Pull-Request (PR) über die Weboberfläche aufgemacht (streng genommen gehört
dies in die Kategorie “Zusammenarbeit” bzw. “Workflows”;
außerdem gehört ein PR nicht zu Git selbst, sondern zum Tooling von Github). In
einem PR können andere Entwickler den Code kommentieren und ergänzen. Jeder weitere
Commit auf dem Themenbranch wird ebenfalls Bestandteil des Pull-Requests. Parallel
laufen ggf. automatisierte Tests etc. und durch das Akzeptieren des PR in der
Weboberfläche erfolgt schließlich der Merge des Feature-Branches in den master.
Diskussion: Git-Flow vs. GitHub Flow
In der Praxis zeigt sich, dass das Git-Flow-Modell besonders gut geeignet ist,
wenn man tatsächlich so etwas wie "Releases" hat, die zudem nicht zu häufig
auftreten.
Das GitHub-Flow-Vorgehen bietet sich an, wenn man entweder keine Releases hat
oder diese sehr häufig erfolgen (typisch bei agiler Vorgehensweise). Zudem
vermeidet man so, dass die Feature-Branches zu lange laufen, womit normalerweise
die Wahrscheinlichkeit von Merge-Konflikten stark steigt.
Achtung: Da die Feature-Branches direkt in den master, also den stabilen
Produktionscode gemergt werden, ist es hier besonders wichtig, vor dem Merge
entsprechende Tests durchzuführen und den Merge erst zu machen, wenn alle Tests
"grün" sind.
Hier ein paar Einstiegsseiten für die Diskussion, die teilweise sehr erbittert
(und mit ideologischen Zügen) geführt wird (erinnert an die Diskussionen, welche
Linux-Distribution die bessere sei):
Wrap-Up
- Einsatz von Themenbranches für die Entwicklung
- Unterschiedliche Modelle:
- Git-Flow: umfangreiches Konzept, gut für Entwicklung mit festen Releases
- GitHub Flow: deutlich schlankeres Konzept, passend für kontinuierliche Entwicklung ohne echte Releases
Quellen
- [AtlassianGit] Become a git guru.
Atlassian Pty Ltd, 2022. - [Chacon2014] Pro Git
Chacon, S. und Straub, B., Apress, 2014. ISBN 978-1-4842-0077-3.
Kapitel 3 - [GitCheatSheet] Git Cheat Sheets
Github Inc., 2022. - [GitFlow] Git-Flow: A successful Git branching model
Driessen, V., 2010. - [GitHubFlow] GitHub Flow
Chacon, S., 2013. - [GitHubFlowGH] GitHub flow
GitHub Inc., 2022.
Arbeiten mit Git Remotes (dezentrale Repos)
TL;DR
Eine der Stärken von Git ist das Arbeiten mit verteilten Repositories. Zu jeder Workingcopy gehört
eine Kopie des Repositories, wodurch jederzeit alle Informationen einsehbar sind und auch offline
gearbeitet werden kann. Allerdings muss man für die Zusammenarbeit mit anderen Entwicklern die lokalen
Repos mit den "entfernten" Repos (auf dem Server oder anderen Entwicklungsrechnern) synchronisieren.
Beim Klonen eines Repositories mit git clone <url> wird das fremde Repo mit dem Namen origin
im lokalen Repo festgehalten. Dieser Name wird auch als Präfix für die Branches in diesem Repo genutzt,
d.h. die Branches im Remote-Repo tauchen als origin/<branch> im lokalen Repo auf. Diese Remote-Branches
kann man nicht direkt bearbeiten, sondern man muss diese Remote-Branches in einem lokalen Branch auschecken
und dann darin weiterarbeiten. Es können beliebig viele weitere Remotes dem eigenen Repository hinzugefügt
werden.
Änderungen aus einem Remote-Repo können mit git fetch <remote> in das lokale Repo geholt werden.
Dies aktualisiert nur die Remote-Branches <remote>/<branch>! Die Änderungen können anschließend
mit git merge <remote>/<branch> in den aktuell in der Workingcopy ausgecheckten Branch gemergt werden.
(Anmerkung: Wenn mehrere Personen an einem Branch arbeiten, will man die eigenen Arbeiten in dem Branch
vermutlich eher auf den aktuellen Stand des Remote rebasen statt mergen!) Eigene Änderungen können
mit git push <remote> <branch> in das Remote-Repo geschoben werden.
Um den Umgang mit den Remote-Branches und den davon abgeleiteten lokalen Branches zu vereinfachen,
gibt es das Konzept der "Tracking Branches". Dabei "folgt" ein lokaler Branch einem Remote-Branch.
Ein einfaches git pull oder git push holt dann Änderungen aus dem Remote-Branch in den ausgecheckten
lokalen Branch bzw. schiebt Änderungen im lokalen Branch in den Remote-Branch.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Erzeugen eines Clones von fremden Git-Repositories
- (K3) Holen der Änderungen vom fremden Repo
- (K3) Aktualisierung der lokalen Branches
- (K3) Pushen der lokalen Änderungen ins fremde Repo
- (K3) Anlegen von lokalen Branches vs. Anlegen von entfernten Branches
- (K3) Anlegen eines Tracking Branches zum Vereinfachen der Arbeit
Nutzung von Git in Projekten: Verteiltes Git (und Workflows)

Git ermöglicht eine einfaches Zusammenarbeit in verteilten Teams. Nachdem wir die verschiedenen
Branching-Strategien betrachtet haben, soll im Folgenden die Frage betrachtet werden: Wie arbeite
ich sinnvoll über Git mit anderen Kollegen und Teams zusammen? Welche Modelle haben sich etabliert?
Clonen kann sich lohnen ...
https://github.com/Programmiermethoden-CampusMinden/PM-Lecture
---C---D---E master
=> git clone https://github.com/Programmiermethoden-CampusMinden/PM-Lecture
./PM-Lecture/ (lokaler Rechner)
---C---D---E master
^origin/master
Git-Repository mit der URL <URL-Repo> in lokalen Ordner <directory> auschecken:
git clone <URL-Repo> [<directory>]- Workingcopy ist automatisch über den Namen
origin mit dem remote Repo auf
dem Server verbunden
- Lokaler Branch
master ist mit dem remote Branch origin/master verbunden
("Tracking Branch", s.u.), der den Stand des master-Branches auf dem
Server spiegelt
Für die URL sind verschiedene Protokolle möglich, beispielsweise:
- "
file://" für über das Dateisystem erreichbare Repositories (ohne Server)
- "
https://" für Repo auf einem Server: Authentifikation mit Username
und Passwort (!)
- "
git@" für Repo auf einem Server: Authentifikation mit SSH-Key (diese
Variante wird im Praktikum im Zusammenspiel mit dem Gitlab-Server im
SW-Labor verwendet)
Eigener und entfernter master entwickeln sich weiter ...
https://github.com/Programmiermethoden-CampusMinden/PM-Lecture
---C---D---E---F---G master
./PM-Lecture/ (lokaler Rechner)
---C---D---E---H master
^origin/master
Nach dem Auschecken liegen (in diesem Beispiel) drei master-Branches vor:
- Der
master auf dem Server,
- der lokale
master, und
- die lokale Referenz auf den
master-Branch auf dem Server: origin/master.
Der lokale master ist ein normaler Branch und kann durch Commits verändert
werden.
Der master auf dem Server kann sich ebenfalls ändern, beispielsweise weil
jemand anderes seine lokalen Änderungen mit dem Server abgeglichen hat
(git push, s.u.).
Der Branch origin/master lässt sich nicht direkt verändern! Das ist lediglich
eine lokale Referenz auf den master-Branch auf dem Server und zeigt an,
welchen Stand man bei der letzten Synchronisierung hatte. D.h. erst mit dem
nächsten Abgleich wird sich dieser Branch ändern (sofern sich der entsprechende
Branch auf dem Server verändert hat).
Anmerkung: Dies gilt analog für alle anderen Branches. Allerdings wird
nur der origin/master beim Clonen automatisch als lokaler Branch ausgecheckt.
Zur Abbildung:
Während man lokal arbeitet (Commit H auf dem lokalen master), kann es passieren,
dass sich auch das remote Repo ändert. Im Beispiel wurden dort die beiden Commits
F und G angelegt (durch git push, s.u.).
Wichtig: Da in der Zwischenzeit das lokale Repo nicht mit dem Server abgeglichen
wurde, zeigt der remote Branch origin/master immer noch auf den Commit
E!
Änderungen im Remote holen und Branches zusammenführen
https://github.com/Programmiermethoden-CampusMinden/PM-Lecture
---C---D---E---F---G master
=> git fetch origin
./PM-Lecture/ (lokaler Rechner)
---C---D---E---H master
\
F---G origin/master
Änderungen auf dem Server mit dem eigenen Repo abgleichen
Mit git fetch origin alle Änderungen holen
- Alle remote Branches werden aktualisiert und entsprechen den jeweiligen
Branches auf dem Server: Im Beispiel zeigt jetzt
origin/master ebenso
wie der master auf dem Server auf den Commit G.
- Neue Branches auf dem Server werden ebenfalls "geholt", d.h. sie liegen
nach dem Fetch als entsprechende remote Branches vor
- Auf dem Server gelöschte Branches werden nicht automatisch lokal gelöscht;
dies kann man mit
git fetch --prune origin automatisch erreichen
Wichtig: Es werden nur die remote Branches aktualisiert, nicht die lokalen Branches!
master-Branch nach "git fetch origin" zusammenführen
- Mit
git checkout master Workingcopy auf eigenen master umstellen
- Mit
git merge origin/master Änderungen am origin/master in eigenen master mergen
- Mit
git push origin master eigene Änderungen ins remote Repo pushen
https://github.com/Programmiermethoden-CampusMinden/PM-Lecture
---C---D---E---H---I master
\ /
F---G
./PM-Lecture/ (lokaler Rechner)
---C---D---E---H---I master
\ /^origin/master
F---G
Anmerkung: Schritt (2) kann man auch per git pull origin master erledigen ... Ein pull
fasst fetch und merge zusammen (s.u.).
Anmerkung Statt dem merge in Schritt (2) kann man auch den lokalen master auf den
aktualisierten origin/master rebasen und vermeidet damit die "Raute". Der pull kann
mit der Option "--rebase" auf "rebase" umgestellt werden (per Default wird bei pull
ein "merge" ausgeführt).
Auf dem Server ist nur ein fast forward merge möglich
Sie können Ihre Änderungen in Ihrem lokalen master auch direkt in das remote Repo
pushen, solange auf dem Server ein fast forward merge möglich ist.
Wenn aber (wie in der Abbildung) der lokale und der remote master divergieren,
müssen Sie den Merge wie beschrieben lokal durchführen (fetch/merge oder pull)
und das Ergebnis wieder in das remote Repo pushen (dann ist ja wieder ein
fast forward merge möglich, es sei denn, jemand hat den remote master in der
Zwischenzeit weiter geschoben - dann muss die Aktualisierung erneut durchgeführt
werden).
Branches und Remotes
Zusammenfassung: Arbeiten mit Remotes
-
Änderungen vom Server holen: git fetch <remote>
=> Holt alle Änderungen vom Repo <remote> ins eigene Repo
(Workingcopy bleibt unangetastet!)
-
Aktuellen lokalen Branch auffrischen: git merge <remote>/<branch>
(oder alternativ git pull <remote> <branch>)
-
Eigene Änderungen hochladen: git push <remote> <branch>
Anmerkung: push geht nur, wenn
- Ziel ein "bare"-Repository ist, und
- keine Konflikte entstehen
=> im remote Repo nur "fast forward"-Merge möglich
=> bei Konflikten erst fetch und merge, danach push
Anmerkung: Ein "bare"-Repository enthält keine Workingcopy, sondern nur
das Repo an sich. Die ist bei Repos, die Sie auf einem Server wie Gitlab oder
Github anlegen, automatisch der Fall. Sie können aber auch lokal ein solches
"bare"-Repo anlegen, indem Sie beim Initialisieren den Schalter --bare
mitgeben: git init --bare ...
Beispiel
git fetch origin # alle Änderungen vom Server holen
git checkout master # auf lokalen Master umschalten
git merge origin/master # lokalen Master aktualisieren
... # Herumspielen am lokalen Master
git push origin master # lokalen Master auf Server schicken
Vereinfachung: Tracking Branches
Vorsicht: pull und push beziehen sich nur auf ausgecheckten Tracking Branch
Einrichten von Tracking Branches
-
git clone: lokaler master trackt automatisch origin/master
-
Remote Branch als Tracking Branch einrichten:
- Änderungen aus remote Repo holen:
git fetch <remote>
- Tracking Branch anlegen:
git checkout -t <remote>/<branch>
(=> Option -t richtet den remote Branch als Tracking Branch ein)
-
Lokalen neuen Branch ins remote Repo schicken und als Tracking Branch einrichten:
- Lokalen Branch erzeugen:
git checkout -b <branch>
- Lokalen Branch ins Repo schicken:
git push -u <remote> <branch>
(=> Option -u richtet den lokalen Branch als Tracking Branch ein)
Hinzufügen eines (weiteren) Remote Repository

Sie können einem Repo beliebig viele Remotes hinzufügen:
git remote add <name> <url>
Beispiel: git remote add andi git@github.com:andi/repo.git
- Remote
origin wird bei clone automatisch angelegt
- Ansehen der Remotes mit
git remote -v
fetch, push und pull jeweils über den vergebenen Namen
Beispiel: git fetch andi oder git push origin master
Wrap-Up
Challenges
Interaktive Git-Tutorials: Schaffen Sie die Rätsel?
Zusammenarbeit: Git-Workflows und Merge-/Pull-Requests
TL;DR
Git erlaubt unterschiedliche Formen der Zusammenarbeit.
Bei kleinen Teams kann man einen einfachen zentralen Ansatz einsetzen. Dabei gibt es ein zentrales
Repo auf dem Server, und alle Team-Mitglieder dürfen direkt in dieses Repo pushen. Hier muss man
sich gut absprechen und ein vernünftiges Branching-Schema ist besonders wichtig.
In größeren Projekten gibt es oft ein zentrales öffentliches Repo, wo aber nur wenige Personen
Schreibrechte haben. Hier forkt man sich dieses Repo, erstellt also eine öffentliche Kopie auf dem
Server. Diese Kopie klont man lokal und arbeitet hier und pusht die Änderungen in den eigenen öffentlich
sichtbaren Fork. Um die Änderungen ins Projekt-Repo integrieren zu lassen, wird auf dem Server ein
sogenannter Merge-Request (Gitlab) bzw. Pull-Request (GitHub) erstellt. Dies erlaubt zusätzlich ein
Review und eine Diskussion direkt am Code. Damit man die Änderungen im Hauptprojekt in den eigenen
Fork bekommt, trägt man das Hauptprojekt als weiteres Remote in die Workingcopy ein und aktualisiert
regelmäßig die Hauptbranches, von denen dann auch die eigenen Feature-Branches ausgehen sollten.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Git-Workflows für die Zusammenarbeit
- (K2) Unterschied zwischen einem Pull/Merge und einem Pull/Rebase
- (K2) Welche Commits werden Bestandteil eines Merge-Requests (und warum)
- (K3) Einsatz des zentralisierten Workflows
- (K3) Einsatz des einfachen verteilten Workflows mit unterschiedlichen Repos
- (K3) Aktualisieren Ihres Clones und Ihres Forks mit Änderungen aus dem blessed Repo
- (K3) Erstellen von Beiträgen zu einem Projekt über Merge-Requests
- (K3) Aktualisierung von Merge-Requests
- (K3) Diskussion über den Code in Merge-Requests
Nutzung von Git in Projekten: Verteiltes Git (und Workflows)

Git ermöglicht ein einfaches und schnelles Branchen. Dies kann man mit
entsprechenden Branching-Strategien sinnvoll für die SW-Entwicklung einsetzen.
Auf der anderen Seite ermöglicht Git ein sehr einfaches verteiltes Arbeiten.
Auch hier ergeben sich verschiedene Workflows, wie man mit anderen Entwicklern
an einem Projekt arbeiten will/kann.
Im Folgenden sollen also die Frage betrachtet werden: Wie gestalte ich die Zusammenarbeit?
Antwort: Workflows mit Git ...
Zusammenarbeit: Zentraler Workflow mit Git (analog zu SVN)

In kleinen Projektgruppen wie beispielsweise Ihrer Arbeitsgruppe wird häufig
ein einfacher zentralisierter Workflow bei der Versionsverwaltung genutzt. Im
Mittelpunkt steht dabei ein zentrales Repository, auf dem alle Teammitglieder
gleichberechtigt und direkt pushen dürfen.
-
Vorteile:
- Einfachstes denkbares Modell
- Ein gemeinsames Repo (wie bei SVN)
- Alle haben Schreibzugriff auf ein gemeinsames Repo
-
Nachteile:
- Definition und Umsetzung von Rollen mit bestimmten Rechten ("Manager",
"Entwickler", "Gast-Entwickler", ...) schwierig bis unmöglich
(das ist kein Git-Thema, sondern hängt von der Unterstützung durch den
Anbieter des Servers ab)
- Jeder darf überall pushen: Enge und direkte Abstimmung nötig
- Modell funktioniert meist nur in sehr kleinen Teams (2..3 Personen)
Zusammenarbeit: Einfacher verteilter Workflow mit Git

In großen und/oder öffentlichen Projekten wird üblicherweise ein Workflow
eingesetzt, der auf den Möglichkeiten von verteilten Git-Repositories basiert.
Dabei wird zwischen verschiedenen Rollen ("Integrationsmanager", "Entwickler")
unterschieden.
Sie finden dieses Vorgehen beispielsweise beim Linux-Kernel und auch häufig bei
Projekten auf Github.
Den hier gezeigten Zusammenhang kann man auf weitere Ebenen verteilen, vgl. den
im Linux-Kernel gelebten "Dictator and Lieutenants Workflow" (siehe Literatur).
Hinweis: Hier wird nur die Zusammenarbeit im verteilten Team dargestellt. Dazu
kommt noch das Arbeiten mit verschiedenen Branches!
Anmerkung: In der Workingcopy wird das eigene (öffentliche) Repo oft als origin
und das geschützte ("blessed") Master-Repo als upstream referenziert.
Anmerkungen zum Forken
Sie könnten auch das Original-Repo direkt clonen. Allerdings würden dann die
push dort aufschlagen, was in der Regel nicht erwünscht ist (und auch nicht
erlaubt ist).
Deshalb forkt man das Original-Repo auf dem Server, d.h. auf dem Server wird
eine Kopie des Original-Repos im eigenen Namespace angelegt. Auf diese Kopie
hat man dann uneingeschränkten Zugriff.
Anmerkungen zu den Namen für die Remotes: origin und upstream
Üblicherweise checkt man die Kopie lokal aus (d.h. erzeugt einen Clone).
In der Workingcopy verweist dann origin auf die Kopie. Um Änderungen am
Original-Repo zu erhalten, fügt man dieses unter dem Namen upstream als
weiteres Remote-Repo hinzu. Dies ist eine nützliche Konvention.
Um Änderungen aus dem Original-Repo in den eigenen Fork (und die Workingcopy)
zu bringen, führt man dann einfach folgendes aus (im Beispiel für den master):
$ git checkout master # Workingcopy auf master
$ git pull upstream master # Aktualisiere lokalen master mit master aus Original-Repo
$ git push origin master # Pushe lokalen master in den Fork
Feature-Branches aktualisieren: Mergen mit master vs. Rebase auf master
Im Netz finden sich häufig Anleitungen, wonach man Änderungen im master
mit einem Merge in den Feature-Branch holt, also sinngemäß:
$ git checkout master # Workingcopy auf master
$ git pull upstream master # Aktualisiere lokalen master mit master aus Vorgabe-Repo
$ git checkout feature # Workingcopy auf feature
$ git merge master # Aktualisiere feature: Merge master in feature
$ git push origin feature # Push aktuellen feature ins Team-Repo
Das funktioniert rein technisch betrachtet.
Allerdings spielt in den meisten Git-Projekten der master üblicherweise eine besondere Rolle
(vgl. Branching-Strategien) und ist
üblicherweise stets das Ziel eines Merge, aber nie die Quelle! D.h. per Konvention geht der
Fluß von Änderungen stets in den master (und nicht heraus).
Wenn man sich nicht an diese Konvention hält, hat man später möglicherweise Probleme, die
Merge-Historie zu verstehen (welche Änderung kam von woher)!
Um die Änderungen im master in einen Feature-Branch zu bekommen, sollte deshalb ein Rebase
(des Feature-Branches auf den master) vor einem Merge (des master in den Feature-Branch)
bevorzugt werden.
Merk-Regel: Merge niemals nie den master in Feature-Branches!
Achtung: Ein Rebase bei veröffentlichten Branches ist problematisch, da Dritte auf diesem
Branch arbeiten könnten und entsprechend auf die Commit-IDs angewiesen sind. Nach einem Rebase
stimmen diese Commit-IDs nicht mehr, was normalerweise mindestens zu Verärgerung führt ... Die
Dritten müssten ihre Arbeit dann auf den neuen Feature-Branch (d.h. den Feature-Branch nach
dessen Rebase) rebasen ... vgl. auch "The Perils of Rebasing" in Abschnitt "3.6 Rebasing" in
[Chacon2014].
Mögliches Szenario im Praktikum
Im Praktikum haben Sie das Vorgabe-Repo. Dieses könnten Sie als upstream in Ihre lokale
Workingcopy einbinden.
Mit Ihrem Team leben Sie vermutlich einen zentralen Workflow, d.h. Sie binden Ihr gemeinsames
Repo als origin in Ihre lokale Workingcopy ein.
Dann müssen Sie den lokalen master aus beiden Remotes aktualisieren. Zusätzlich
wollen Sie Ihren aktuellen Themenbranch auf den aktuellen master rebasen.
$ git checkout master # Workingcopy auf master
$ git pull upstream master # Aktualisiere lokalen master mit master aus Vorgabe-Repo
$ git pull origin master # Aktualisiere lokalen master mit master aus Team-Repo
$ git push origin master # Pushe lokalen master in das Team-Repo zurück
$ git rebase master feature # Rebase feature auf den aktuellen lokalen master
$ git push -f origin feature # Push aktuellen feature ins Team-Repo ("-f" wg. geänderter IDs durch rebase)
Anmerkung: Dabei können in Ihrem master die unschönen "Rauten" entstehen. Wenn
Sie das vermeiden wollen, tauschen Sie den zweiten und den dritten Schritt und führen
den Pull gegen den Upstream-master als pull --rebase durch. Dann müssen Sie Ihren
lokalen master allerdings auch force-pushen in Ihr Team-Repo und die anderen
Team-Mitglieder sollten darüber informiert werden, dass sich der master auf
inkompatible Weise geändert hat ...
Kommunikation: Merge- bzw. Pull-Requests
Mergen kann man auf der Konsole (oder in der IDE) und anschließend die (neuen) Branches
auf den Server pushen.
Die verschiedenen Git-Server erlauben ebenfalls ein GUI-gestütztes Mergen von Branches:
"Merge-Requests" (MR, Gitlab) bzw. "Pull-Requests" (PR, Github). Das hat gegenüber
dem lokalen Mergen wichtige Vorteile: Andere Entwickler sehen den beabsichtigten Merge
(frühzeitig) und können direkt den Code kommentieren und die vorgeschlagenen Änderungen
diskutieren, aber auch allgemeine Kommentare abgeben.
Falls möglich, sollte man einen MR/PR immer dem Entwickler zuweisen, der sich weiter
um diesen MR/PR kümmern wird (also zunächst ist man das erstmal selbst). Zusätzlich
kann man einen Reviewer bestimmen, d.h. wer soll sich den Code ansehen.
Hier ein Screenshot der Änderungsansicht unseres Gitlab-Servers (SW-Labor):

Nachfolgend für den selben MR aus der letzten Abbildung noch die reine Diskussionsansicht:

Best Practices bei Merge-/Pull-Requests
- MR/PR so zeitig wie möglich aufmachen
- Am besten sofort, wenn ein neuer Branch auf den Server gepusht wird!
- Ggf. mit dem Präfix "WIP" im Titel gegen unbeabsichtigtes vorzeitiges Mergen
sperren ... (bei GitHub als "Draft"-PR öffnen)
- Auswahl Start- und Ziel-Branch (und ggf. Ziel-Repo)
- Es gibt verschiedene Stellen, um einen MR/PR zu erstellen. Manchmal kann man nur
noch den Ziel-Branch einstellen, manchmal beides.
- Bitte auch darauf achten, welches Ziel-Repo eingestellt ist! Bei Forks wird
hier immer das Original-Repo voreingestellt!
- Den Ziel-Branch kann man ggf. auch nachträglich durch Editieren des MR/PR
anpassen (Start-Branch und Ziel-Repo leider nicht, also beim Erstellen aufpassen!).
- Titel (Summary): Das ist das, was man in der Übersicht sieht!
- Per Default wird die letzte Commit-Message eingesetzt.
- Analog zur Commit-Message: Bitte hier unbedingt einen sinnvollen Titel
einsetzen: Was macht der MR/PR (kurz)?
- Beschreibung: Was passiert, wenn man diesen MR/PR akzeptiert (ausführlicher)?
- Analog zur Commit-Message sollte hier bei Bedarf die Summary ausformuliert
werden und beschreiben, was der MR/PR ändert.
- Assignee: Wer soll sich drum kümmern?
- Ein MR/PR sollte immer jemanden zugewiesen sein, d.h. nicht "unassigned"
sein. Ansonsten ist nicht klar, wer den Request durchführen/akzeptieren
soll.
- Außerdem taucht ein nicht zugewiesener MR/PR nicht in der Übersicht "meiner"
MR/PR auf, d.h. diese MR/PR haben die Tendenz, vergessen zu werden!
- Diskussion am (und neben) dem Code
- Nur die vorgeschlagenen Code-Änderungen diskutieren!
- Weitergehende Diskussionen (etwa über Konzepte o.ä.) besser in separaten Issues
erledigen, da sonst die Anzeige des MR/PR langsam wird (ist beispielsweise ein
Problem bei Gitlab).
- Weitere Commits auf dem zu mergenden Branch gehen automatisch mit in den Request
- Weitere Entwickler kann man mit "
@username" in einem Kommentar auf "CC"
setzen und in die Diskussion einbinden
Anmerkung: Bei Gitlab (d.h. auch bei dem Gitlab-Server im SW-Labor) gibt es
"Merge-Requests" (MR). Bei Github gibt es "Pull-Requests" (PR) ...
Wrap-Up
-
Git-Workflows für die Zusammenarbeit:
- einfacher zentraler Ansatz für kleine Arbeitsgruppen vs.
- einfacher verteilter Ansatz mit einem "blessed" Repo (häufig in Open-Source-Projekten zu finden)
-
Aktualisieren Ihres Clones und Ihres Forks mit Änderungen aus dem "blessed" Repo
-
Unterschied zwischen einem Pull/Merge und einem Pull/Rebase
-
Erstellen von Beiträgen zu einem Projekt über Merge-Requests
- Welche Commits werden Bestandteil eines Merge-Requests (und warum)
- Diskussion über den Code in Merge-Requests
Git Worktree
TL;DR
Git Worktree erlaubt es, Branches in separaten Ordnern auszuchecken. Diese Ordner sind
mit der Workingcopy verknüpft, d.h. alle Änderungen über Git-Befehle werden automatisch
mit der Workingcopy "synchronisiert". Im Unterschied zum erneuten Clonen hat man in den
verknüpften Ordnern aber nicht die gesamte Historie noch einmal neu als .git-Ordner,
sondern nur den Link auf die Workingcopy, wodurch viel Platz gespart wird. Damit bilden
Git Worktrees eine elegante Möglichkeit, parallel an verschiedenen Branches zu arbeiten.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Vorteile von Git Worktree
- (K2) Prinzipielle Arbeitsweise von Git Worktree
- (K3) Anlegen von Worktrees
- (K3) Anzeigen von Worktrees
- (K3) Löschen von Worktrees
Git Worktree - Mehrere Branches parallel auschecken
Szenario
- Sie arbeiten an einem Projekt
- Großes Repo mit vielen Versionen und Branches
- Ungesicherte Änderungen im Featurebranch
- Wichtige Bugfixes an alter Version nötig
Lösungsansätze
git stash nutzen und Branch wechseln- Repo erneut in anderem Ordner auschecken
Probleme
-
git stash und git switch
Funktioniert für die meisten Fälle relativ gut und ist daher die "Lösung to go".
Aber Sie müssen später aufpassen, dass Sie auch wirklich wieder im richtigen
Branch sind, wenn Sie die Änderungen im Stash anwenden (git stash pop)! Und
wenn Sie mehrere Einträge in der Stash-Liste haben, kann es recht schnell recht
unübersichtlich werden - zu welchem Branch gehören welche Einträge in der
Stash-Liste?
Außerdem kann es gerade in größeren Projekten passieren, dass sich die Konfiguration
zwischenzeitlich ändert. Wenn Sie jetzt in der IDE einfach auf einen alten Stand
mit einer anderen Konfiguration wechseln, kann es schnell passieren, dass sich die
IDE "verschluckt" und Sie dadurch viel Arbeit haben.
-
Nochmal woanders auschecken
Im Prinzip ist das eine Möglichkeit. Sie können dann den anderen Ordner in Ihrer
IDE als neues Projekt öffnen und sofort starten.
Aber: Sie benötigen noch einmal den Platz auf der Festplatte/SSD/... wie für die
ursprüngliche Workingcopy! Das kann bei alten/großen Projekten schnell recht
groß werden und Probleme verursachen.
Außerdem ist die Synchronisierung zwischen den beiden Workingcopies (der ursprünglichen
und der neuen) nicht vorhanden bzw. das müssen Sie manuell per git push und git pull
(in jeder Kopie des Repos!) erledigen!
Git Worktree kann helfen!
=> Mehrere Branches gleichzeitig auschecken (als neue Ordner im Dateisystem)
How to use Git Worktree

Worktree anlegen
git worktree add <path> <branch>
Legt neuen Ordner <path> an und checkt darin <branch> als "linked worktree" aus.
Mit git worktree add ../wuppie foo würden Sie also parallel zum aktuellen Ordner
(wo Ihre Workingcopy enthalten ist) einen neuen Ordner wuppie/ anlegen und darin
den Branch foo auschecken.
Wenn Sie in den Ordner wuppie wechseln, finden Sie auch eine Datei .git. Darin
ist lediglich der Pfad zur Workingcopy vermerkt, damit Git Änderungen auch in die
eigentliche Workingcopy spiegeln kann. Dies ist der sogenannte "linked worktree".
Im Vergleich dazu finden Sie in der eigentlichen Workingcopy einen Ordner .git,
der üblicherweise die gesamte Historie etc. enthält und entsprechend groß werden kann.
Den Befehl git worktree add gibt es in verschiedenen Versionen. In der Kurzform
git worktree add <path> würde ein neuer Branch angelegt und ausgecheckt, der der
letzten Komponente von <path> entspricht ...
Warnung: Nicht in selben Ordner oder in Unterordner auschecken!
Die neuen Worktrees sollten immer außerhalb der Workingcopy liegen! Sie können
Git sehr schnell sehr gründlich durcheinanderbringen, wenn Sie einen Worktree im
selben Ordner oder in einem Unterordner anlegen.
git worktree sollte nach Möglichkeit nicht zusammen mit Git Submodules eingesetzt
werden (unstabiles Verhalten)!
Worktree wechseln
- Worktrees anzeigen:
git worktree list
- Worktree wechseln: Ordner wechseln (IDE: neues Projekt)
Die Worktrees sind aus Sicht des Dateisystems einfach Ordner. Die .git-Datei verlinkt
für Git den Ordner mit der ursprünglichen Workingcopy.
Um also mit einem Worktree arbeiten zu können, wechseln Sie einfach das Verzeichnis. In
einer IDE würden Sie entsprechend ein neues Projekt anlegen. So können Sie gleichzeitig
in verschiedenen Branches arbeiten.
Änderungen in einem Worktree werden automatisch in die ursprüngliche Workingcopy gespiegelt.
Analog können Sie in einem Worktree auf die aktuelle Historie aus der ursprünglichen Workingcopy
zugreifen.
Hinweis: Sie können in den Ordnern zwar Branches wechseln, aber nicht auf einen Branch,
der bereits in einem anderen Ordner (Worktree) ausgecheckt ist. Es ist gute Praxis, dass
die Ordnernamen dem ausgecheckten Branch (linked Worktree) entsprechen, um Verwirrungen
zu vermeiden.
Worktree löschen
git worktree remove <worktree>
Sofern der Worktree "clean" ist, es also keine nicht comitteten Änderungen gibt, können
Sie mit git worktree remove <worktree> einen Worktree <worktree> wieder löschen.
Dabei bleibt der Ordner erhalten - Sie können ihn selbst löschen oder später wiederverwenden.
Wrap-Up
Git Worktree: Auschecken von Branches in separate Ordner
Subsections of Modern Java: Funktionaler Stil und Stream-API
Lambda-Ausdrücke und funktionale Interfaces
TL;DR
Mit einer anonymen inneren Klasse erstellt man gewissermaßen ein Objekt einer "Wegwerf"-Klasse:
Man leitet on-the-fly von einem Interface ab oder erweitert eine Klasse und implementiert die
benötigten Methoden und erzeugt von dieser Klasse sofort eine Instanz (Objekt). Diese neue Klasse
ist im restlichen Code nicht sichtbar.
Anonyme innere Klassen sind beispielsweise in Swing recht nützlich, wenn man einer Komponente einen
Listener mitgeben will: Hier erzeugt man eine anonyme innere Klasse basierend auf dem passenden
Listener-Interface, implementiert die entsprechenden Methoden und übergibt das mit dieser Klasse
erzeugte Objekt als neuen Listener der Swing-Komponente.
Mit Java 8 können unter gewissen Bedingungen diese anonymen inneren Klassen zu Lambda-Ausdrücken
(und Methoden-Referenzen) vereinfacht werden. Dazu muss die anonyme innere Klasse ein sogenanntes
funktionales Interface implementieren.
Funktionale Interfaces sind Interfaces mit genau einer abstrakten Methode. Es können beliebig
viele Default-Methoden im Interface enthalten sein, und es können public sichtbare abstrakte
Methoden von java.lang.Object geerbt/überschrieben werden.
Die Lambda-Ausdrücke entsprechen einer anonymen Methode: Die Parameter werden aufgelistet (in
Klammern), und hinter einem Pfeil kommt entweder ein Ausdruck (Wert - gleichzeitig Rückgabewert
des Lambda-Ausdrucks) oder beliebig viele Anweisungen (in geschweiften Klammern, mit Semikolon):
- Form 1:
(parameters) -> expression
- Form 2:
(parameters) -> { statements; }
Der Lambda-Ausdruck muss von der Signatur her genau der einen abstrakten Methode im unterliegenden
funktionalen Interface entsprechen.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Funktionales Interfaces (Definition)
- (K3) Einsatz innerer und anonymer Klassen
- (K3) Erstellen eigener funktionaler Interfaces
- (K3) Einsatz von Lambda-Ausdrücken
Problem: Sortieren einer Studi-Liste
List<Studi> sl = new ArrayList<>();
// Liste sortieren?
sl.sort(???); // Parameter: java.util.Comparator<Studi>
public class MyCompare implements Comparator<Studi> {
@Override public int compare(Studi o1, Studi o2) {
return o1.getCredits() - o2.getCredits();
}
}
// Liste sortieren?
MyCompare mc = new MyCompare();
sl.sort(mc);
Da Comparator<T> ein Interface ist, muss man eine extra Klasse anlegen, die die
abstrakte Methode aus dem Interface implementiert und ein Objekt von dieser Klasse
erzeugen und dieses dann der sort()-Methode übergeben.
Die Klasse bekommt wie in Java üblich eine eigene Datei und ist damit in der
Package-Struktur offen sichtbar und "verstopft" mir damit die Strukturen: Diese
Klasse ist doch nur eine Hilfsklasse ... Noch schlimmer: Ich brauche einen Namen
für diese Klasse!
Den ersten Punkt könnte man über verschachtelte Klassen lösen: Die Hilfsklasse
wird innerhalb der Klasse definiert, die das Objekt benötigt. Für den zweiten
Punkt brauchen wir mehr Anlauf ...
Erinnerung: Verschachtelte Klassen ("Nested Classes")
Man kann Klassen innerhalb von Klassen definieren: Verschachtelte Klassen.
- Implizite Referenz auf Instanz der äußeren Klasse, Zugriff auf alle Elemente
- Begriffe:
- "normale" innere Klassen: "inner classes"
- statische innere Klassen: "static nested classes"
- Einsatzzweck:
- Hilfsklassen: Zusätzliche Funktionalität kapseln; Nutzung nur in äußerer Klasse
- Kapselung von Rückgabewerten
Sichtbarkeit: Wird u.U. von äußerer Klasse "überstimmt"
Innere Klassen ("Inner Classes")
- Objekt der äußeren Klasse muss existieren
- Innere Klasse ist normales Member der äußeren Klasse
- Implizite Referenz auf Instanz äußerer Klasse
- Zugriff auf alle Elemente der äußeren Klasse
- Sonderfall: Definition innerhalb von Methoden ("local classes")
- Nur innerhalb der Methode sichtbar
- Kennt zusätzlich
final Attribute der Methode
Beispiel:
public class Outer {
...
private class Inner {
...
}
Outer.Inner inner = new Outer().new Inner();
}
Statische innere Klassen ("Static Nested Classes")
- Keine implizite Referenz auf Objekt
- Nur Zugriff auf Klassenmethoden und -attribute
Beispiel:
class Outer {
...
static class StaticNested {
...
}
}
Outer.StaticNested nested = new Outer.StaticNested();
Lösung: Comparator als anonyme innere Klasse
List<Studi> sl = new ArrayList<>();
// Parametrisierung mit anonymer Klasse
sl.sort(
new Comparator<Studi>() {
@Override
public int compare(Studi o1, Studi o2) {
return o1.getCredits() - o2.getCredits();
}
}); // Semikolon nicht vergessen!!!
=> Instanz einer anonymen inneren Klasse, die das Interface Comparator<Studi> implementiert
- Für spezielle, einmalige Aufgabe: nur eine Instanz möglich
- Kein Name, kein Konstruktor, oft nur eine Methode
- Müssen Interface implementieren oder andere Klasse erweitern
- Achtung Schreibweise: ohne
implements oder extends!
- Konstruktor kann auch Parameter aufweisen
- Zugriff auf alle Attribute der äußeren Klasse plus alle
final lokalen
Variablen
- Nutzung typischerweise bei GUIs: Event-Handler etc.
Vereinfachung mit Lambda-Ausdruck
List<Studi> sl = new ArrayList<>();
// Parametrisierung mit anonymer Klasse
sl.sort(
new Comparator<Studi>() {
@Override
public int compare(Studi o1, Studi o2) {
return o1.getCredits() - o2.getCredits();
}
}); // Semikolon nicht vergessen!!!
// Parametrisierung mit Lambda-Ausdruck
sl.sort( (Studi o1, Studi o2) -> o1.getCredits() - o2.getCredits() );
Anmerkung: Damit für den Parameter alternativ auch ein Lambda-Ausdruck verwendet
werden kann, muss der erwartete Parameter vom Typ her ein "funktionales Interface"
(s.u.) sein!
Syntax für Lambdas
(Studi o1, Studi o2) -> o1.getCredits() - o2.getCredits()
Ein Lambda-Ausdruck ist eine Funktion ohne Namen und besteht aus drei Teilen:
- Parameterliste (in runden Klammern),
- Pfeil
- Funktionskörper (rechte Seite)
Falls es genau einen Parameter gibt, können die runden Klammern um den Parameter
entfallen.
Dabei kann der Funktionskörper aus einem Ausdruck ("expression") bestehen oder
einer Menge von Anweisungen ("statements"), die dann in geschweifte Klammern
eingeschlossen werden müssen (Block mit Anweisungen).
Der Wert des Ausdrucks ist zugleich der Rückgabewert des Lambda-Ausdrucks.
Varianten:
Quiz: Welches sind keine gültigen Lambda-Ausdrücke?
() -> {}() -> "wuppie"() -> { return "fluppie"; }(Integer i) -> return i + 42;(String s) -> { "foo"; }(String s) -> s.length()(Studi s) -> s.getCredits() > 300(List<Studi> sl) -> sl.isEmpty()(int x, int y) -> { System.out.println("Erg: "); System.out.println(x+y); }() -> new Studi()s -> s.getCps() > 100 && s.getCps() < 300s -> { return s.getCps() > 100 && s.getCps() < 300; }
Definition "Funktionales Interface" ("functional interfaces")
@FunctionalInterface
public interface Wuppie<T> {
int wuppie(T obj);
boolean equals(Object obj);
default int fluppie() { return 42; }
}
Wuppie<T> ist ein funktionales Interface
("functional interface") (seit Java 8)
- Hat genau eine abstrakte Methode
- Hat evtl. weitere Default-Methoden
- Hat evtl. weitere abstrakte Methoden, die
public Methoden von
java.lang.Object überschreiben
Die Annotation @FunctionalInterface selbst ist nur für den Compiler: Falls
das Interface kein funktionales Interface ist, würde er beim Vorhandensein
dieser Annotation einen Fehler werfen. Oder anders herum: Allein durch das
Annotieren mit @FunctionalInterface wird aus einem Interface noch kein
funktionales Interface! Vergleichbar mit @Override ...
Während man für eine anonyme Klasse lediglich ein "normales" Interface
(oder eine Klasse) benötigt, braucht man für Lambda-Ausdrücke zwingend ein
passendes funktionales Interface!
Anmerkung: Es scheint keine einheitliche deutsche Übersetzung für den Begriff
functional interface zu geben. Es wird häufig mit "funktionales Interface",
manchmal aber auch mit "Funktionsinterface" übersetzt.
Das in den obigen Beispielen eingesetzte Interface java.util.Comparator<T>
ist also ein funktionales Interface: Es hat nur eine eigene abstrakte Methode
int compare(T o1, T o2);.
Im Package java.util.function
sind einige wichtige funktionale Interfaces bereits vordefiniert, beispielsweise
Predicate (Test, ob eine Bedingung erfüllt ist) und Function (verarbeite
einen Wert und liefere einen passenden Ergebniswert). Diese kann man auch in
eigenen Projekten nutzen!
Quiz: Welches ist kein funktionales Interface?
public interface Wuppie {
int wuppie(int a);
}
public interface Fluppie extends Wuppie {
int wuppie(double a);
}
public interface Foo {
}
public interface Bar extends Wuppie {
default int bar() { return 42; }
}
Lambdas und funktionale Interfaces: Typprüfung
interface java.util.Comparator<T> {
int compare(T o1, T o2); // abstrakte Methode
}
// Verwendung ohne weitere Typinferenz
Comparator<Studi> c1 = (Studi o1, Studi o2) -> o1.getCredits() - o2.getCredits();
// Verwendung mit Typinferenz
Comparator<Studi> c2 = (o1, o2) -> o1.getCredits() - o2.getCredits();
Der Compiler prüft in etwa folgende Schritte, wenn er über einen Lambda-Ausdruck stolpert:
- In welchem Kontext habe ich den Lambda-Ausdruck gesehen?
- OK, der Zieltyp ist hier
Comparator<Studi>.
- Wie lautet die eine abstrakte Methode im
Comparator<T>-Interface?
- OK, das ist
int compare(T o1, T o2);
- Da
T hier an Studi gebunden ist, muss der Lambda-Ausdruck
der Methode int compare(Studi o1, Studi o2); entsprechen:
2x Studi als Parameter und als Ergebnis ein int
- Ergebnis:
a) Cool, passt zum Lambda-Ausdruck
c1. Fertig.
b) D.h. in c2 müssen o1 und o2 vom Typ Studi sein.
Cool, passt zum Lambda-Ausdruck c2. Fertig.
Wrap-Up
Challenges
Beispiel aus einem Code-Review im Dungeon-CampusMinden/Dungeon
Erklären Sie folgenden Code:
public interface IFightAI {
void fight(Entity entity);
}
public class AIComponent extends Component {
private final IFightAI fightAI;
fightAI =
entity1 -> {
System.out.println("TIME TO FIGHT!");
// todo replace with melee skill
};
}
Sortieren mit Lambdas und funktionalen Interfaces
In den Vorgaben
finden Sie die Klassen Student und StudentSort mit
vorgefertigten Methoden zu den Teilaufgaben sowie eine Testsuite
SortTest mit einzelnen Testfälllen zu den Teilaufgaben, mit der Ihre
Implementierung aufgerufen und getestet wird.
Ziel dieser Aufgabe ist es, eine Liste von Studierenden mithilfe verschiedener
syntaktischer Strukturen (Lambda-Ausdrücke, Methoden-Referenzen) zu sortieren.
Dabei soll bei allen Teilaufgaben die Methode
java.util.List#sort
für das eigentliche Sortieren verwendet werden.
-
In dieser Teilaufgabe sollen Sie der Methode List#sort das Sortierkriterium
mithilfe eines Lambda-Ausdrucks übergeben. Greifen Sie im Lambda-Ausdruck
für den Vergleich der Objekte auf die Getter der Objekte zu.
Hinweis: Erstellen Sie hierzu keine neuen Methoden, sondern verwenden Sie
nur Lambda-Ausdrücke innerhalb des Aufrufs von List#sort.
1a Sortieren Sie die Studierendenliste aufsteigend nach dem Geburtsdatum (sort_1a()).
1b Sortieren Sie die Studierendenliste absteigend nach dem Namen (sort_1b()).
-
Erweitern Sie die Klasse Student um eine statische Methode, die zwei
Student-Objekte anhand des Alters miteinander vergleicht. Die Methode
soll die Signatur static int compareByAge(Student a, Student b) besitzen
und die folgenden Werte zurückliefern:
- a > b -> -1
- a < b -> 1
- a == b -> 0
Verwenden Sie die neue statische Methode compareByAge zum Sortieren
der Liste in sort_2a(). Nutzen Sie dabei einen Lambda-Ausdruck.
-
Erweitern Sie die Klasse Student um eine Instanz-Methode, die das
Student-Objekt mit einem anderen (als Parameter übergebenen) Student-Objekt
vergleicht. Die Methode soll die Signatur int compareByName(Student other)
besitzen und die folgenden Werte zurückliefern:
- self > other -> -1
- self < other -> 1
- self == other -> 0
Verwenden Sie die neue Methode compareByName zum Sortieren der Liste in sort_3a().
Nutzen Sie dabei einen Lambda-Ausdruck.
-
Erstellen Sie ein generisches Funktionsinterface, dass die Methode compare
definiert und zum Vergleichen von zwei Objekten mit generischen Typen dient.
Erzeugen Sie mithilfe eines Lambda-Ausdrucks eine Instanz Ihres
Interfaces, um damit zwei Objekte vom Typ Student in Bezug auf ihr Alter
vergleichen zu können. Verwenden Sie die erzeugte Instanz, um die
Studierendenliste absteigend zu sortieren (sort_4a()).
Quellen
- [Ullenboom2021] Java ist auch eine Insel
Ullenboom, C., Rheinwerk-Verlag, 2021. ISBN 978-3-8362-8745-6.
Kapitel 12: Lambda-Ausdrücke und funktionale Programmierung - [Urma2014] Java 8 in Action: Lambdas, Streams, and Functional-Style Programming
Urma, R.-G. und Fusco, M. und Mycroft, A., Manning Publications, 2014. ISBN 978-1-6172-9199-9.
Kapitel 3: Lambda Expressions, Kapitel 5: Working with streams
Methoden-Referenzen
TL;DR
Seit Java8 können Referenzen auf Methoden statt anonymer Klassen eingesetzt werden
(funktionales Interface nötig).
Dabei gibt es drei mögliche Formen:
- Form 1: Referenz auf eine statische Methode:
ClassName::staticMethodName
(wird verwendet wie (args) -> ClassName.staticMethodName(args))
- Form 2: Referenz auf eine Instanz-Methode eines Objekts:
objectref::instanceMethodName
(wird verwendet wie (args) -> objectref.instanceMethodName(args))
- Form 3: Referenz auf eine Instanz-Methode eines Typs:
ClassName::instanceMethodName
(wird verwendet wie (o1, args) -> o1.instanceMethodName(args))
Im jeweiligen Kontext muss ein passendes funktionales Interface verwendet werden, d.h. ein
Interface mit genau einer abstrakten Methode. Die Methoden-Referenz muss von der
Syntax her dieser einen abstrakten Methode entsprechen (bei der dritten Form wird die
Methode auf dem ersten Parameter aufgerufen).
Videos (HSBI-Medienportal)
Lernziele
- (K2) Funktionales Interfaces (Definition)
- (K3) Einsatz von Methoden-Referenzen
Beispiel: Sortierung einer Liste
List<Studi> sl = new ArrayList<Studi>();
// Anonyme innere Klasse
Collections.sort(sl, new Comparator<Studi>() {
@Override public int compare(Studi o1, Studi o2) {
return Studi.cmpCpsClass(o1, o2);
}
});
// Lambda-Ausdruck
Collections.sort(sl, (o1, o2) -> Studi.cmpCpsClass(o1, o2));
// Methoden-Referenz
Collections.sort(sl, Studi::cmpCpsClass);
Anmerkung
Für das obige Beispiel wird davon ausgegangen, dass in der Klasse Studi eine
statische Methode cmpCpsClass() existiert:
public static int cmpCpsClass(Studi s1, Studi s2) {
return s1.getCps() - s2.getCps();
}
Wenn man im Lambda-Ausdruck nur Methoden der eigenen Klasse aufruft, kann man das
auch direkt per Methoden-Referenz abkürzen!
- Erinnerung:
Comparator<T> ist ein funktionales Interface
- Instanzen können wie üblich durch Ableiten bzw. anonyme Klassen erzeugt werden
- Alternativ kann seit Java8 auch ein passender Lambda-Ausdruck verwendet werden
- Ab Java8: Referenzen auf passende Methoden (Signatur!) können ein funktionales
Interface "implementieren"
- Die statische Methode
static int cmpCpsClass(Studi s1, Studi s2) hat die
selbe Signatur wie int compare(Studi s1, Studi s2) aus Comparator<Studi>
- Kann deshalb wie eine Instanz von
Comparator<Studi> genutzt werden
- Name der Methode spielt dabei keine Rolle
Überblick: Arten von Methoden-Referenzen
-
Referenz auf eine statische Methode
- Form:
ClassName::staticMethodName
- Wirkung: Aufruf mit
(args) -> ClassName.staticMethodName(args)
-
Referenz auf Instanz-Methode eines bestimmten Objekts
- Form:
objectref::instanceMethodName
- Wirkung: Aufruf mit
(args) -> objectref.instanceMethodName(args)
-
Referenz auf Instanz-Methode eines bestimmten Typs
- Form:
ClassName::instanceMethodName
- Wirkung: Aufruf mit
(arg0, rest) -> arg0.instanceMethodName(rest)
(arg0 ist vom Typ ClassName)
Anmerkung: Analog zur Referenz auf eine statische Methode gibt es noch die
Form der Referenz auf einen Konstruktor: ClassName::new. Für Referenzen auf
Konstruktoren mit mehr als 2 Parametern muss ein eigenes passendes funktionales
Interface mit entsprechend vielen Parametern definiert werden ...
Methoden-Referenz 1: Referenz auf statische Methode
public class Studi {
public static int cmpCpsClass(Studi s1, Studi s2) {
return s1.getCredits() - s2.getCredits();
}
public static void main(String... args) {
List<Studi> sl = new ArrayList<Studi>();
// Referenz auf statische Methode
Collections.sort(sl, Studi::cmpCpsClass);
// Entsprechender Lambda-Ausdruck
Collections.sort(sl, (o1, o2) -> Studi.cmpCpsClass(o1, o2));
}
}
Collections.sort() erwartet in diesem Szenario als zweiten Parameter eine Instanz von
Comparator<Studi> mit einer Methode int compare(Studi o1, Studi o2).
Die übergebene Referenz auf die statische Methode cmpCpsClass der Klasse Studi
hat die selbe Signatur und wird deshalb von Collections.sort() genauso genutzt wie
die eigentlich erwartete Methode Comparator<Studi>#compare(Studi o1, Studi o2), d.h.
statt compare(o1, o2) wird nun für jeden Vergleich Studi.cmpCpsClass(o1, o2)
aufgerufen.
Methoden-Referenz 2: Referenz auf Instanz-Methode (Objekt)
public class Studi {
public int cmpCpsInstance(Studi s1, Studi s2) {
return s1.getCredits() - s2.getCredits();
}
public static void main(String... args) {
List<Studi> sl = new ArrayList<Studi>();
Studi holger = new Studi("Holger", 42);
// Referenz auf Instanz-Methode eines Objekts
Collections.sort(sl, holger::cmpCpsInstance);
// Entsprechender Lambda-Ausdruck
Collections.sort(sl, (o1, o2) -> holger.cmpCpsInstance(o1, o2));
}
}
Collections.sort() erwartet in diesem Szenario als zweites Argument wieder eine Instanz
von Comparator<Studi> mit einer Methode int compare(Studi o1, Studi o2).
Die übergebene Referenz auf die Instanz-Methode cmpCpsInstance des Objekts holger
hat die selbe Signatur und wird entsprechend von Collections.sort() genauso genutzt wie
die eigentlich erwartete Methode Comparator<Studi>#compare(Studi o1, Studi o2), d.h.
statt compare(o1, o2) wird nun für jeden Vergleich holger.cmpCpsInstance(o1, o2)
aufgerufen.
Methoden-Referenz 3: Referenz auf Instanz-Methode (Typ)
public class Studi {
public int cmpCpsInstance(Studi studi) {
return this.getCredits() - studi.getCredits();
}
public static void main(String... args) {
List<Studi> sl = new ArrayList<Studi>();
// Referenz auf Instanz-Methode eines Typs
Collections.sort(sl, Studi::cmpCpsInstance);
// Entsprechender Lambda-Ausdruck
Collections.sort(sl, (o1, o2) -> o1.cmpCpsInstance(o2));
}
}
Collections.sort() erwartet in diesem Szenario als zweites Argument wieder eine Instanz
von Comparator<Studi> mit einer Methode int compare(Studi o1, Studi o2).
Die übergebene Referenz auf die Instanz-Methode cmpCpsInstance des Typs Studi hat
die Signatur int cmpCpsInstance(Studi studi) und wird von Collections.sort() so genutzt:
Statt compare(o1, o2) wird nun für jeden Vergleich o1.cmpCpsInstance(o2)
aufgerufen.
Ausblick: Threads
Erinnerung an bzw. Vorgriff auf “Threads: Intro”:
public interface Runnable {
void run();
}
Damit lassen sich Threads auf verschiedene Arten erzeugen:
public class ThreadStarter {
public static void wuppie() { System.out.println("wuppie(): wuppie"); }
}
Thread t1 = new Thread(new Runnable() {
public void run() {
System.out.println("t1: wuppie");
}
});
Thread t2 = new Thread(() -> System.out.println("t2: wuppie"));
Thread t3 = new Thread(ThreadStarter::wuppie);
Ausblick: Datenstrukturen als Streams
Erinnerung an bzw. Vorgriff auf “Stream-API”:
class X {
public static boolean gtFour(int x) { return (x > 4) ? true : false; }
}
List<String> words = Arrays.asList("Java8", "Lambdas", "PM",
"Dungeon", "libGDX", "Hello", "World", "Wuppie");
List<Integer> wordLengths = words.stream()
.map(String::length)
.filter(X::gtFour)
.sorted()
.collect(toList());
- Collections können als Datenstrom betrachtet werden:
stream()
- Iteration über die Collection, analog zu externer Iteration mit
foreach
- Daten aus dem Strom filtern:
filter, braucht Prädikat
- Auf alle Daten eine Funktion anwenden:
map
- Daten im Strom sortieren:
sort (auch mit Comparator)
- Daten wieder einsammeln mit
collect
=> Typische Elemente funktionaler Programmierung
=> Verweis auf Wahlfach "Spezielle Methoden der Programmierung"
Wrap-Up
Seit Java8: Methoden-Referenzen statt anonymer Klassen (funktionales Interface nötig)
Challenges
In den Vorgaben
finden Sie die Klassen Student und StudentSort mit
vorgefertigten Methoden zu den Teilaufgaben sowie eine Testsuite
SortTest mit einzelnen Testfälllen zu den Teilaufgaben, mit der Ihre
Implementierung aufgerufen und getestet wird.
Ziel dieser Aufgabe ist es, eine Liste von Studierenden mithilfe verschiedener
syntaktischer Strukturen (Lambda-Ausdrücke, Methoden-Referenzen) zu sortieren.
Dabei soll bei allen Teilaufgaben die Methode
java.util.List#sort
für das eigentliche Sortieren verwendet werden.
-
Erweitern Sie die Klasse Student um eine statische Methode, die zwei
Student-Objekte anhand des Alters miteinander vergleicht. Die Methode
soll die Signatur static int compareByAge(Student a, Student b) besitzen
und die folgenden Werte zurückliefern:
- a > b -> -1
- a < b -> 1
- a == b -> 0
Verwenden Sie die neue statische Methode compareByAge zum Sortieren
der Liste in sort_2b(). Nutzen Sie dabei eine Methodenreferenz.
-
Erweitern Sie die Klasse Student um eine Instanz-Methode, die das
Student-Objekt mit einem anderen (als Parameter übergebenen) Student-Objekt
vergleicht. Die Methode soll die Signatur int compareByName(Student other)
besitzen und die folgenden Werte zurückliefern:
- self > other -> -1
- self < other -> 1
- self == other -> 0
Verwenden Sie die neue Methode compareByName zum Sortieren der Liste in sort_3b().
Nutzen Sie dabei eine Methodenreferenz.
Quellen
- [Urma2014] Java 8 in Action: Lambdas, Streams, and Functional-Style Programming
Urma, R.-G. und Fusco, M. und Mycroft, A., Manning Publications, 2014. ISBN 978-1-6172-9199-9.
Kapitel 3: Lambda Expressions, Kapitel 5: Working with streams
Stream-API
TL;DR
Mit der Collection-API existiert in Java die Möglichkeit, Daten auf verschiedenste Weisen zu
speichern (Collection<T>). Mit der Stream-API gibt es die Möglichkeit, diese Daten in einer
Art Pipeline zu verarbeiten. Ein Stream<T> ist eine Folge von Objekten vom Typ T. Die
Verarbeitung der Daten ist "lazy", d.h. sie erfolgt erst auf Anforderung (durch die terminale
Operation).
Ein Stream hat eine Datenquelle und kann beispielsweise über Collection#stream() oder
Stream.of() angelegt werden. Streams speichern keine Daten. Die Daten werden aus der
verbundenen Datenquelle geholt.
Auf einem Stream kann man eine Folge von intermediären Operationen wie peek(), map(),
flatMap(), filter(), sorted() ... durchführen. Alle diese Operationen arbeiten auf
dem Stream und erzeugen einen neuen Stream als Ergebnis. Dadurch kann die typische
Pipeline-artige Verkettung der Operationen ermöglicht werden. Die intermediären Operationen
werden erst ausgeführt, wenn der Stream durch eine terminale Operation geschlossen wird.
Terminale Operationen wie count(), forEach(), allMatch() oder collect()
collect(Collectors.toList()) (bzw. direkt mit stream.toList() (ab Java16))collect(Collectors.toSet())collect(Collectors.toCollection(LinkedList::new)) (als Supplier<T>)
stoßen die Verarbeitung des Streams an und schließen den Stream damit ab.
Wir können hier nur die absoluten Grundlagen betrachten. Die Stream-API ist sehr groß und
mächtig und lohnt die weitere selbstständige Auseinandersetzung :-)
Videos (HSBI-Medienportal)
Lernziele
- (K2) Streams speichern keine Daten
- (K2) Streams verarbeiten die Daten lazy
- (K2)
map() ändert den Typ (und Inhalt) von Objekten im Stream, aber nicht die Anzahl - (K2)
filter() ändert die Anzahl der Objekte im Stream, aber nicht deren Typ (und Inhalt) - (K2) Streams machen ausführlich Gebrauch von den funktionalen Interfaces in
java.util.function - (K2) Streams sollten nicht in Attributen gehalten oder als Argument von Methoden herumgereicht werden
- (K3) Anlegen eines Streams
- (K3) Verkettung von intermediären Operationen
- (K3) Durchführung der Berechnung und Abschluss des Streams mit einer terminalen Operation
- (K3) Einsatz von
flatMap()
Motivation
Es wurden Studis, Studiengänge und Fachbereiche modelliert (aus Gründen der Übersichtlichkeit
einfach als Record-Klassen).
Nun soll pro Fachbereich die Anzahl der Studis ermittelt werden, die bereits 100 ECTS
oder mehr haben. Dazu könnte man über alle Studiengänge im Fachbereich iterieren, und
in der inneren Schleife über alle Studis im Studiengang. Dann filtert man alle Studis,
deren ECTS größer 100 sind und erhöht jeweils den Zähler:
public record Studi(String name, int credits) {}
public record Studiengang(String name, List<Studi> studis) {}
public record Fachbereich(String name, List<Studiengang> studiengaenge) {}
private static long getCountFB(Fachbereich fb) {
long count = 0;
for (Studiengang sg : fb.studiengaenge()) {
for (Studi s : sg.studis()) {
if (s.credits() > 100) count += 1;
}
}
return count;
}
Dies ist ein Beispiel, welches klassisch in OO-Manier als Iteration über Klassen
realisiert ist. (Inhaltlich ist es vermutlich nicht sooo sinnvoll.)
Innere Schleife mit Streams umgeschrieben
private static long getCountSG(Studiengang sg) {
return sg.studis().stream()
.map(Studi::credits)
.filter(c -> c > 100)
.count();
}
private static long getCountFB2(Fachbereich fb) {
long count = 0;
for (Studiengang sg : fb.studiengaenge()) {
count += getCountSG(sg);
}
return count;
}
Erklärung des Beispiels
Im Beispiel wurde die innere Schleife in einen Stream ausgelagert.
Mit der Methode Collection#stream() wird aus der Collection ein
neuer Stream erzeugt. Auf diesem wird für jedes Element durch die
Methode map() die Methode Studi#credits() angewendet, was aus
einem Strom von Studi einen Strom von Integer macht. Mit filter()
wird auf jedes Element das Prädikat c -> c > 100 angewendet und
alle Elemente aus dem Strom entfernt, die der Bedingung nicht
entsprechen. Am Ende wird mit count() gezählt, wie viele Elemente
im Strom enthalten sind.
Was ist ein Stream?
Ein "Stream" ist ein Strom (Folge) von Daten oder Objekten. In Java wird
die Collections-API für die Speicherung von Daten (Objekten) verwendet.
Die Stream-API dient zur Iteration über diese Daten und entsprechend
zur Verarbeitung der Daten. In Java speichert ein Stream keine Daten.
Das Konzept kommt aus der funktionalen Programmierung und wurde in Java
nachträglich eingebaut (wobei dieser Prozess noch lange nicht abgeschlossen
zu sein scheint).
In der funktionalen Programmierung kennt man die Konzepte "map", "filter"
und "reduce": Die Funktion "map()" erhält als Parameter eine Funktion und
wendet diese auf alle Elemente eines Streams an. Die Funktion "filter()"
bekommt ein Prädikat als Parameter und prüft jedes Element im Stream, ob
es dem Prädikat genügt (also ob das Prädikat mit dem jeweiligen Element
zu true evaluiert - die anderen Objekte werden entfernt). Mit "reduce()"
kann man Streams zu einem einzigen Wert zusammenfassen (denken Sie etwa
an das Aufsummieren aller Elemente eines Integer-Streams). Zusätzlich kann
man in der funktionalen Programmierung ohne Probleme unendliche Ströme
darstellen: Die Auswertung erfolgt nur bei Bedarf und auch dann auch nur
so weit wie nötig. Dies nennt man auch "lazy evaluation".
Die Streams in Java versuchen, diese Konzepte aus der funktionalen Programmierung
in die objektorientierte Programmierung zu übertragen. Ein Stream in Java
hat eine Datenquelle, von wo die Daten gezogen werden - ein Stream speichert
selbst keine Daten. Es gibt "intermediäre Operationen" auf einem Stream,
die die Elemente verarbeiten und das Ergebnis als Stream zurückliefern. Daraus
ergibt sich typische Pipeline-artige Verkettung der Operationen. Allerdings
werden diese Operationen erst durchgeführt, wenn eine "terminale Operation" den
Stream "abschließt". Ein Stream ohne eine terminale Operation macht also
tatsächlich nichts.
Die Operationen auf dem Stream sind üblicherweise zustandslos, können aber
durchaus auch einen Zustand haben. Dies verhindert üblicherweise die parallele
Verarbeitung der Streams. Operationen sollten aber nach Möglichkeit keine
Seiteneffekte haben, d.h. keine Daten außerhalb des Streams modifizieren.
Operationen dürfen auf keinen Fall die Datenquelle des Streams modifizieren!
Erzeugen von Streams
List<String> l1 = List.of("Hello", "World", "foo", "bar", "wuppie");
Stream<String> s1 = l1.stream();
Stream<String> s2 = Stream.of("Hello", "World", "foo", "bar", "wuppie");
Random random = new Random();
Stream<Integer> s3 = Stream.generate(random::nextInt);
Pattern pattern = Pattern.compile(" ");
Stream<String> s4 = pattern.splitAsStream("Hello world! foo bar wuppie!");
Dies sind möglicherweise die wichtigsten Möglichkeiten, in Java einen Stream
zu erzeugen.
Ausgehend von einer Klasse aus der Collection-API kann man die Methode
Collection#stream() aufrufen und bekommt einen seriellen Stream.
Alternativ bietet das Interface Stream verschiedene statische Methoden wie
Stream.of() an, mit deren Hilfe Streams angelegt werden können. Dies funktioniert
auch mit Arrays ...
Und schließlich kann man per Stream.generate() einen Stream anlegen, wobei
als Argument ein "Supplier" (Interface java.util.function.Supplier<T>) übergeben
werden muss. Dieses Argument wird dann benutzt, um die Daten für den Stream zu
generieren.
Wenn man aufmerksam hinschaut, findet man an verschiedensten Stellen die
Möglichkeit, die Daten per Stream zu verarbeiten, u.a. bei regulären Ausdrücken.
Man kann per Collection#parallelStream() auch parallele Streams erzeugen, die
intern das "Fork&Join-Framework" nutzen. Allerdings sollte man nur dann parallele
Streams anlegen, wenn dadurch tatsächlich Vorteile durch die Parallelisierung zu
erwarten sind (Overhead!).
Intermediäre Operationen auf Streams
private static void dummy(Studiengang sg) {
sg.studis().stream()
.peek(s -> System.out.println("Looking at: " + s.name()))
.map(Studi::credits)
.peek(c -> System.out.println("This one has: " + c + " ECTS"))
.filter(c -> c > 5)
.peek(c -> System.out.println("Filtered: " + c))
.sorted()
.forEach(System.out::println);
}
An diesem (weitestgehend sinnfreien) Beispiel werden einige intermediäre Operationen
demonstriert.
Die Methode peek() liefert einen Stream zurück, die aus den Elementen des Eingabestroms
bestehen. Auf jedes Element wird die Methode void accept(T) des Consumer<T> angewendet
(Argument der Methode), was aber nicht zu einer Änderung der Daten führt.
Hinweis: Diese Methode dient vor allem zu Debug-Zwecken! Durch den Seiteneffekt kann
die Methode eine schlechtere Laufzeit zur Folge haben oder sogar eine sonst mögliche
parallele Verarbeitung verhindern oder durch eine parallele Verarbeitung verwirrende
Ergebnisse zeigen!
Die Methode map() liefert ebenfalls einen Stream zurück, der durch die Anwendung der Methode
R apply(T) der als Argument übergebenen Function<T,R> auf jedes Element des Eingabestroms
entsteht. Damit lassen sich die Elemente des ursprünglichen Streams verändern; für jedes Element
gibt es im Ergebnis-Stream ebenfalls ein Element (der Typ ändert sich, aber nicht die Anzahl
der Elemente).
Mit der Methode filter() wird ein Stream erzeugt, der alle Objekte des Eingabe-Streams
enthält, auf denen die Anwendung der Methode boolean test(T) des Arguments Predicate<T>
zu true evaluiert (der Typ und Inhalt der Elemente ändert sich nicht, aber die Anzahl der
Elemente).
Mit sorted() wird ein Stream erzeugt, der die Elemente des Eingabe-Streams sortiert
(existiert auch mit einem Comparator<T> als Parameter).
Diese Methoden sind alles intermediäre Operationen. Diese arbeiten auf einem Stream und
erzeugen einen neuen Stream und werden erst dann ausgeführt, wenn eine terminale Operation den
Stream abschließt.
Dabei sind die gezeigten intermediären Methoden bis auf sorted() ohne inneren Zustand.
sorted() ist eine Operation mit innerem Zustand (wird für das Sortieren benötigt). Dies
kann ordentlich in Speicher und Zeit zuschlagen und u.U. nicht/nur schlecht parallelisierbar
sein. Betrachten Sie den fiktiven parallelen Stream stream.parallel().sorted().skip(42):
Hier müssen erst alle Elemente sortiert werden, bevor mit skip(42) die ersten 42 Elemente
entfernt werden. Dies kann auch nicht mehr parallel durchgeführt werden.
Die Methode forEach() schließlich ist eine terminale Operation, die auf jedes Element des
Eingabe-Streams die Methode void accept(T) des übergebenen Consumer<T> anwendet. Diese
Methode ist eine terminale Operation, d.h. sie führt zur Auswertung der anderen intermediären
Operationen und schließt den Stream ab.
Was tun, wenn eine Methode Streams zurückliefert
Wir konnten vorhin nur die innere Schleife in eine Stream-basierte Verarbeitung
umbauen. Das Problem ist: Die äußere Schleife würde einen Stream liefern (Stream
von Studiengängen), auf dem wir die map-Funktion anwenden müssten und darin dann
für jeden Studiengang einen (inneren) Stream mit den Studis eines Studiengangs
verarbeiten müssten.
private static long getCountSG(Studiengang sg) {
return sg.studis().stream().map(Studi::credits).filter(c -> c > 100).count();
}
private static long getCountFB2(Fachbereich fb) {
long count = 0;
for (Studiengang sg : fb.studiengaenge()) {
count += getCountSG(sg);
}
return count;
}
Dafür ist die Methode flatMap() die Lösung. Diese Methode bekommt als Argument
ein Objekt vom Typ Function<? super T, ? extends Stream<? extends R>> mit einer
Methode Stream<? extends R> apply(T). Die Methode flatMap() verarbeitet den
Stream in zwei Schritten:
-
Mappe über alle Elemente des Eingabe-Streams mit der Funktion. Im Beispiel würde
also aus einem Stream<Studiengang> jeweils ein Stream<Stream<Studi>>, also
alle Studiengang-Objekte werden durch je ein Stream<Studi>-Objekt ersetzt.
Wir haben jetzt also einen Stream von Stream<Studi>-Objekten.
-
"Klopfe den Stream wieder flach", d.h. nimm die einzelnen Studi-Objekte aus
den Stream<Studi>-Objekten und setze diese stattdessen in den Stream. Das
Ergebnis ist dann wie gewünscht ein Stream<Studi> (Stream mit Studi-Objekten).
private static long getCountFB3(Fachbereich fb) {
return fb.studiengaenge().stream()
.flatMap(sg -> sg.studis().stream())
.map(Studi::credits)
.filter(c -> c > 100)
.count();
}
Zum direkten Vergleich hier noch einmal der ursprüngliche Code mit zwei
verschachtelten Schleifen und entsprechenden Hilfsvariablen:
private static long getCountFB(Fachbereich fb) {
long count = 0;
for (Studiengang sg : fb.studiengaenge()) {
for (Studi s : sg.studis()) {
if (s.credits() > 100) count += 1;
}
}
return count;
}
Streams abschließen: Terminale Operationen
Stream<String> s = Stream.of("Hello", "World", "foo", "bar", "wuppie");
long count = s.count();
s.forEach(System.out::println);
String first = s.findFirst().get();
Boolean b = s.anyMatch(e -> e.length() > 3);
List<String> s1 = s.collect(Collectors.toList());
List<String> s2 = s.toList(); // ab Java16
Set<String> s3 = s.collect(Collectors.toSet());
List<String> s4 = s.collect(Collectors.toCollection(LinkedList::new));
Streams müssen mit einer terminalen Operation abgeschlossen werden, damit die Verarbeitung
tatsächlich angestoßen wird (lazy evaluation).
Es gibt viele verschiedene terminale Operationen. Wir haben bereits count() und forEach()
gesehen. In der Sitzung zu “Optionals”
werden wir noch findFirst() näher kennenlernen.
Daneben gibt es beispielsweise noch allMatch(), anyMatch() und noneMatch(), die jeweils
ein Prädikat testen und einen Boolean zurückliefern (matchen alle, mind. eines oder keines der
Objekte im Stream).
Mit min() und max() kann man sich das kleinste und das größte Element des Streams liefern
lassen. Beide Methoden benötigen dazu einen Comparator<T> als Parameter.
Mit der Methode collect() kann man eine der drei Methoden aus Collectors über den Stream
laufen lassen und eine Collection erzeugen lassen:
toList() sammelt die Elemente in ein List-Objekt (bzw. direkt mit stream.toList() (ab Java16))toSet() sammelt die Elemente in ein Set-ObjekttoCollection() sammelt die Elemente durch Anwendung der Methode T get() des übergebenen
Supplier<T>-Objekts auf
Die ist nur die sprichwörtliche "Spitze des Eisbergs"! Es gibt viele weitere Möglichkeiten, sowohl
bei den intermediären als auch den terminalen Operationen. Schauen Sie in die Dokumentation!
Spielregeln
-
Operationen dürfen nicht die Stream-Quelle modifizieren
-
Operationen können die Werte im Stream ändern (map) oder die Anzahl (filter)
-
Keine Streams in Attributen/Variablen speichern oder als Argumente übergeben: Sie könnten bereits "gebraucht" sein!
=> Ein Stream sollte immer sofort nach der Erzeugung benutzt werden
-
Operationen auf einem Stream sollten keine Seiteneffekte (Veränderungen von Variablen/Attributen außerhalb des Streams) haben
(dies verhindert u.U. die parallele Verarbeitung)
Wrap-Up
Stream<T>: Folge von Objekten vom Typ T, Verarbeitung "lazy"
(Gegenstück zu Collection<T>: Dort werden Daten gespeichert, hier werden Daten verarbeitet)
-
Neuen Stream anlegen: Collection#stream() oder Stream.of() ...
-
Intermediäre Operationen: peek(), map(), flatMap(), filter(), sorted() ...
-
Terminale Operationen: count(), forEach(), allMatch(), collect() ...
collect(Collectors.toList())collect(Collectors.toSet())collect(Collectors.toCollection()) (mit Supplier<T>)
-
Streams speichern keine Daten
-
Intermediäre Operationen laufen erst bei Abschluss des Streams los
-
Terminale Operation führt zur Verarbeitung und Abschluss des Streams
Schöne Doku: "The Stream API", und auch
"Package java.util.stream".
Challenges
In den Vorgaben
finden Sie die Klasse Main, in der die Methoden
Main#a, Main#b und Main#c "klassisch" mit for-Schleifen
implementiert wurden.
Führen Sie für die drei Methoden Main#a, Main#b und Main#c
ein Refactoring durch, so dass in diesen Methoden jeweils die
Java Stream-API genutzt wird und es keine for-/foreach-/while-Schleifen
mehr gibt.
Optional
TL;DR
Häufig hat man in Methoden den Fall, dass es keinen Wert gibt, und man liefert dann
null als "kein Wert vorhanden" zurück. Dies führt dazu, dass die Aufrufer eine
entsprechende null-Prüfung für die Rückgabewerte durchführen müssen, bevor sie
das Ergebnis nutzen können.
Optional schließt elegant den Fall "kein Wert vorhanden" ein: Es kann mit der Methode
Optional.ofNullable() das Argument in ein Optional verpacken (Argument != null)
oder ein Optional.empty() zurückliefern ("leeres" Optional, wenn Argument == null).
Man kann Optionals prüfen mit isEmpty() und ifPresent() und dann direkt mit
ifPresent(), orElse() und orElseThrow() auf den verpackten Wert zugreifen.
Besser ist aber der Zugriff über die Stream-API von Optional: map(), filter,
flatMap(), ...
Optional ist vor allem für Rückgabewerte gedacht, die den Fall "kein Wert vorhanden"
einschließen sollen. Attribute, Parameter und Sammlungen sollten nicht Optional-Referenzen
speichern, sondern "richtige" (unverpackte) Werte (und eben zur Not null). Optional
ist kein Ersatz für null-Prüfung von Methoden-Parametern (nutzen Sie hier beispielsweise
passende Annotationen). Optional ist auch kein Ersatz für vernünftiges Exception-Handling
im Fall, dass etwas Unerwartetes passiert ist. Liefern Sie niemals null zurück, wenn
der Rückgabetyp der Methode ein Optional ist!
Videos (HSBI-Medienportal)
Lernziele
- (K2) Optionals sind kein Ersatz für
null-Prüfung! - (K2) Optionals sollen nicht für Attribute oder Parameter genutzt werden
- (K2) Es darf kein
null zurückgeliefert werden, wenn der Rückgabetyp ein Optional ist - (K2) Optionals und
null sind kein Ersatz für Exception-Handling - (K3) Einsatz von
Optional in Rückgabewerten - (K3) Erzeugen von Optionals mit
Optional.ofNullable() - (K3) Zugriff auf Optionals entweder direkt oder per Stream-API
Motivation
public class LSF {
private Set<Studi> sl;
public Studi getBestStudi() {
if (sl == null) return null; // Fehler: Es gibt noch keine Sammlung
Studi best = null;
for (Studi s : sl) {
if (best == null) best = s;
if (best.credits() < s.credits()) best = s;
}
return best;
}
}
public static void main(String... args) {
LSF lsf = new LSF();
Studi best = lsf.getBestStudi();
if (best != null) {
String name = best.name();
if (name != null) {
// mach was mit dem Namen ...
}
}
}
Problem: null wird an (zu) vielen Stellen genutzt
- Es gibt keinen Wert ("not found")
- Felder wurden (noch) nicht initialisiert
- Es ist ein Problem oder etwas Unerwartetes aufgetreten
=> Parameter und Rückgabewerte müssen stets auf null geprüft werden
(oder Annotationen wie @NotNull eingesetzt werden ...)
Lösung
Optional<T> für Rückgabewerte, die "kein Wert vorhanden" mit einschließen
(statt null bei Abwesenheit von Werten)@NotNull/@Nullable für Parameter einsetzen (oder separate Prüfung)- Exceptions werfen in Fällen, wo ein Problem aufgetreten ist
Anmerkungen
- Verwendung von
null auf Attribut-Ebene (Klassen-interne Verwendung) ist okay!
Optional<T> ist kein Ersatz für null-Checks!null ist kein Ersatz für vernünftiges Error-Handling!
Das häufig zu beobachtende "Irgendwas Unerwartetes ist passiert, hier ist null"
ist ein Anti-Pattern!
Beispiel aus der Praxis im PM-Dungeon
Schauen Sie sich einmal das Review zu den ecs.components.ai.AITools in
https://github.com/Dungeon-CampusMinden/Dungeon/pull/128#pullrequestreview-1254025874
an.

Die Methode AITools#calculateNewPath soll in der Umgebung einer als Parameter
übergebenen Entität nach einem Feld (Tile) suchen, welches für die Entität
betretbar ist und einen Pfad von der Position der Entität zu diesem Feld an den
Aufrufer zurückliefern.
Zunächst wird in der Entität nach einer PositionComponent und einer VelocityComponent
gesucht. Wenn es (eine) diese(r) Components nicht in der Entität gibt, wird der Wert
null an den Aufrufer von AITools#calculateNewPath zurückgeliefert.
(Anmerkung: Interessanterweise wird in der Methode nicht mit der VelocityComponent
gearbeitet.)
Dann wird in der PositionComponent die Position der Entität im aktuellen Level
abgerufen. In einer Schleife werden alle Felder im gegebenen Radius in eine Liste
gespeichert.
(Anmerkung: Da dies über die float-Werte passiert und nicht über die Feld-Indizes
wird ein Tile u.U. recht oft in der Liste abgelegt. Können Sie sich hier einfache
Verbesserungen überlegen?)
Da level.getTileAt() offenbar als Antwort auch null zurückliefern kann, werden
nun zunächst per tiles.removeIf(Objects::isNull); all diese null-Werte wieder aus
der Liste entfernt. Danach erfolgt die Prüfung, ob die verbleibenden Felder betretbar
sind und nicht-betretbare Felder werden entfernt.
Aus den verbleibenden (betretbaren) Feldern in der Liste wird nun eines zufällig
ausgewählt und per level.findPath() ein Pfad von der Position der Entität zu diesem
Feld berechnet und zurückgeliefert.
(Anmerkung: Hier wird ein zufälliges Tile in der Liste der umgebenden Felder gewählt,
von diesem die Koordinaten bestimmt, und dann noch einmal aus dem Level das dazugehörige
Feld geholt - dabei hatte man die Referenz auf das Feld bereits in der Liste. Können
Sie sich hier eine einfache Verbesserung überlegen?)
Zusammengefasst:
- Die als Parameter
entity übergebene Referenz darf offenbar nicht null sein.
Die ersten beiden Statements in der Methode rufen auf dieser Referenz Methoden
auf, was bei einer null-Referenz zu einer NullPointer-Exception führen
würde. Hier wäre null ein Fehlerzustand.
entity.getComponent() kann offenbar null zurückliefern, wenn die gesuchte
Component nicht vorhanden ist. Hier wird null als "kein Wert vorhanden"
genutzt, was dann nachfolgende null-Checks notwendig macht.- Wenn es die gewünschten Components nicht gibt, wird dem Aufrufer der Methode
null zurückgeliefert. Hier ist nicht ganz klar, ob das einfach nur "kein
Wert vorhanden" ist oder eigentlich ein Fehlerzustand?
level.getTileAt() kann offenbar null zurückliefern, wenn kein Feld an der
Position vorhanden ist. Hier wird null wieder als "kein Wert vorhanden"
genutzt, was dann nachfolgende null-Checks notwendig macht (Entfernen aller
null-Referenzen aus der Liste).level.findPath() kann auch wieder null zurückliefern, wenn kein Pfad berechnet
werden konnte. Hier ist wieder nicht ganz klar, ob das einfach nur "kein Wert
vorhanden" ist oder eigentlich ein Fehlerzustand? Man könnte beispielsweise in
diesem Fall ein anderes Feld probieren?
Der Aufrufer bekommt also eine NullPointer-Exception, wenn der übergebene Parameter
entity nicht vorhanden ist oder den Wert null, wenn in der Methode etwas schief
lief oder schlicht kein Pfad berechnet werden konnte oder tatsächlich einen Pfad.
Damit wird der Aufrufer gezwungen, den Rückgabewert vor der Verwendung zu untersuchen.
Allein in dieser einen kurzen Methode macht null so viele extra Prüfungen notwendig
und den Code dadurch schwerer lesbar und fehleranfälliger! null wird als (unvollständige)
Initialisierung und als Rückgabewert und für den Fehlerfall genutzt, zusätzlich ist
die Semantik von null nicht immer klar.
(Anmerkung: Der Gebrauch von null hat nicht wirklich etwas mit "der Natur eines ECS"
zu tun. Die Methode wurde mittlerweile komplett überarbeitet und ist in der hier gezeigten
Form glücklicherweise nicht mehr zu finden.)
Entsprechend hat sich in diesem Review
die nachfolgende Diskussion ergeben:


Erzeugen von Optional-Objekten
Konstruktor ist private ...
-
"Kein Wert": Optional.empty()
-
Verpacken eines non-null Elements: Optional.of()
(NullPointerException wenn Argument null!)
-
Verpacken eines "unsicheren"/beliebigen Elements: Optional.ofNullable()
- Liefert verpacktes Element, oder
Optional.empty(), falls Element null war
Es sollte in der Praxis eigentlich nur wenige Fälle geben, wo ein Aufruf von
Optional.of() sinnvoll ist. Ebenso ist Optional.empty() nur selten sinnvoll.
Stattdessen sollte stets Optional.ofNullable() verwendet werden.
null kann nicht nicht in Optional<T> verpackt werden!
(Das wäre dann eben Optional.empty().)
LSF liefert jetzt Optional zurück
public class LSF {
private Set<Studi> sl;
public Optional<Studi> getBestStudi() throws NullPointerException {
// Fehler: Es gibt noch keine Sammlung
if (sl == null) throw new NullPointerException("There ain't any collection");
Studi best = null;
for (Studi s : sl) {
if (best == null) best = s;
if (best.credits() < s.credits()) best = s;
}
// Entweder Optional.empty() (wenn best==null) oder Optional.of(best) sonst
return Optional.ofNullable(best);
}
}
Das Beispiel soll verdeutlichen, dass man im Fehlerfall nicht einfach null oder
Optional.empty() zurückliefern soll, sondern eine passende Exception werfen soll.
Wenn die Liste aber leer ist, stellt dies keinen Fehler dar! Es handelt sich um den
Fall "kein Wert vorhanden". In diesem Fall wird statt null nun ein Optional.empty()
zurückgeliefert, also ein Objekt, auf dem der Aufrufer die üblichen Methoden aufrufen
kann.
Zugriff auf Optional-Objekte
In der funktionalen Programmierung gibt es schon lange das Konzept von Optional,
in Haskell ist dies beispielsweise die Monade Maybe. Allerdings ist die Einbettung
in die Sprache von vornherein mit berücksichtigt worden, insbesondere kann man hier
sehr gut mit Pattern Matching in der Funktionsdefinition auf den verpackten Inhalt
reagieren.
In Java gibt es die Methode Optional#isEmpty(), die einen Boolean zurückliefert und
prüft, ob es sich um ein leeres Optional handelt oder ob hier ein Wert "verpackt" ist.
Für den direkten Zugriff auf die Werte gibt es die Methoden Optional#orElseThrow()
und Optional#orElse(). Damit kann man auf den verpackten Wert zugreifen, oder es
wird eine Exception geworfen bzw. ein Ersatzwert geliefert.
Zusätzlich gibt es Optional#isPresent(), die als Parameter ein java.util.function.Consumer
erwartet, also ein funktionales Interface mit einer Methode void accept(T), die das
Objekt verarbeitet.
Studi best;
// Testen und dann verwenden
if (!lsf.getBestStudi().isEmpty()) {
best = lsf.getBestStudi().get();
// mach was mit dem Studi ...
}
// Arbeite mit Consumer
lsf.getBestStudi().ifPresent(studi -> {
// mach was mit dem Studi ...
});
// Studi oder Alternative (wenn Optional.empty())
best = lsf.getBestStudi().orElse(anne);
// Studi oder NoSuchElementException (wenn Optional.empty())
best = lsf.getBestStudi().orElseThrow();
Es gibt noch eine Methode get(), die so verhält wie orElseThrow(). Da man diese
Methode vom Namen her schnell mit einem Getter verwechselt, ist sie mittlerweile
deprecated.
Anmerkung: Da getBestStudi() eine NullPointerException werfen kann, sollte der
Aufruf möglicherweise in ein try/catch verpackt werden. Dito für orElseThrow().
Einsatz mit Stream-API
public class LSF {
...
public Optional<Studi> getBestStudi() throws NullPointerException {
if (sl == null) throw new NullPointerException("There ain't any collection");
return sl.stream()
.sorted((s1, s2) -> s2.credits() - s1.credits())
.findFirst();
}
}
public static void main(String... args) {
...
String name = lsf.getBestStudi()
.map(Studi::name)
.orElseThrow();
}
Im Beispiel wird in getBestStudi() die Sammlung als Stream betrachtet, über die
Methode sorted() und den Lamda-Ausdruck für den Comparator sortiert ("falsch"
herum: absteigend in den Credits der Studis in der Sammlung), und findFirst()
ist die terminale Operation auf dem Stream, die ein Optional<Studi> zurückliefert:
entweder den Studi mit den meisten Credits (verpackt in Optional<Studi>) oder
Optional.empty(), wenn es überhaupt keine Studis in der Sammlung gab.
In main() wird dieses Optional<Studi> mit den Stream-Methoden von Optional<T>
bearbeitet, zunächst mit Optional#map(). Man braucht nicht selbst prüfen, ob das
von getBestStudi() erhaltene Objekt leer ist oder nicht, da dies von Optional#map()
erledigt wird: Es wendet die Methodenreferenz auf den verpackten Wert an (sofern
dieser vorhanden ist) und liefert damit den Namen des Studis als Optional<String>
verpackt zurück. Wenn es keinen Wert, also nur Optional.empty() von getBestStudi()
gab, dann ist der Rückgabewert von Optional#map() ein Optional.empty(). Wenn
der Name, also der Rückgabewert von Studi::name, null war, dann wird ebenfalls
ein Optional.empty() zurückgeliefert. Dadurch wirft orElseThrow() dann eine
NoSuchElementException. Man kann also direkt mit dem String name weiterarbeiten
ohne extra null-Prüfung - allerdings will man noch ein Exception-Handling einbauen
(dies fehlt im obigen Beispiel aus Gründen der Übersicht) ...
Weitere Optionals
Für die drei primitiven Datentypen int, long und double gibt es passende
Wrapper-Klassen von Optional<T>: OptionalInt, OptionalLong und OptionalDouble.
Diese verhalten sich analog zu Optional<T>, haben aber keine Methode ofNullable(),
da dies hier keinen Sinn ergeben würde: Die drei primitiven Datentypen repräsentieren
Werte - diese können nicht null sein.
Regeln für Optional
-
Nutze Optional nur als Rückgabe für "kein Wert vorhanden"
Optional ist nicht als Ersatz für eine null-Prüfung o.ä.
gedacht, sondern als Repräsentation, um auch ein "kein Wert
vorhanden" zurückliefern zu können.
-
Nutze nie null für eine Optional-Variable oder einen Optional-Rückgabewert
Wenn man ein Optional als Rückgabe bekommt, sollte das
niemals selbst eine null-Referenz sein. Das macht das
gesamte Konzept kaputt!
Nutzen Sie stattdessen Optional.empty().
-
Nutze Optional.ofNullable() zum Erzeugen eines Optional
Diese Methode verhält sich "freundlich" und erzeugt automatisch
ein Optional.empty(), wenn das Argument null ist. Es gibt
also keinen Grund, dies mit einer Fallunterscheidung selbst
erledigen zu wollen.
Bevorzugen Sie Optional.ofNullable() vor einer manuellen
Fallunterscheidung und dem entsprechenden Einsatz von
Optional.of() und Optional.empty().
-
Erzeuge keine Optional als Ersatz für die Prüfung auf null
Wenn Sie auf null prüfen müssen, müssen Sie auf null prüfen.
Der ersatzweise Einsatz von Optional macht es nur komplexer -
prüfen müssen Sie hinterher ja immer noch.
-
Nutze Optional nicht in Attributen, Methoden-Parametern und Sammlungen
Nutzen Sie Optional vor allem für Rückgabewerte.
Attribute sollten immer direkt einen Wert haben oder null,
analog Parameter von Methoden o.ä. ... Hier hilft Optional
nicht, Sie müssten ja trotzdem eine null-Prüfung machen,
nur eben dann über den Optional, wodurch dies komplexer und
schlechter lesbar wird.
Aus einem ähnlichen Grund sollten Sie auch in Sammlungen
keine Optional speichern!
-
Vermeide den direkten Zugriff (ifPresent(), orElseThrow() ...)
Der direkte Zugriff auf ein Optional entspricht dem
Prüfen auf null und dann dem Auspacken. Dies ist nicht
nur Overhead, sondern auch schlechter lesbar.
Vermeiden Sie den direkten Zugriff und nutzen Sie Optional
mit den Stream-Methoden. So ist dies von den Designern
gedacht.
Interessante Links
Wrap-Up
Optional als Rückgabe für "kein Wert vorhanden"
-
Optional.ofNullable(): Erzeugen eines Optional
- Entweder Objekt "verpackt" (Argument !=
null)
- Oder
Optional.empty() (Argument == null)
-
Prüfen mit isEmpty() und ifPresent()
-
Direkter Zugriff mit ifPresent(), orElse() und orElseThrow()
-
Stream-API: map(), filter(), flatMap(), ...
-
Attribute, Parameter und Sammlungen: nicht Optional nutzen
-
Kein Ersatz für null-Prüfung!
Schöne Doku: "Using Optionals".
Challenges
Katzen-Café
In den Vorgaben
finden Sie eine Implementierung für ein Katzencafé.
Verändern Sie die Vorgaben so, dass möglich wenig null verwendet wird.
Setzen Sie dazu gezielt und sinnvoll Exception-Handling und Optional<T> ein.
Ergänzen Sie die Vorgaben um ein ausführliches Beispiel und bevölkern Sie das Café mit verschiedenen Katzen und geben Sie diese mit Hilfe der verschiedenen Methoden aus.
Begründen Sie die Relevanz der verbleibenden null-Vorkommen im Code.
String-Handling
Können Sie den folgenden Code so umschreiben, dass Sie statt der if-Abfragen und der einzelnen direkten Methodenaufrufe
die Stream-API und Optional<T> nutzen?
String format(final String text, String replacement) {
if (text.isEmpty()) {
return "";
}
final String trimmed = text.trim();
final String withSpacesReplaced = trimmed.replaceAll(" +", replacement);
return replacement + withSpacesReplaced + replacement;
}
Ein Aufruf format(" Hello World ... ", "_"); liefert den String "_Hello_World_..._".
Record-Klassen
TL;DR
Häufig schreibt man relativ viel Boiler Plate Code, um einfach ein paar Daten plus den
Konstruktor und die Zugriffsmethoden zu kapseln. Und selbst wenn die IDE dies zum Teil
abnehmen kann - lesen muss man diesen Overhead trotzdem noch.
Für den Fall von Klassen mit final Attributen wurden in Java14 die Record-Klassen
eingeführt. Statt dem Schlüsselwort class wird das neue Schlüsselwort record verwendet.
Nach dem Klassennamen kommen in runden Klammern die "Komponenten" - eine Auflistung der
Parameter für den Standardkonstruktor (Typ, Name). Daraus wird automatisch ein "kanonischer
Konstruktor" mit exakt diesen Parametern generiert. Es werden zusätzlich private final
Attribute generiert für jede Komponente, und diese werden durch den kanonischen Konstruktor
gesetzt. Außerdem wird für jedes Attribut automatisch ein Getter mit dem Namen des Attributs
generiert (also ohne den Präfix "get").
Beispiel:
public record StudiR(String name, int credits) {}
Der Konstruktor und die Getter können überschrieben werden, es können auch eigene Methoden
definiert werden (eigene Konstruktoren müssen den kanonischen Konstruktor aufrufen). Es
gibt außer den über die Komponenten definierten Attribute keine weiteren Attribute. Da eine
Record-Klasse intern von java.lang.Record ableitet, kann eine Record-Klasse nicht von
weiteren Klassen ableiten (erben). Man kann aber beliebig viele Interfaces implementieren.
Record-Klassen sind implizit final, d.h. man nicht von Record-Klassen erben.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Record-Klassen sind final
- (K2) Record-Klassen haben einen kanonischen Konstruktor
- (K2) Die Attribute von Record-Klassen sind final und werden automatisch angelegt und über den Konstruktor gesetzt
- (K2) Die Getter in Record-Klassen haben die Namen und Typen der Komponenten, also keinen Präfix 'get'
- (K2) Der kanonische Konstruktor kann ergänzt werden
- (K2) Es können weitere Methoden definiert werden
- (K2) Record-Klassen können nicht von anderen Klassen erben, können aber Interfaces implementieren
- (K3) Einsatz von Record-Klassen
Motivation; Klasse Studi
public class Studi {
private final String name;
private final int credits;
public Studi(String name, int credits) {
this.name = name;
this.credits = credits;
}
public String getName() {
return name;
}
public int getCredits() {
return credits;
}
}
Klasse Studi als Record
public record StudiR(String name, int credits) {}
-
Immutable Klasse mit Feldern String name und int credits
=> "(String name, int credits)" werden "Komponenten" des Records genannt
-
Standardkonstruktor setzt diese Felder ("Kanonischer Konstruktor")
-
Getter für beide Felder:
public String name() { return this.name; }
public int credits() { return this.credits; }
Record-Klassen wurden in Java14 eingeführt und werden immer wieder in
neuen Releases erweitert/ergänzt.
Der kanonische Konstruktor hat das Aussehen wie die Record-Deklaration, im
Beispiel also public StudiR(String name, int credits). Dabei werden die
Komponenten über eine Kopie der Werte initialisiert.
Für die Komponenten werden automatisch private Attribute mit dem selben
Namen angelegt.
Für die Komponenten werden automatisch Getter angelegt. Achtung: Die Namen
entsprechen denen der Komponenten, es fehlt also der übliche "get"-Präfix!
Eigenschaften und Einschränkungen von Record-Klassen
-
Records erweitern implizit die Klasse java.lang.Record:
Keine andere Klassen mehr erweiterbar! (Interfaces kein Problem)
-
Record-Klassen sind implizit final
-
Keine weiteren (Instanz-) Attribute definierbar (nur die Komponenten)
-
Keine Setter definierbar für die Komponenten: Attribute sind final
-
Statische Attribute mit Initialisierung erlaubt
Records: Prüfungen im Konstruktor
Der Konstruktor ist erweiterbar:
public record StudiS(String name, int credits) {
public StudiS(String name, int credits) {
if (name == null) { throw new IllegalArgumentException("Name cannot be null!"); }
else { this.name = name; }
if (credits < 0) { this.credits = 0; }
else { this.credits = credits; }
}
}
In dieser Form muss man die Attribute selbst setzen.
Alternativ kann man die "kompakte" Form nutzen:
public record StudiT(String name, int credits) {
public StudiT {
if (name == null) { throw new IllegalArgumentException("Name cannot be null!"); }
if (credits < 0) { credits = 0; }
}
}
In der kompakten Form kann man nur die Werte der Parameter des Konstruktors ändern.
Das Setzen der Attribute ergänzt der Compiler nach dem eigenen Code.
Es sind weitere Konstruktoren definierbar, diese müssen den kanonischen Konstruktor
aufrufen:
public StudiT() {
this("", 42);
}
Getter und Methoden
Getter werden vom Compiler automatisch generiert. Dabei entsprechen die Methoden-Namen
den Namen der Attribute:
public record StudiR(String name, int credits) {}
public static void main(String... args) {
StudiR r = new StudiR("Sabine", 75);
int x = r.credits();
String y = r.name();
}
Getter überschreibbar und man kann weitere Methoden definieren:
public record StudiT(String name, int credits) {
public int credits() { return credits + 42; }
public void wuppie() { System.out.println("WUPPIE"); }
}
Die Komponenten/Attribute sind aber final und können nicht über Methoden
geändert werden!
Beispiel aus den Challenges
In den Challenges zum Thema Optional gibt es die Klasse Katze in den
Vorgaben.
Die Katze wurde zunächst "klassisch" modelliert: Es gibt drei Eigenschaften name,
gewichtund lieblingsBox. Ein Konstruktor setzt diese Felder und es gibt drei
Getter für die einzelnen Eigenschaften. Das braucht 18 Zeilen Code (ohne Kommentare
Leerzeilen). Zudem erzeugt der Boilerplate-Code relativ viel "visual noise", so dass
der eigentliche Kern der Klasse schwerer zu erkennen ist.
In einem Refactoring wurde diese Klasse durch eine äquivalente Record-Klasse ersetzt,
die nur noch 2 Zeilen Code (je nach Code-Style auch nur 1 Zeile) benötigt. Gleichzeitig
wurde die Les- und Wartbarkeit deutlich verbessert.

Wrap-Up
- Records sind immutable Klassen:
final Attribute (entsprechend den Komponenten)- Kanonischer Konstruktor
- Automatische Getter (Namen wie Komponenten)
- Konstruktoren und Methoden können ergänzt/überschrieben werden
- Keine Vererbung von Klassen möglich (kein
extends)
Schöne Doku: "Using Record to Model Immutable Data".
Quellen
- [LernJava] Learn Java
Oracle Corporation, 2022.
Tutorials \> Using Record to Model Immutable Data
Interfaces: Default-Methoden
TL;DR
Seit Java8 können Methoden in Interfaces auch fertig implementiert sein: Sogenannte
Default-Methoden.
Dazu werden die Methoden mit dem neuen Schlüsselwort default gekennzeichnet. Die
Implementierung wird an die das Interface implementierenden Klassen (oder Interfaces)
vererbt und kann bei Bedarf überschrieben werden.
Da eine Klasse von einer anderen Klasse erben darf, aber mehrere Interfaces implementieren
kann, könnte es zu einer Mehrfachvererbung einer Methode kommen: Eine Methode könnte
beispielsweise in verschiedenen Interfaces als Default-Methode angeboten werden, und wenn
eine Klasse diese Interfaces implementiert, steht eine Methode mit der selben Signatur
auf einmal mehrfach zur Verfügung. Dies muss (u.U. manuell) aufgelöst werden.
Auflösung von Mehrfachvererbung:
- Regel 1: Klassen gewinnen
- Regel 2: Sub-Interfaces gewinnen
- Regel 3: Methode explizit auswählen
Aktuell ist der Unterschied zu abstrakten Klassen: Interfaces können keinen Zustand
haben, d.h. keine Attribute/Felder.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Interfaces mit Default-Methoden, Unterschied zu abstrakten Klassen
- (K2) Problem der Mehrfachvererbung
- (K3) Erstellen von Interfaces mit Default-Methoden
- (K3) Regeln zum Auflösen der Mehrfachvererbung
Problem: Etablierte API (Interfaces) erweitern
interface Klausur {
void anmelden(Studi s);
void abmelden(Studi s);
}
=> Nachträglich noch void schreiben(Studi s); ergänzen?
Wenn ein Interface nachträglich erweitert wird, müssen alle Kunden (also
alle Klassen, die das Interface implementieren) auf die neuen Signaturen
angepasst werden. Dies kann viel Aufwand verursachen und API-Änderungen
damit unmöglich machen.
Default-Methoden: Interfaces mit Implementierung
Seit Java8 können Interfaces auch Methoden implementieren.
Es gibt zwei Varianten: Default-Methoden und statische Methoden.
interface Klausur {
void anmelden(Studi s);
void abmelden(Studi s);
default void schreiben(Studi s) {
... // Default-Implementierung
}
default void wuppie() {
throw new java.lang.UnsupportedOperationException();
}
}
Methoden können in Interfaces seit Java8 implementiert werden. Für Default-Methoden
muss das Schlüsselwort default vor die Signatur gesetzt werden. Klassen, die das
Interface implementieren, können diese Default-Implementierung erben oder selbst
neu implementieren (überschreiben). Alternativ kann die Klasse eine Default-Methode
neu deklarieren und wird damit zur abstrakten Klasse.
Dies ähnelt abstrakten Klassen. Allerdings kann in abstrakten Klassen neben dem
Verhalten (implementierten Methoden) auch Zustand über die Attribute gespeichert werden.
Problem: Mehrfachvererbung
Drei Regeln zum Auflösen bei Konflikten:
- Klassen gewinnen:
Methoden aus Klasse oder Superklasse haben höhere Priorität als Default-Methoden
- Sub-Interfaces gewinnen:
Methode aus am meisten spezialisiertem Interface mit Default-Methode wird gewählt
Beispiel: Wenn
B extends A dann ist B spezialisierter als A
- Sonst: Klasse muss Methode explizit auswählen:
Methode überschreiben und gewünschte (geerbte) Variante aufrufen:
X.super.m(...) (X ist das gewünschte Interface)
Auf den folgenden Folien wird dies anhand kleiner Beispiele verdeutlicht.
Auflösung Mehrfachvererbung: 1. Klassen gewinnen
interface A {
default String hello() { return "A"; }
}
class C {
public String hello() { return "C"; }
}
class E extends C implements A {}
/** Mehrfachvererbung: 1. Klassen gewinnen */
public class DefaultTest1 {
public static void main(String... args) {
String e = new E().hello();
}
}
Die Klasse E erbt sowohl von Klasse C als auch vom Interface A die Methode hello()
(Mehrfachvererbung). In diesem Fall "gewinnt" die Implementierung aus Klasse C.
1. Regel: Klassen gewinnen immer. Deklarationen einer Methode in einer Klasse oder
einer Oberklasse haben Vorrang von allen Default-Methoden.
Auflösung Mehrfachvererbung: 2. Sub-Interfaces gewinnen
interface A {
default String hello() { return "A"; }
}
interface B extends A {
@Override default String hello() { return "B"; }
}
class D implements A, B {}
/** Mehrfachvererbung: 2. Sub-Interfaces gewinnen */
public class DefaultTest2 {
public static void main(String... args) {
String e = new D().hello();
}
}
Die Klasse D erbt sowohl vom Interface A als auch vom Interface B die Methode hello()
(Mehrfachvererbung). In diesem Fall "gewinnt" die Implementierung aus Klasse B: Interface
B ist spezialisierter als A.
2. Regel: Falls Regel 1 nicht zutrifft, gewinnt die Default-Methode, die am meisten
spezialisiert ist.
Auflösung Mehrfachvererbung: 3. Methode explizit auswählen
interface A {
default String hello() { return "A"; }
}
interface B {
default String hello() { return "B"; }
}
class D implements A, B {
@Override public String hello() { return A.super.hello(); }
}
/** Mehrfachvererbung: 3. Methode explizit auswählen */
public class DefaultTest3 {
public static void main(String... args) {
String e = new D().hello();
}
}
Die Klasse D erbt sowohl vom Interface A als auch vom Interface B die Methode hello()
(Mehrfachvererbung). In diesem Fall muss zur Auflösung die Methode in D neu implementiert
werden und die gewünschte geerbte Methode explizit aufgerufen werden. (Wenn dies unterlassen
wird, führt das selbst bei Nicht-Nutzung der Methode hello() zu einem Compiler-Fehler!)
Achtung: Der Aufruf der Default-Methode aus Interface A erfolgt mit A.super.hello();
(nicht einfach durch A.hello();)!
3. Regel: Falls weder Regel 1 noch 2 zutreffen bzw. die Auflösung noch uneindeutig ist,
muss man manuell durch die explizite Angabe der gewünschten Methode auflösen.
Quiz: Was kommt hier raus?
interface A {
default String hello() { return "A"; }
}
interface B extends A {
@Override default String hello() { return "B"; }
}
class C implements B {
@Override public String hello() { return "C"; }
}
class D extends C implements A, B {}
/** Quiz Mehrfachvererbung */
public class DefaultTest {
public static void main(String... args) {
String e = new D().hello(); // ???
}
}
Die Klasse D erbt sowohl von Klasse C als auch von den Interfaces A und B die Methode
hello() (Mehrfachvererbung). In diesem Fall "gewinnt" die Implementierung aus Klasse C: Klassen
gewinnen immer (Regel 1).
Statische Methoden in Interfaces
public interface Collection<E> extends Iterable<E> {
boolean add(E e);
...
}
public class Collections {
private Collections() { }
public static <T> boolean addAll(Collection<? super T> c, T... elements) {...}
...
}
Typisches Pattern in Java: Interface plus Utility-Klasse (Companion-Klasse) mit statischen Hilfsmethoden
zum einfacheren Umgang mit Instanzen des Interfaces (mit Objekten, deren Klasse das Interface implementiert).
Beispiel: Collections ist eine Hilfs-Klasse zum Umgang mit Collection-Objekten.
Seit Java8 können in Interfaces neben Default-Methoden auch statische Methoden implementiert werden.
Die Hilfsmethoden können jetzt ins Interface wandern => Utility-Klassen werden obsolet ... Aus
Kompatibilitätsgründen würde man die bisherige Companion-Klasse weiterhin anbieten, wobei die Implementierungen
auf die statischen Methoden im Interface verweisen (SKIZZE, nicht real!):
public interface CollectionX<E> extends Iterable<E> {
boolean add(E e);
static <T> boolean addAll(CollectionX<? super T> c, T... elements) { ... }
...
}
public class CollectionsX {
public static <T> boolean addAll(CollectionX<? super T> c, T... elements) {
return CollectionX.addAll(c, elements); // Verweis auf Interface
}
...
}
Interfaces vs. Abstrakte Klassen
-
Abstrakte Klassen: Schnittstelle und Verhalten und Zustand
-
Interfaces:
- vor Java 8 nur Schnittstelle
- ab Java 8 Schnittstelle und Verhalten
Unterschied zu abstrakten Klassen: Kein Zustand, d.h. keine Attribute
-
Design:
- Interfaces sind beinahe wie abstrakte Klassen, nur ohne Zustand
- Klassen können nur von einer (abstrakten) Klasse erben, aber
viele Interfaces implementieren
Wrap-Up
Seit Java8: Interfaces mit Implementierung: Default-Methoden
- Methoden mit dem Schlüsselwort
default können Implementierung im Interface haben
- Die Implementierung wird vererbt und kann bei Bedarf überschrieben werden
- Auflösung von Mehrfachvererbung:
- Regel 1: Klassen gewinnen
- Regel 2: Sub-Interfaces gewinnen
- Regel 3: Methode explizit auswählen
- Unterschied zu abstrakten Klassen: Kein Zustand
Challenges
Erklären Sie die Code-Schnipsel in der
Vorgabe
und die jeweils entstehenden Ausgaben.
Quellen
- [Urma2014] Java 8 in Action: Lambdas, Streams, and Functional-Style Programming
Urma, R.-G. und Fusco, M. und Mycroft, A., Manning Publications, 2014. ISBN 978-1-6172-9199-9.
Kapitel 9: Default Methods
Subsections of Programmiermethoden und Clean Code
Javadoc
TL;DR
Mit Javadoc kann aus speziell markierten Block-Kommentaren eine externe Dokumentation im HTML-Format
erzeugt werden. Die Block-Kommentare, auf die das im JDK enthaltene Programm javadoc reagiert,
beginnen mit /** (also einem zusätzlichen Stern, der für den Java-Compiler nur das erste Kommentarzeichen
ist).
Die erste Zeile eines Javadoc-Kommentars ist eine "Zusammenfassung" und an fast allen Stellen der
generierten Doku sichtbar. Diese Summary sollte kurz gehalten werden und eine Idee vermitteln, was
die Klasse oder die Methode oder das Attribut macht.
Für die Dokumentation von Parametern, Rückgabetypen, Exceptions und veralteten Elementen existieren
spezielle Annotationen: @param, @return, @throws und @deprecated.
Als Faustregel gilt: Es werden alle public und protected Elemente (Klassen, Methoden, Attribute)
mit Javadoc kommentiert. Alle nicht-öffentlichen Elemente bekommen normale Java-Kommentare (Zeilen- oder
Blockkommentare).
Videos (HSBI-Medienportal)
Lernziele
- (K2) Ziel der Javadoc-Dokumentation verstehen
- (K2) Typischen Aufgabe von Javadoc-Kommentaren verstehen
- (K3) Dokumentation öffentlich sichtbarer Elemente mit Javadoc
- (K3) Schreiben einer sinnvollen Summary
- (K3) Einsatz von Annotationen zur Dokumentation von Parametern, Rückgabetypen, Exceptions, veralteten Elementen
Dokumentation mit Javadoc
/**
* Beschreibung Beschreibung (Summary).
*
* <p>Hier kommt dann ein laengerer Text, der die Dinge
* bei Bedarf etwas ausfuehrlicher erklaert.
*/
public void wuppie() {}
Javadoc-Kommentare sind (aus Java-Sicht) normale Block-Kommentare, wobei der Beginn mit
/** eingeleitet wird. Dieser Beginn ist für das Tool javadoc (Bestandteil des JDK,
genau wie java und javac) das Signal, dass hier ein Kommentar anfängt, den das
Tool in eine HTML-Dokumentation übersetzen soll.
Typischerweise wird am Anfang jeder Kommentarzeile ein * eingefügt; dieser wird von
Javadoc ignoriert.
Sie können neben normalem Text und speziellen Annotationen auch HTML-Elemente wie <p>
und <code> oder <ul> nutzen.
Mit javadoc *.java können Sie in der Konsole aus den Java-Dateien die Dokumentation
generieren lassen. Oder Sie geben das in Ihrer IDE in Auftrag ... (die dann diesen
Aufruf gern für Sie tätigt).
Standard-Aufbau
/**
* Beschreibung Beschreibung (Summary).
*
* <p> Hier kommt dann ein laengerer Text, der die Dinge
* bei Bedarf etwas ausfuehrlicher erklaert.
*
* @param date Tag, Wert zw. 1 .. 31
* @return Anzahl der Sekunden seit 1.1.1970
* @throws NumberFormatException
* @deprecated As of JDK version 1.1
*/
public int setDate(int date) {
setField(Calendar.DATE, date);
}
- Erste Zeile bei Methoden/Attributen geht in die generierte "Summary" in der Übersicht,
der Rest in die "Details"
- Die "Summary" sollte kein kompletter Satz sein, wird aber wie ein Satz geschrieben
(Groß beginnen, mit Punkt beenden). Es sollte nicht beginnen mit "Diese Methode
macht ..." oder "Diese Klasse ist ...". Ein gutes Beispiel wäre "Berechnet die
Steuerrückerstattung."
- Danach kommen die Details, die in der generierten Dokumentation erst durch
Aufklappen der Elemente sichtbar sind. Erklären Sie, wieso der Code was machen
soll und welche Designentscheidungen getroffen wurden (und warum).
- Leerzeilen gliedern den Text in Absätze. Neue Absätze werden mit einem
<p> eingeleitet.
(Ausnahmen: Wenn der Text mit <ul> o.ä. beginnt oder der Absatz mit den Block-Tags.)
- Die "Block-Tags"
@param, @return, @throws, @deprecated werden durch einen
Absatz von der restlichen Beschreibung getrennt und tauchen in exakt dieser Reihenfolge
auf. Die Beschreibung dieser Tags ist nicht leer - anderenfalls lässt man das Tag weg.
Falls die Zeile für die Beschreibung nicht reicht, wird umgebrochen und die Folgezeile
mit vier Leerzeichen (beginnend mit dem @) eingerückt.
- Mit
@param erklären Sie die Bedeutung eines Parameters (von links nach rechts) einer
Methode. Beispiel: @param date Tag, Wert zw. 1 .. 31. Wiederholen Sie dies für
jeden Parameter.
- Mit
@return beschreiben Sie den Rückgabetyp/-wert. Beispiel:
@return Anzahl der Sekunden seit 1.1.1970.
Bei Rückgabe von void wird diese Beschreibung weggelassen (die Beschreibung wäre
dann ja leer).
- Mit
@throws geben Sie an, welche "checked" Exceptions die Methode wirft.
- Mit
@deprecated können Sie im Kommentar sagen, dass ein Element veraltet ist und
möglicherweise mit der nächsten Version o.ä. entfernt wird. (siehe nächste Folie)
=> Dies sind die Basis-Regeln aus dem populären Google-Java-Style [googlestyleguide].
Veraltete Elemente
/**
* Beschreibung Beschreibung Beschreibung.
*
* @deprecated As of v102, replaced by <code>Foo.fluppie()</code>.
*/
@Deprecated
public void wuppie() {}
- Annotation zum Markieren als "veraltet" (in der generierten Dokumentation):
@deprecated
- Für Sichtbarkeit zur Laufzeit bzw. im Tooling/IDE: normale Code-Annotation
@Deprecated
Dies ist ein guter Weg, um Elemente einer öffentlichen API als "veraltet" zu
kennzeichnen. Üblicherweise wird diese Kennzeichnung für einige wenige Releases
beibehalten und danach das veraltete Element aus der API entfernt.
Autoren, Versionen, ...
/**
* Beschreibung Beschreibung Beschreibung.
*
* @author Dagobert Duck
* @version V1
* @since schon immer
*/
- Annotationen für Autoren und Version:
@author, @version, @since
Diese Annotationen finden Sie vor allem in Kommentaren zu Packages oder Klassen.
Was muss kommentiert werden?
-
Alle public Klassen
-
Alle public und protected Elemente der Klassen
-
Ausnahme: @Override (An diesen Methoden kann, aber muss nicht kommentiert werden.)
Alle anderen Elemente bei Bedarf mit normalen Kommentaren versehen.
Beispiel aus dem JDK: ArrayList
Schauen Sie sich gern mal Klassen aus der Java-API an, beispielsweise eine java.util.ArrayList:
Best Practices: Was beschreibe ich eigentlich?
Unter Documentation Best Practices
finden Sie eine sehr gute Beschreibung, was das Ziel der Dokumentation sein sollte. Versuchen Sie, dieses zu erreichen!
Wrap-Up
-
Javadoc-Kommentare sind normale Block-Kommentare beginnend mit /**
-
Generierung der HTML-Dokumentation mit javadoc *.java
-
Erste Zeile ist eine Zusammenfassung (fast immer sichtbar)
-
Längerer Text danach als "Description" einer Methode/Klasse
-
Annotationen für besondere Elemente: @param, @return, @throws, @deprecated
-
Faustregel: Alle public und protected Elemente mit Javadoc kommentieren!
Logging
TL;DR
Im Paket java.util.logging findet sich eine einfache Logging-API.
Über die Methode getLogger() der Klasse Logger (Factory-Method-Pattern)
kann ein (neuer) Logger erzeugt werden, dabei wird über den String-Parameter
eine Logger-Hierarchie aufgebaut analog zu den Java-Package-Strukturen. Der
oberste Logger (der "Root-Logger") hat den leeren Namen.
Jeder Logger kann mit einem Log-Level (Klasse Level) eingestellt werden;
Log-Meldungen unterhalb des eingestellten Levels werden verworfen.
Vom Logger nicht verworfene Log-Meldungen werden an den bzw. die Handler des
Loggers und (per Default) an den Eltern-Logger weiter gereicht. Die Handler
haben ebenfalls ein einstellbares Log-Level und verwerfen alle Nachrichten
unterhalb der eingestellten Schwelle. Zur tatsächlichen Ausgabe gibt man einem
Handler noch einen Formatter mit. Defaultmäßig hat nur der Root-Logger einen
Handler.
Der Root-Logger (leerer String als Name) hat als Default-Level (wie auch sein
Console-Handler) "Info" eingestellt.
Nachrichten, die durch Weiterleitung nach oben empfangen wurden, werden nicht
am Log-Level des empfangenden Loggers gemessen, sondern akzeptiert und an die
Handler des Loggers und (sofern nicht deaktiviert) an den Elternlogger weitergereicht.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Nutzung der Java Logging API im Paket
java.util.logging - (K3) Erstellung eigener Handler und Formatter
Wie prüfen Sie die Werte von Variablen/Objekten?
-
Debugging
- Beeinflusst Code nicht
- Kann schnell komplex und umständlich werden
- Sitzung transient - nicht wiederholbar
-
"Poor-man's-debugging" (Ausgaben mit System.out.println)
- Müssen irgendwann entfernt werden
- Ausgabe nur auf einem Kanal (Konsole)
- Keine Filterung nach Problemgrad - keine Unterscheidung
zwischen Warnungen, einfachen Informationen, ...
-
Logging
- Verschiedene (Java-) Frameworks:
java.util.logging (JDK), log4j (Apache), SLF4J, Logback, ...
Java Logging API - Überblick
Paket java.util.logging

Eine Applikation kann verschiedene Logger instanziieren. Die Logger bauen
per Namenskonvention hierarchisch aufeinander auf. Jeder Logger kann selbst
mehrere Handler haben, die eine Log-Nachricht letztlich auf eine bestimmte
Art und Weise an die Außenwelt weitergeben.
Log-Meldungen werden einem Level zugeordnet. Jeder Logger und Handler hat
ein Mindest-Level eingestellt, d.h. Nachrichten mit einem kleineren Level
werden verworfen.
Zusätzlich gibt es noch Filter, mit denen man Nachrichten (zusätzlich zum
Log-Level) nach weiteren Kriterien filtern kann.
Erzeugen neuer Logger
import java.util.logging.Logger;
Logger l = Logger.getLogger(MyClass.class.getName());
-
Factory-Methode der Klasse java.util.logging.Logger
public static Logger getLogger(String name);
=> Methode liefert bereits vorhandenen Logger mit diesem Namen (sonst neuen Logger)
-
Best Practice:
Nutzung des voll-qualifizierten Klassennamen: MyClass.class.getName()
- Leicht zu implementieren
- Leicht zu erklären
- Spiegelt modulares Design
- Ausgaben enthalten automatisch Hinweis auf Herkunft (Lokalität) der Meldung
- Alternativen: Funktionale Namen wie "XML", "DB", "Security"
Ausgabe von Logmeldungen
public void log(Level level, String msg);
Wichtigkeit von Logmeldungen: Stufen
=> Warum wird im Beispiel nach log.setLevel(Level.ALL); trotzdem nur
ab INFO geloggt? Wer erzeugt eigentlich die Ausgaben?!
Jemand muss die Arbeit machen ...
-
Pro Logger mehrere Handler möglich
- Logger übergibt nicht verworfene Nachrichten an Handler
- Handler haben selbst ein Log-Level (analog zum Logger)
- Handler verarbeiten die Nachrichten, wenn Level ausreichend
-
Standard-Handler: StreamHandler, ConsoleHandler, FileHandler
-
Handler nutzen zur Formatierung der Ausgabe einen Formatter
-
Standard-Formatter: SimpleFormatter und XMLFormatter
=> Warum wird im Beispiel nach dem Auskommentieren von
log.setUseParentHandlers(false); immer noch eine zusätzliche Ausgabe
angezeigt (ab INFO aufwärts)?!
Ich ... bin ... Dein ... Vater ...
Wrap-Up
Challenges
-
Schreiben Sie einen Formatter, welcher die Meldungen in folgendem Format auf der
Konsole ausgibt. Bauen Sie diesen Formatter in alle Logger ein.
------------
Logger: record.getLoggerName()
Level: record.getLevel()
Class: record.getSourceClassName()
Method: record.getSourceMethodName()
Message: record.getMessage()
------------
-
Schreiben Sie einen weiteren Formatter, welcher die Daten als Komma-separierte Werte
(CSV-Format) mit der folgenden Reihenfolge in eine Datei ausgibt (durch Anfügen
einer neuen Zeile an bereits bestehenden Inhalt). Bauen Sie diesen Formatter in den
Logger für den Ringpuffer ein.
record.getLoggerName(),record.getLevel(),record.getSourceMethodName(),record.getSourceClassName(),record.getMessage()
-
Ersetzen Sie in einem Beispielprogramm sämtliche Konsolenausgaben (System.out.println
und System.err.println) in der Vorgabe durch geeignete Logger-Aufrufe mit passendem
Log-Level.
Alle Warnungen und Fehler sollen zusätzlich in eine .csv-Datei geschrieben werden.
Auf der Konsole sollen alle Log-Meldungen ausgegeben werden.
Code Smells
TL;DR
Code entsteht nicht zum Selbstzweck, er muss von anderen Menschen leicht verstanden und
gewartet werden können: Entwickler verbringen einen wesentlichen Teil ihrer Zeit mit dem
Lesen von (fremdem) Code. Dabei helfen "Coding Conventions", die eine gewisse einheitliche
äußerliche Erscheinung des Codes vorgeben (Namen, Einrückungen, ...). Die Beachtung von
grundlegenden Programmierprinzipien hilft ebenso, die Lesbarkeit und Verständlichkeit zu
verbessern.
Code, der diese Konventionen und Regeln verletzt, zeigt sogenannte "Code Smells" oder
"Bad Smells". Das sind Probleme im Code, die noch nicht direkt zu einem Fehler führen, die
aber im Laufe der Zeit die Chance für echte Probleme deutlich erhöht.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Erkennen und Vermeiden von Code Smells
- (K3) Unterscheiden von leicht lesbarem und schwer lesbarem Code
- (K3) Programmierprinzipien anwenden, um den Code sauberer zu gestalten
- (K3) Bessere Kommentare schreiben
Code Smells: Ist das Code oder kann das weg?
class checker {
static public void CheckANDDO(DATA1 inp, int c, FH.Studi
CustD, int x, int y, int in, int out,int c1, int c2, int c3 = 4)
{
public int i; // neues i
for(i=0;i<10;i++) // fuer alle i
{
inp.kurs[0] = 10; inp.kurs[i] = CustD.cred[i]/c;
}
SetDataToPlan( CustD );
public double myI = in*2.5; // myI=in*2.5
if (c1)
out = myI; //OK
else if( c3 == 4 )
{
myI = c2 * myI;
if (c3 != 4 || true ) { // unbedingt beachten!
//System.out.println("x:"+(x++));
System.out.println("x:"+(x++)); // x++
System.out.println("out: "+out);
} }} }
Der Code im obigen Beispiel lässt sich möglicherweise kompilieren. Und
möglicherweise tut er sogar das, was er tun soll.
Dennoch: Der Code "stinkt" (zeigt Code Smells):
- Nichtbeachtung üblicher Konventionen (Coding Rules)
- Schlechte Kommentare
- Auskommentierter Code
- Fehlende Datenkapselung
- Zweifelhafte Namen
- Duplizierter Code
- "Langer" Code: Lange Methoden, Klassen, Parameterlisten, tief
verschachtelte
if/then-Bedingungen, ...
- Feature Neid
switch/case oder if/else statt Polymorphie- Globale Variablen, lokale Variablen als Attribut
- Magic Numbers
Diese Liste enthält die häufigsten "Smells" und ließe sich noch beliebig fortsetzen.
Schauen Sie mal in die unten angegebene Literatur :-)
Stinkender Code führt zu möglichen (späteren) Problemen.
Was ist guter ("sauberer") Code ("Clean Code")?
Im Grunde bezeichnet "sauberer Code" ("Clean Code") die Abwesenheit von Smells. D.h. man
könnte Code als "sauberen" Code bezeichnen, wenn die folgenden Eigenschaften erfüllt sind
(keine vollständige Aufzählung!):
- Gut ("angenehm") lesbar
- Schnell verständlich: Geeignete Abstraktionen
- Konzentriert sich auf eine Aufgabe
- So einfach und direkt wie möglich
- Ist gut getestet
In [Martin2009] lässt der Autor Robert Martin verschiedene Ikonen der SW-Entwicklung
zu diesem Thema zu Wort kommen - eine sehr lesenswerte Lektüre!
=> Jemand kümmert sich um den Code; solides Handwerk
Warum ist guter ("sauberer") Code so wichtig?
Any fool can write code that a computer can understand.
Good programmers write code that humans can understand.
Quelle: [Fowler2011, p. 15]
Auch wenn das zunächst seltsam klingt, aber Code muss auch von Menschen gelesen und
verstanden werden können. Klar, der Code muss inhaltlich korrekt sein und die jeweilige
Aufgabe erfüllen, er muss kompilieren etc. ... aber er muss auch von anderen Personen
weiter entwickelt werden und dazu gelesen und verstanden werden. Guter Code ist nicht
einfach nur inhaltlich korrekt, sondern kann auch einfach verstanden werden.
Code, der nicht einfach lesbar ist oder nur schwer verständlich ist, wird oft in der
Praxis später nicht gut gepflegt: Andere Entwickler haben (die berechtigte) Angst, etwas
kaputt zu machen und arbeiten "um den Code herum". Nur leider wird das Konstrukt dann
nur noch schwerer verständlich ...
Code Smells
Verstöße gegen die Prinzipien von Clean Code nennt man auch Code Smells: Der
Code "stinkt" gewissermaßen. Dies bedeutet nicht unbedingt, dass der Code nicht
funktioniert (d.h. er kann dennoch compilieren und die Anforderungen erfüllen).
Er ist nur nicht sauber formuliert, schwer verständlich, enthält Doppelungen etc.,
was im Laufe der Zeit die Chance für tatsächliche Probleme deutlich erhöht.
Und weil es so wichtig ist, hier gleich noch einmal:
Stinkender Code führt zu möglichen (späteren) Problemen.
"Broken Windows" Phänomen
Wenn ein Gebäude leer steht, wird es eine gewisse Zeit lang nur relativ langsam
verfallen: Die Fenster werden nicht mehr geputzt, es sammelt sich Graffiti, Gras
wächst in der Dachrinne, Putz blättert ab ...
Irgendwann wird dann eine Scheibe eingeworfen. Wenn dieser Punkt überschritten
ist, beschleunigt sich der Verfall rasant: Über Nacht werden alle erreichbaren
Scheiben eingeworfen, Türen werden zerstört, es werden sogar Brände gelegt ...
Das passiert auch bei Software! Wenn man als Entwickler das Gefühl bekommt,
die Software ist nicht gepflegt, wird man selbst auch nur relativ schlechte
Arbeit abliefern. Sei es, weil man nicht versteht, was der Code macht und sich
nicht an die Überarbeitung der richtigen Stellen traut und stattdessen die
Änderungen als weiteren "Erker" einfach dran pappt. Seit es, weil man keine Lust
hat, Zeit in ordentliche Arbeit zu investieren, weil der Code ja eh schon
schlecht ist ... Das wird mit der Zeit nicht besser ...
Maßeinheit für Code-Qualität ;-)
Es gibt eine "praxisnahe" (und nicht ganz ernst gemeinte) Maßeinheit für Code-Qualität:
Die "WTF/m" (What the Fuck per minute):
Thom Holwerda: www.osnews.com/story/19266/WTFs_.
Wenn beim Code-Review durch Kollegen viele "WTF" kommen, ist der Code offenbar nicht
in Ordnung ...
Code Smells: Nichtbeachtung von Coding Conventions
-
Richtlinien für einheitliches Aussehen
=> Andere Programmierer sollen Code schnell lesen können
- Namen, Schreibweisen
- Kommentare (Ort, Form, Inhalt)
- Einrückungen und Spaces vs. Tabs
- Zeilenlängen, Leerzeilen
- Klammern
-
Beispiele: Sun Code Conventions,
Google Java Style
-
Hinweis: Betrifft vor allem die (äußere) Form!
Code Smells: Schlechte Kommentare I
-
Ratlose Kommentare
/* k.A. was das bedeutet, aber wenn man es raus nimmt, geht's nicht mehr */
/* TODO: was passiert hier, und warum? */
Der Programmierer hat selbst nicht verstanden (und macht sich auch nicht
die Mühe zu verstehen), was er da tut! Fehler sind vorprogrammiert!
-
Redundante Kommentare: Erklären Sie, was der Code inhaltlich tun sollte (und warum)!
public int i; // neues i
for(i=0;i<10;i++)
// fuer alle i
Was würden Sie Ihrem Kollegen erklären (müssen), wenn Sie ihm/ihr den
Code vorstellen?
Wiederholen Sie nicht, was der Code tut (das kann ich ja selbst lesen),
sondern beschreiben Sie, was der Code tun sollte und warum.
Beschreiben Sie dabei auch das Konzept hinter einem Codebaustein.
Code Smells: Schlechte Kommentare II
-
Veraltete Kommentare
Hinweis auf unsauberes Arbeiten: Oft wird im Zuge der Überarbeitung von
Code-Stellen vergessen, auch den Kommentar anzupassen! Sollte beim Lesen
extrem misstrauisch machen.
-
Auskommentierter Code
Da ist jemand seiner Sache unsicher bzw. hat eine Überarbeitung nicht
abgeschlossen. Die Chance, dass sich der restliche Code im Laufe der Zeit
so verändert, dass der auskommentierte Code nicht mehr (richtig) läuft, ist
groß! Auskommentierter Code ist gefährlich und dank Versionskontrolle
absolut überflüssig!
-
Kommentare erscheinen zwingend nötig
Häufig ein Hinweis auf ungeeignete Wahl der Namen (Klassen, Methoden,
Attribute) und/oder auf ein ungeeignetes Abstraktionsniveau (beispielsweise
Nichtbeachtung des Prinzips der "Single Responsibility")!
Der Code soll im Normalfall für sich selbst sprechen: WAS wird gemacht.
Der Kommentar erklärt im Normalfall, WARUM der Code das machen soll.
-
Unangemessene Information, z.B. Änderungshistorien
Hinweise wie "wer hat wann was geändert" gehören in das Versionskontroll-
oder ins Issue-Tracking-System. Die Änderung ist im Code sowieso nicht mehr
sichtbar/nachvollziehbar!
Code Smells: Schlechte Namen und fehlende Kapselung
public class Studi extends Person {
public String n;
public int c;
public void prtIf() { ... }
}
Nach drei Wochen fragen Sie sich, was n oder c oder Studi#prtIf() wohl
sein könnte! (Ein anderer Programmierer fragt sich das schon beim ersten
Lesen.) Klassen und Methoden sollten sich erwartungsgemäß verhalten.
Wenn Dinge öffentlich angeboten werden, muss man damit rechnen, dass andere
darauf zugreifen. D.h. man kann nicht mehr so einfach Dinge wie die interne
Repräsentation oder die Art der Berechnung austauschen! Öffentliche Dinge
gehören zur Schnittstelle und damit Teil des "Vertrags" mit den Nutzern!
Code Smells: Duplizierter Code
public class Studi {
public String getName() { return name; }
public String getAddress() {
return strasse+", "+plz+" "+stadt;
}
public String getStudiAsString() {
return name+" ("+strasse+", "+plz+" "+stadt+")";
}
}
- Programmierprinzip "DRY" => "Don't repeat yourself!"
Im Beispiel wird das Formatieren der Adresse mehrfach identisch implementiert,
d.h. duplizierter Code. Auslagern in eigene Methode und aufrufen!
Kopierter/duplizierter Code ist problematisch:
- Spätere Änderungen müssen an mehreren Stellen vorgenommen werden
- Lesbarkeit/Orientierung im Code wird erschwert (Analogie: Reihenhaussiedlung)
- Verpasste Gelegenheit für sinnvolle Abstraktion!
Code Smells: Langer Code
-
Lange Klassen
- Faustregel: 5 Bildschirmseiten sind viel
-
Lange Methoden
- Faustregel: 1 Bildschirmseite
- [Martin2009]: deutlich weniger als 20 Zeilen
-
Lange Parameterlisten
- Faustregel: max. 3 ... 5 Parameter
- [Martin2009]: 0 Parameter ideal, ab 3 Parameter
gute Begründung nötig
-
Tief verschachtelte if/then-Bedingungen
- Faustregel: 2 ... 3 Einrückungsebenen sind viel
-
Programmierprinzip "Single Responsibility"
Jede Klasse ist für genau einen Aspekt des Gesamtsystems verantwortlich
Lesbarkeit und Übersichtlichkeit leiden
- Der Mensch kann sich nur begrenzt viele Dinge im Kurzzeitgedächtnis merken
- Klassen, die länger als 5 Bildschirmseiten sind, erfordern viel Hin- und
Her-Scrollen, dito für lange Methoden
- Lange Methoden sind schwer verständlich (erledigen viele Dinge?)
- Mehr als 3 Parameter kann sich kaum jemand merken, vor allem beim
Aufruf von Methoden
- Die Testbarkeit wird bei zu komplexen Methoden/Klassen und vielen Parametern
sehr erschwert
- Große Dateien verleiten (auch mangels Übersichtlichkeit) dazu, neuen
Code ebenfalls schluderig zu gliedern
Langer Code deutet auch auf eine Verletzung des Prinzips der Single Responsibility hin
-
Klassen fassen evtl. nicht zusammengehörende Dinge zusammen
public class Student {
private String name;
private String phoneAreaCode;
private String phoneNumber;
public void printStudentInfo() {
System.out.println("name: " + name);
System.out.println("contact: " + phoneAreaCode + "/" + phoneNumber);
}
}
Warum sollte sich die Klasse Student um die Einzelheiten des Aufbaus einer
Telefonnummer kümmern? Das Prinzip der "Single Responsibility" wird hier
verletzt!
-
Methoden erledigen vermutlich mehr als nur eine Aufgabe
public void credits() {
for (Student s : students) {
if (s.hasSemesterFinished()) {
ECTS c = calculateEcts(s);
s.setEctsSum(c);
}
}
}
// Diese Methode erledigt 4 Dinge: Iteration, Abfrage, Berechnung, Setzen ...
=> Erklären Sie die Methode jemandem. Wenn dabei das Wort "und"
vorkommt, macht die Methode höchstwahrscheinlich zu viel!
-
Viele Parameter bedeuten oft fehlende Datenabstraktion
Circle makeCircle(int x, int y, int radius);
Circle makeCircle(Point center, int radius); // besser!
Code Smells: Feature Neid
public class CreditsCalculator {
public ECTS calculateEcts(Student s) {
int semester = s.getSemester();
int workload = s.getCurrentWorkload();
int nrModuls = s.getNumberOfModuls();
int total = Math.min(30, workload);
int extra = Math.max(0, total - 30);
if (semester < 5) {
extra = extra * nrModuls;
}
return new ECTS(total + extra);
}
}
- Zugriff auf (viele) Interna der anderen Klasse! => Hohe Kopplung der Klassen!
- Methode
CreditsCalculator#calculateEcts() "möchte" eigentlich in
Student sein ...
Weiterführende Links
Wrap-Up
Quellen
- [Fowler2011] Refactoring
Fowler, M., Addison-Wesley, 2011. ISBN 978-0-201-48567-7. - [Inden2013] Der Weg zum Java-Profi
Inden, M., dpunkt.verlag, 2013. ISBN 978-3-8649-1245-0.
Kapitel 10: Bad Smells - [Martin2009] Clean Code
Martin, R., mitp, 2009. ISBN 978-3-8266-5548-7. - [Passig2013] Weniger schlecht programmieren
Passig, K. und Jander, J., O'Reilly, 2013. ISBN 978-3-89721-567-2.
Coding Conventions und Metriken
TL;DR
Code entsteht nicht zum Selbstzweck, er muss von anderen Menschen leicht verstanden und
gewartet werden können: Entwickler verbringen einen wesentlichen Teil ihrer Zeit mit dem
Lesen von (fremdem) Code.
Dabei helfen "Coding Conventions", die eine gewisse einheitliche äußerliche Erscheinung
des Codes vorgeben (Namen, Einrückungen, ...). Im Java-Umfeld ist der "Google Java Style"
bzw. der recht ähnliche "AOSP Java Code Style for Contributors" häufig anzutreffen.
Coding Conventions beinhalten typischerweise Regeln zu
- Schreibweisen und Layout
- Leerzeichen, Einrückung, Klammern
- Zeilenlänge, Umbrüche
- Kommentare
Die Beachtung von grundlegenden Programmierprinzipien hilft ebenso, die Lesbarkeit und
Verständlichkeit zu verbessern.
Metriken sind Kennzahlen, die aus dem Code berechnet werden, und können zur Überwachung
der Einhaltung von Coding Conventions und anderen Regeln genutzt werden. Nützliche
Metriken sind dabei NCSS (Non Commenting Source Statements), McCabe (Cyclomatic Complexity),
BEC (Boolean Expression Complexity) und DAC (Class Data Abstraction Coupling).
Für die Formatierung des Codes kann man die IDE nutzen, muss dort dann aber die Regeln
detailliert manuell einstellen. Das Tool Spotless lässt sich dagegen in den Build-Prozess
einbinden und kann die Konfiguration über ein vordefiniertes Regelset passend zum Google
Java Style/AOSP automatisiert vornehmen.
Die Prüfung der Coding Conventions und Metriken kann durch das Tool Checkstyle erfolgen.
Dieses kann beispielsweise als Plugin in der IDE oder direkt in den Build-Prozess eingebunden
werden und wird mit Hilfe einer XML-Datei konfiguriert.
Um typische Anti-Pattern zu vermeiden, kann man den Code mit sogenannten Lintern prüfen.
Ein Beispiel für die Java-Entwicklung ist SpotBugs, welches sich in den Build-Prozess
einbinden lässt und über 400 typische problematische Muster im Code erkennt.
Für die Praktika in der Veranstaltung Programmiermethoden wird der Google Java Style oder
AOSP genutzt. Für die passende Checkstyle-Konfiguration wird eine minimale
checkstyle.xml
bereitgestellt (vgl. Folie "Konfiguration für das PM-Praktikum").
Videos (HSBI-Medienportal)
Lernziele
- (K2) Erklären verschiedener Coding Conventions
- (K2) Erklären wichtiger Grundregeln des objektorientierten Programmierens
- (K2) Erklären der Metriken NCSS, McCabe, BEC, DAC
- (K3) Einhalten der wichtigsten Grundregeln des objektorientierten Programmierens
- (K3) Einhalten der wichtigsten Coding Conventions (Formatierung, Namen, Metriken)
- (K3) Nutzung des Tools Spotless (Formatierung des Codes)
- (K3) Nutzung des Tools Checkstyle (Coding Conventions und Metriken)
- (K3) Nutzung des Tools SpotBugs (Vermeiden von Anti-Pattern)
Coding Conventions: Richtlinien für einheitliches Aussehen von Code
=> Ziel: Andere Programmierer sollen Code schnell lesen können
- Namen, Schreibweisen: UpperCamelCase vs. lowerCamelCase vs. UPPER_SNAKE_CASE
- Kommentare (Ort, Form, Inhalt): Javadoc an allen
public und protected Elementen
- Einrückungen und Spaces vs. Tabs: 4 Spaces
- Zeilenlängen: 100 Zeichen
- Leerzeilen: Leerzeilen für Gliederung
- Klammern: Auf selber Zeile wie Code
Beispiele: Sun Code Conventions,
Google Java Style,
AOSP Java Code Style for Contributors
package wuppie.deeplearning.strategy;
/**
* Demonstriert den Einsatz von AOSP/Google Java Style ................. Umbruch nach 100 Zeichen |
*/
public class MyWuppieStudi implements Comparable<MyWuppieStudi> {
private static String lastName;
private static MyWuppieStudi studi;
private MyWuppieStudi() {}
/** Erzeugt ein neues Exemplar der MyWuppieStudi-Spezies (max. 40 Zeilen) */
public static MyWuppieStudi getMyWuppieStudi(String name) {
if (studi == null) {
studi = new MyWuppieStudi();
}
if (lastName == null) lastName = name;
return studi;
}
@Override
public int compareTo(MyWuppieStudi o) {
return lastName.compareTo(lastName);
}
}
Dieses Beispiel wurde nach Google Java Style/AOSP formatiert.
Die Zeilenlänge beträgt max. 100 Zeichen. Pro Methode werden max. 40 Zeilen genutzt. Zwischen Attributen,
Methoden und Importen wird jeweils eine Leerzeile eingesetzt (zwischen den einzelnen Attributen muss
aber keine Leerzeile genutzt werden). Zur logischen Gliederung können innerhalb von Methoden weitere
Leerzeilen eingesetzt werden, aber immer nur eine.
Klassennamen sind UpperCamelCase, Attribute und Methoden und Parameter lowerCamelCase, Konstanten (im
Beispiel nicht vorhanden) UPPER_SNAKE_CASE. Klassen sind Substantive, Methoden Verben.
Alle public und protected Elemente werden mit einem Javadoc-Kommentar versehen. Überschriebene Methoden
müssen nicht mit Javadoc kommentiert werden, müssen aber mit @Override markiert werden.
Geschweifte Klammern starten immer auf der selben Codezeile. Wenn bei einem if nur ein Statement vorhanden
ist und dieses auf die selbe Zeile passt, kann auf die umschließenden geschweiften Klammern ausnahmsweise
verzichtet werden.
Es wird mit Leerzeichen eingerückt. Google Java Style
arbeitet mit 2 Leerzeichen, während AOSP
hier 4 Leerzeichen vorschreibt. Im Beispiel wurde nach AOSP eingerückt.
Darüber hinaus gibt es vielfältige weitere Regeln für das Aussehen des Codes. Lesen Sie dazu entsprechend
auf Google Java Style und auch auf
AOSP nach.
Sie können den Code manuell formatieren, oder aber (sinnvollerweise) über Tools
formatieren lassen. Hier einige Möglichkeiten:
-
IDE: Code-Style einstellen und zum Formatieren nutzen
-
google-java-format:
java -jar google-java-format.jar --replace *.java
(auch als IDE-Plugin)
-
Spotless in Gradle:
plugins {
id "java"
id "com.diffplug.spotless" version "6.5.0"
}
spotless {
java {
// googleJavaFormat()
googleJavaFormat().aosp() // indent w/ 4 spaces
}
}
Prüfen mit ./gradlew spotlessCheck (Teil von ./gradlew check)
und Formatieren mit ./gradlew spotlessApply
Einstellungen der IDE's
- Eclipse:
Project > Properties > Java Code Style > Formatter: Coding-Style einstellen/einrichten- Code markieren,
Source > Format
- Komplettes Aufräumen:
Source > Clean Up (Formatierung, Importe, Annotationen, ...)
Kann auch so eingestellt werden, dass ein "Clean Up" immer beim Speichern ausgeführt wird!
- IntelliJ verfügt über ähnliche Fähigkeiten:
- Einstellen über
Preferences > Editor > Code Style > Java
- Formatieren mit
Code > Reformat Code oder Code > Reformat File
Die Details kann/muss man einzeln einstellen. Für die "bekannten" Styles (Google Java Style)
bringen die IDE's oft aber schon eine Gesamtkonfiguration mit.
Achtung: Zumindest in Eclipse gibt es mehrere Stellen, wo ein Code-Style eingestellt werden
kann ("Clean Up", "Formatter", ...). Diese sollten dann jeweils auf den selben Style eingestellt
werden, sonst gibt es unter Umständen lustige Effekte, da beim Speichern ein anderer Style
angewendet wird als beim "Clean Up" oder beim "Format Source" ...
Analog sollte man bei der Verwendung von Checkstyle auch in der IDE im Formatter die entsprechenden
Checkstyle-Regeln (s.u.) passend einstellen, sonst bekommt man durch Checkstyle Warnungen angezeigt,
die man durch ein automatisches Formatieren nicht beheben kann.
Wer direkt den Google Java Style nutzt,
kann auch den dazu passenden Formatter von Google einsetzen:
google-java-format.
Diesen kann man entweder als Plugin für IntelliJ/Eclipse einsetzen oder als Stand-alone-Tool
(Kommandozeile oder Build-Skripte) aufrufen. Wenn man sich noch einen entsprechenden
Git-Hook definiert, wird vor jedem Commit der Code entsprechend den Richtlinien formatiert :)
Hinweis: Bei Spotless in Gradle müssen je nach den Versionen von Spotless/google-java-format
bzw. des JDK noch Optionen in der Datei gradle.properties eingestellt werden (siehe
Demo und
Spotless > google-java-format (Web)).
Tipp: Die Formatierung über die IDE ist angenehm, aber in der Praxis leider oft etwas
hakelig: Man muss alle Regeln selbst einstellen (und es gibt einige dieser Einstellungen),
und gerade IntelliJ "greift" manchmal nicht alle Code-Stellen beim Formatieren. Nutzen Sie
Spotless und bauen Sie die Konfiguration in Ihr Build-Skript ein und konfigurieren Sie über
den Build-Prozess.
Metriken: Kennzahlen für verschiedene Aspekte zum Code
Metriken messen verschiedene Aspekte zum Code und liefern eine Zahl zurück. Mit Metriken kann
man beispielsweise die Einhaltung der Coding Rules (Formate, ...) prüfen, aber auch die Einhaltung
verschiedener Regeln des objektorientierten Programmierens.
Beispiele für wichtige Metriken (jeweils Max-Werte für PM)
Die folgenden Metriken und deren Maximal-Werte sind gute Erfahrungswerte aus der Praxis und helfen,
den Code Smell "Langer Code" (vgl. “Code Smells”) zu
erkennen und damit zu vermeiden. Über die Metriken BEC, McCabe und DAC wird auch die Einhaltung
elementarer Programmierregeln gemessen.
- NCSS (Non Commenting Source Statements)
- Zeilen pro Methode: 40; pro Klasse: 250; pro Datei: 300
Annahme: Eine Anweisung je Zeile ...
- Anzahl der Methoden pro Klasse: 10
- Parameter pro Methode: 3
- BEC (Boolean Expression Complexity)
Anzahl boolescher Ausdrücke in
if etc.: 3
- McCabe (Cyclomatic Complexity)
- Anzahl der möglichen Verzweigungen (Pfade) pro Methode + 1
- 1-4 gut, 5-7 noch OK
- DAC (Class Data Abstraction Coupling)
- Anzahl der genutzten (instantiierten) "Fremdklassen"
- Werte kleiner 7 werden i.A. als normal betrachtet
Die obigen Grenzwerte sind typische Standardwerte, die sich in der Praxis allgemein bewährt haben
(vergleiche u.a. [Martin2009] oder auch in
AOSP: Write short methods
und AOSP: Limit line length).
Dennoch sind das keine absoluten Werte an sich. Ein Übertreten der Grenzen ist ein
Hinweis darauf, dass höchstwahrscheinlich etwas nicht stimmt, muss aber im
konkreten Fall hinterfragt und diskutiert und begründet werden!
Metriken im Beispiel von oben
private static String lastName;
private static MyWuppieStudi studi;
public static MyWuppieStudi getMyWuppieStudi(String name) {
if (studi == null) {
studi = new MyWuppieStudi();
}
if (lastName == null) lastName = name;
return studi;
}
- BEC: 1 (nur ein boolescher Ausdruck im
if)
- McCabe: 3 (es gibt zwei mögliche Verzweigungen in der Methode plus die Methode selbst)
- DAC: 1 (eine "Fremdklasse":
String)
Anmerkung: In Checkstyle werden für einige häufig verwendete Standard-Klassen Ausnahmen definiert,
d.h. String würde im obigen Beispiel nicht bei DAC mitgezählt/angezeigt.
=> Verweis auf LV Softwareengineering
Metriken und die Einhaltung von Coding-Conventions werden sinnvollerweise nicht manuell,
sondern durch diverse Tools erfasst, etwa im Java-Bereich mit Hilfe von
Checkstyle.
Das Tool lässt sich Standalone über CLI nutzen
oder als Plugin für IDE's (Eclipse oder
IntelliJ) einsetzen. Gradle bringt ein
eigenes Plugin mit.
-
IDE: diverse Plugins:
Eclipse-CS,
CheckStyle-IDEA
-
CLI:
java -jar checkstyle-10.2-all.jar -c google_checks.xml *.java
-
Plugin "checkstyle"
in Gradle:
plugins {
id "java"
id "checkstyle"
}
checkstyle {
configFile file('checkstyle.xml')
toolVersion '10.2'
}
- Aufruf: Prüfen mit
./gradlew checkstyleMain (Teil von ./gradlew check)
- Konfiguration:
<projectDir>/config/checkstyle/checkstyle.xml (Default)
bzw. mit der obigen Konfiguration direkt im Projektordner
- Report:
<projectDir>/build/reports/checkstyle/main.html
Checkstyle: Konfiguration
Die auszuführenden Checks lassen sich über eine XML-Datei
konfigurieren. In Eclipse-CS kann man die Konfiguration
auch in einer GUI bearbeiten.
Das Checkstyle-Projekt stellt eine passende Konfiguration für den
Google Java Style
bereit. Diese ist auch in den entsprechenden Plugins oft bereits enthalten und kann direkt
ausgewählt oder als Startpunkt für eigene Konfigurationen genutzt werden.
Der Startpunkt für die Konfigurationsdatei ist immer das Modul "Checker". Darin können sich
"FileSetChecks" (Module, die auf einer Menge von Dateien Checks ausführen), "Filters" (Module,
die Events bei der Prüfung von Regeln filtern) und "AuditListeners" (Module, die akzeptierte
Events in einen Report überführen) befinden. Der "TreeWalker" ist mit der wichtigste Vertreter
der FileSetChecks-Module und transformiert die zu prüfenden Java-Sourcen in einen
Abstract Syntax Tree, also eine Baumstruktur, die dem jeweiligen Code unter der Java-Grammatik
entspricht. Darauf können dann wiederum die meisten Low-Level-Module arbeiten.
Eine Reihe von Standard-Checks sind bereits in Checkstyle
implementiert und benötigen keine weitere externe Abhängigkeiten. Man kann aber zusätzliche Regeln
aus anderen Projekten beziehen (etwa via Gradle/Maven) oder sich eigene zusätzliche Regeln in Java
schreiben. Die einzelnen Checks werden in der Regel als "Modul" dem "TreeWalker" hinzugefügt und
über die jeweiligen Properties näher konfiguriert.
Sie finden in der Doku zu jedem Check das entsprechende Modul,
das Eltern-Modul (also wo müssen Sie das Modul im XML-Baum einfügen) und auch die möglichen
Properties und deren Default-Einstellungen.
<module name="Checker">
<module name="LineLength">
<property name="max" value="100"/>
</module>
<module name="TreeWalker">
<module name="AvoidStarImport"/>
<module name="MethodCount">
<property name="maxPublic" value="10"/>
<property name="maxTotal" value="40"/>
</module>
</module>
</module>
Alternativen/Ergänzungen: beispielsweise MetricsReloaded.
SpotBugs: Finde Anti-Pattern und potentielle Bugs (Linter)
-
SpotBugs sucht nach über 400 potentiellen Bugs im Code
- Anti-Pattern (schlechte Praxis, "dodgy" Code)
- Sicherheitsprobleme
- Korrektheit
-
CLI: java -jar spotbugs.jar options ...
-
IDE: IntelliJ SpotBugs plugin,
SpotBugs Eclipse plugin
-
Gradle: SpotBugs Gradle Plugin
plugins {
id "java"
id "com.github.spotbugs" version "5.0.6"
}
spotbugs {
ignoreFailures = true
showStackTraces = false
}
Prüfen mit ./gradlew spotbugsMain (in ./gradlew check)
Im PM-Praktikum beachten wir die obigen Coding Conventions und Metriken mit den dort definierten
Grenzwerten. Diese sind bereits in der bereit gestellten Minimal-Konfiguration für Checkstyle
(s.u.) konfiguriert.
- Google Java Style/AOSP: Spotless
Zusätzlich wenden wir den Google Java Style
an. Statt der dort vorgeschriebenen Einrückung mit 2 Leerzeichen (und 4+ Leerzeichen bei Zeilenumbruch
in einem Statement) können Sie auch mit 4 Leerzeichen einrücken (8 Leerzeichen bei Zeilenumbruch)
(AOSP). Halten Sie sich in Ihrem
Team an eine einheitliche Einrückung (Google Java Style oder AOSP).
Formatieren Sie Ihren Code vor den Commits mit Spotless (über Gradle) oder stellen Sie den
Formatter Ihrer IDE entsprechend ein.
Checkstyle
- Minimal-Konfiguration für Checkstyle (Coding Conventions, Metriken)
Nutzen Sie die folgende Minimal-Konfiguration für Checkstyle für Ihre
Praktikumsaufgaben. Diese beinhaltet die Prüfung der wichtigsten Formate nach
Google Java Style/AOSP sowie der obigen Metriken. Halten Sie diese Regeln
ein.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE module PUBLIC "-//Checkstyle//DTD Checkstyle Configuration 1.3//EN" "https://checkstyle.org/dtds/configuration_1_3.dtd">
<module name="Checker">
<property name="severity" value="warning"/>
<module name="TreeWalker">
<module name="JavaNCSS">
<property name="methodMaximum" value="40"/>
<property name="classMaximum" value="250"/>
<property name="fileMaximum" value="300"/>
</module>
<module name="BooleanExpressionComplexity"/>
<module name="CyclomaticComplexity">
<property name="max" value="7"/>
</module>
<module name="ClassDataAbstractionCoupling">
<property name="max" value="6"/>
</module>
<module name="MethodCount">
<property name="maxTotal" value="10"/>
<property name="maxPrivate" value="10"/>
<property name="maxPackage" value="10"/>
<property name="maxProtected" value="10"/>
<property name="maxPublic" value="10"/>
</module>
<module name="ParameterNumber">
<property name="max" value="3"/>
</module>
<module name="MethodLength">
<property name="max" value="40"/>
</module>
<module name="Indentation">
<property name="basicOffset" value="4"/>
<property name="lineWrappingIndentation" value="8"/>
<property name="caseIndent" value="4"/>
<property name="throwsIndent" value="4"/>
<property name="arrayInitIndent" value="4"/>
</module>
<module name="TypeName"/>
<module name="MethodName"/>
<module name="MemberName"/>
<module name="ParameterName"/>
<module name="ConstantName"/>
<module name="OneStatementPerLine"/>
<module name="MultipleVariableDeclarations"/>
<module name="MissingOverride"/>
<module name="MissingJavadocMethod"/>
<module name="AvoidStarImport"/>
</module>
<module name="LineLength">
<property name="max" value="100"/>
</module>
<module name="FileTabCharacter">
<property name="eachLine" value="true"/>
</module>
<module name="NewlineAtEndOfFile"/>
</module>
Sie können diese Basis-Einstellungen auch aus dem Programmiermethoden-CampusMinden/PM-Lecture-Repo direkt herunterladen:
checkstyle.xml.
Sie können zusätzlich gern noch die weiteren (und strengeren) Regeln aus der vom Checkstyle-Projekt
bereitgestellten Konfigurationsdatei für den
Google Java Style
nutzen. Hinweis: Einige der dort konfigurierten Checkstyle-Regeln gehen allerdings über den
Google Java Style hinaus.
Linter: SpotBugs
- Vermeiden von Anti-Pattern mit SpotBugs
Setzen Sie zusätzlich SpotBugs mit ein. Ihre Lösungen dürfen keine Warnungen oder
Fehler beinhalten, die SpotBugs melden würde.
Wrap-Up
-
Code entsteht nicht zum Selbstzweck => Regeln nötig!
-
Metriken: Einhaltung von Regeln in Zahlen ausdrücken
-
Prüfung manuell durch Code Reviews oder durch Tools wie Checkstyle oder SpotBugs
-
Definition des "PM-Styles"
(siehe Folie "Konfiguration für das PM-Praktikum")
Refactoring
TL;DR
Refactoring bedeutet Änderung der inneren Struktur des Codes ohne Beeinflussung äußeren Verhaltens.
Mit Hilfe von Refactoring kann man Code Smells beheben, und Lesbarkeit, Verständlichkeit und Wartbarkeit
von Software verbessern.
Es ist wichtig, immer nur einzelne Schritte zu machen und anschließend die Testsuite laufen zu lassen,
damit nicht versehentlich Fehler oder Verhaltensänderungen beim Refactoring eingebaut werden.
Prinzipiell kann man Refactoring manuell mit Search&Replace durchführen, aber es bietet sich an, hier
die IDE-Unterstützung zu nutzen. Es stehen verschiedene Methoden zur Verfügung, die nicht unbedingt
einheitlich benannt sein müssen oder in jeder IDE vorkommen. Zu den häufig genutzten Methoden zählen
Rename, Extract, Move und Push Up/Pull Down.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Begriff, Notwendigkeit und Vorgehen des/beim Refactoring
- (K2) Bedeutung kleiner Schritte beim Refactoring
- (K2) Bedeutung einer sinnvollen Testsuite beim Refactoring
- (K2) Refactoring: Nur innere Struktur ändern, nicht äußeres Verhalten!
- (K3) Anwendung der wichtigsten Refactoring-Methoden: Rename, Extract, Move, Push Up/Pull Down
Was ist Refactoring?
Refactoring ist, wenn einem auffällt, daß der Funktionsname foobar
ziemlich bescheuert ist, und man die Funktion in sinus umbenennt.
Quelle: "356: Refactoring" by Andreas Bogk on Lutz Donnerhacke: "Fachbegriffe der Informatik"
Refactoring (noun): a change made to the internal structure of software to make
it easier to understand and cheaper to modify without changing its observable
behaviour.
Quelle: [Fowler2011, p. 53]
Refactoring: Änderungen an der inneren Struktur einer Software
- Beobachtbares (äußeres) Verhalten ändert sich dabei nicht
- Keine neuen Features einführen
- Keine Bugs fixen
- Keine öffentliche Schnittstelle ändern (Anmerkung: Bis auf Umbenennungen
oder Verschiebungen von Elementen innerhalb der Software)
- Ziel: Verbesserung von Verständlichkeit und Änderbarkeit
Anzeichen, dass Refactoring jetzt eine gute Idee wäre
-
Code "stinkt" (zeigt/enthält Code Smells)
Code Smells sind strukturelle Probleme, die im Laufe der Zeit zu
Problemen führen können. Refactoring ändert die innere Struktur
des Codes und kann entsprechend genutzt werden, um die Smells zu
beheben.
-
Schwer erklärbarer Code
Könnten Sie Ihren Code ohne Vorbereitung in der Abgabe erklären?
In einer Minute? In fünf Minuten? In zehn? Gar nicht?
In den letzten beiden Fällen sollten Sie definitiv über eine
Vereinfachung der Strukturen nachdenken.
-
Verständnisprobleme, Erweiterungen
Sie grübeln in der Abgabe, was Ihr Code machen sollte?
Sie überlegen, was Ihr Code bedeutet, um herauszufinden, wo Sie
die neue Funktionalität anbauen können?
Sie suchen nach Codeteilen, finden diese aber nicht, da die sich
in anderen (falschen?) Stellen/Klassen befinden?
Nutzen Sie die (neuen) Erkenntnisse, um den Code leichter
verständlich zu gestalten.
Wenn Sie sich zum dritten Mal über eine suboptimale Lösung ärgern, dann
werden Sie sich vermutlich noch öfter darüber ärgern. Jetzt ist der
Zeitpunkt für eine Verbesserung.
Schauen Sie sich die entsprechenden Kapitel in [Passig2013] und [Fowler2011]
an, dort finden Sie noch viele weitere Anhaltspunkte, ob und wann Refactoring
sinnvoll ist.
Bevor Sie loslegen ...
-
Unit Tests schreiben
- Normale und ungültige Eingaben
- Rand- und Spezialfälle
-
Coding Conventions einhalten
- Sourcecode formatieren (lassen)
-
Haben Sie die fragliche Codestelle auch wirklich verstanden?!
Vorgehen beim Refactoring
Überblick über die Methoden des Refactorings
Die Refactoring-Methoden sind nicht einheitlich definiert, es existiert ein großer
und uneinheitlicher "Katalog" an möglichen Schritten. Teilweise benennt jede IDE
die Schritte etwas anders, teilweise werden unterschiedliche Möglichkeiten angeboten.
Zu den am häufigsten genutzten Methoden zählen
- Rename Method/Class/Field
- Encapsulate Field
- Extract Method/Class
- Move Method
- Pull Up, Push Down (Field, Method)
Best Practice
Eine Best Practice (oder nennen Sie es einfach eine wichtige Erfahrung) ist,
beim Refactoring langsam und gründlich vorzugehen. Sie ändern die Struktur
der Software und können dabei leicht Fehler oder echte Probleme einbauen.
Gehen Sie also langsam und sorgsam vor, machen Sie einen Schritt nach dem
anderen und sichern Sie sich durch eine gute Testsuite ab, die Sie nach jedem
Schritt erneut ausführen: Das Verhalten der Software soll sich ja nicht
ändern, d.h. die Tests müssen nach jedem einzelnen Refactoring-Schritt immer
grün sein (oder Sie haben einen Fehler gemacht).
-
Kleine Schritte: immer nur eine Änderung zu einer Zeit
-
Nach jedem Refactoring-Schritt Testsuite laufen lassen
=> Nächster Refactoring-Schritt erst, wenn alle Tests wieder "grün"
-
Versionskontrolle nutzen: Jeden Schritt einzeln committen
Refactoring-Methode: Rename Method/Class/Field
Motivation
Name einer Methode/Klasse/Attributs erklärt nicht ihren Zweck.
Durchführung
Name selektieren, "Refactor > Rename"
Anschließend ggf. prüfen
Aufrufer? Superklassen?
Beispiel
Vorher
public String getTeN() {}
Nachher
public String getTelefonNummer() {}
Refactoring-Methode: Encapsulate Field
Motivation
Sichtbarkeit von Attributen reduzieren.
Durchführung
Attribut selektieren, "Refactor > Encapsulate Field"
Anschließend ggf. prüfen
Superklassen? Referenzen? (Neue) JUnit-Tests?
Beispiel
Vorher
int cps;
public void printDetails() {
System.out.println("Credits: " + cps);
}
Nachher
private int cps;
int getCps() { return cps; }
void setCps(int cps) { this.cps = cps; }
public void printDetails() {
System.out.println("credits: " + getCps());
}
Motivation
- Codefragment stellt eigenständige Methode dar
- "Überschriften-Code"
- Code-Duplizierung
- Code ist zu "groß"
- Klasse oder Methode erfüllt unterschiedliche Aufgaben
Durchführung
Codefragment selektieren, "Refactor > Extract Method" bzw. "Refactor > Extract Class"
Anschließend ggf. prüfen
- Aufruf der neuen Methode? Nutzung der neuen Klasse?
- Neue JUnit-Tests nötig? Veränderung bestehender Tests nötig?
- Speziell bei Methoden:
- Nutzung lokaler Variablen: Übergabe als Parameter!
- Veränderung lokaler Variablen: Rückgabewert in neuer Methode
und Zuweisung bei Aufruf; evtl. neue Typen nötig!
Beispiel
Vorher
public void printInfos() {
printHeader();
// Details ausgeben
System.out.println("name: " + name);
System.out.println("credits: " + cps);
}
Nachher
public void printInfos() {
printHeader();
printDetails();
}
private void printDetails() {
System.out.println("name: " + name);
System.out.println("credits: " + cps);
}
Refactoring-Methode: Move Method
Motivation
Methode nutzt (oder wird genutzt von) mehr Eigenschaften einer
fremden Klasse als der eigenen Klasse.
Durchführung
Methode selektieren, "Refactor > Move"
(ggf. "Keep original method as delegate to moved method" aktivieren)
Anschließend ggf. prüfen
- Aufruf der neuen Methode (Delegation)?
- Neue JUnit-Tests nötig? Veränderung bestehender Tests nötig?
- Nutzung lokaler Variablen: Übergabe als Parameter!
- Veränderung lokaler Variablen: Rückgabewert in neuer Methode
und Zuweisung bei Aufruf; evtl. neue Typen nötig!
Beispiel
Vorher
public class Kurs {
int cps;
String descr;
}
public class Studi extends Person {
String name;
int cps;
Kurs kurs;
public void printKursInfos() {
System.out.println("Kurs: " + kurs.descr);
System.out.println("Credits: " + kurs.cps);
}
}
Nachher
public class Kurs {
int cps;
String descr;
public void printKursInfos() {
System.out.println("Kurs: " + descr);
System.out.println("Credits: " + cps);
}
}
public class Studi extends Person {
String name;
int cps;
Kurs kurs;
public void printKursInfos() { kurs.printKursInfos(); }
}
Refactoring-Methode: Pull Up, Push Down (Field, Method)
Motivation
- Attribut/Methode nur für die Oberklasse relevant: Pull Up
- Subklassen haben identische Attribute/Methoden: Pull Up
- Attribut/Methode nur für eine Subklasse relevant: Push Down
Durchführung
Name selektieren, "Refactor > Pull Up" oder "Refactor > Push Down"
Anschließend ggf. prüfen
Referenzen/Aufrufer? JUnit-Tests?
Beispiel
Vorher
public class Person { }
public class Studi extends Person {
String name;
public void printDetails() { System.out.println("name: " + name); }
}
Nachher
public class Person { protected String name; }
public class Studi extends Person {
public void printDetails() { System.out.println("name: " + name); }
}
Wrap-Up
Behebung von Bad Smells durch Refactoring
=> Änderung der inneren Struktur ohne Beeinflussung des äußeren Verhaltens
- Verbessert Lesbarkeit, Verständlichkeit, Wartbarkeit
- Immer nur kleine Schritte machen
- Nach jedem Schritt Testsuite laufen lassen
- Katalog von Maßnahmen, beispielsweise Rename, Extract, Move, Push Up/Pull Down, ...
- Unterstützung durch IDEs wie Eclipse, Idea, ...
Challenges
In der Vorgabe
finden Sie einige Klassen mit unübersichtlichem und schlecht strukturierten Code.
Welche Bad Smells können Sie hier identifizieren?
Beheben Sie die Smells durch die schrittweise Anwendung von den aus der Vorlesung
bekannten Refactoring-Methoden. Wenden Sie dabei mindestens die unten genannten
Methoden an. Wenn Sie keinen passenden Smell identifizieren können, suchen Sie sich
eine geeignete Stelle, um die jeweilige Methode anzuwenden. Denken Sie auch daran,
dass Refactoring immer durch eine entsprechende Testsuite abgesichert sein muss.
Ergänzend zu der Übersicht aus der Vorlesung finden sie unter
Refactoring Guru eine erweiterte
Auflistung der gängigen Refactoring-Techniken.
- Extract Method/Class
- Move Method/Field
- Encapsulate Method/Field
- Pull Up oder Push Down
Quellen
- [Fowler2011] Refactoring
Fowler, M., Addison-Wesley, 2011. ISBN 978-0-201-48567-7. - [Inden2013] Der Weg zum Java-Profi
Inden, M., dpunkt.verlag, 2013. ISBN 978-3-8649-1245-0.
Kapitel 11: Refactorings - [Passig2013] Weniger schlecht programmieren
Passig, K. und Jander, J., O'Reilly, 2013. ISBN 978-3-89721-567-2.
Subsections of Bauen von Programmen, Automatisierung, Continuous Integration
Build-Systeme: Gradle
TL;DR
Um beim Übersetzen und Testen von Software von den spezifischen Gegebenheiten auf einem
Entwicklerrechner unabhängig zu werden, werden häufig sogenannte Build-Tools eingesetzt.
Mit diesen konfiguriert man sein Projekt abseits einer IDE und übersetzt, testet und
baut seine Applikation damit entsprechend unabhängig. In der Java-Welt sind aktuell die
Build-Tools Ant, Maven und Gradle weit verbreitet.
In Gradle ist ein Java-Entwicklungsmodell quasi eingebaut. Über die Konfigurationsskripte
müssen nur noch bestimmte Details wie benötigte externe Bibliotheken oder die Hauptklasse
und sonstige Projektbesonderheiten konfiguriert werden. Über "Tasks" wie build, test
oder run können Java-Projekte übersetzt, getestet und ausgeführt werden. Dabei werden die
externen Abhängigkeiten (Bibliotheken) aufgelöst (soweit konfiguriert) und auch abhängige
Tasks mit erledigt, etwa muss zum Testen vorher der Source-Code übersetzt werden.
Gradle bietet eine Fülle an Plugins für bestimmte Aufgaben an, die jeweils mit neuen Tasks
einher kommen. Beispiele sind das Plugin java, welches weitere Java-spezifische Tasks
wie classes mitbringt, oder das Plugin checkstyle zum Überprüfen von Coding-Style-Richtlinien.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Schreiben und Verstehen einfacher Gradle-Skripte
Automatisieren von Arbeitsabläufen
Einen häufigen Ausspruch, den man bei der Zusammenarbeit in Teams zu hören
bekommt, ist "Also, bei mir läuft der Code." ...
Das Problem dabei ist, dass jeder Entwickler eine andere Maschine hat, oft ein
anderes Betriebssystem oder eine andere OS-Version. Dazu kommen noch eine andere
IDE und/oder andere Einstellungen und so weiter.
Wie bekommt man es hin, dass Code zuverlässig auch auf anderen Rechnern baut?
Ein wichtiger Baustein dafür sind sogenannte "Build-Systeme", also Tools, die
unabhängig von der IDE (und den IDE-Einstellungen) für das Übersetzen der
Software eingesetzt werden und deren Konfiguration dann mit im Repo eingecheckt
wird. Damit kann die Software dann auf allen Rechnern und insbesondere dann auch
auf dem Server (Stichwort "Continuous Integration") unabhängig von der IDE o.ä.
automatisiert gebaut und getestet werden.
- Build-Tools:
- Apache Ant
- Apache Maven
- Gradle
Das sind die drei am häufigsten anzutreffenden Build-Tools in der Java-Welt.
Ant ist von den drei genannten Tools das älteste und setzt wie Maven auf XML als
Beschreibungssprache. In Ant müssen dabei alle Regeln stets explizit formuliert
werden, die man benutzen möchte.
In Maven wird dagegen von einem bestimmten Entwicklungsmodell ausgegangen, hier
müssen nur noch die Abweichungen zu diesem Modell konfiguriert werden.
In Gradle wird eine DSL basierend auf der Skriptsprache Groovy (läuft auf der
JVM) eingesetzt, und es gibt hier wie in Maven ein bestimmtes eingebautes
Entwicklungsmodell. Gradle bringt zusätzlich noch einen Wrapper mit, d.h. es
wird eine Art Gradle-Starter im Repo konfiguriert, der sich quasi genauso
verhält wie ein fest installiertes Gradle (s.u.).
Achtung: Während Ant und Maven relativ stabil in der API sind, verändert
sich Gradle teilweise deutlich zwischen den Versionen. Zusätzlich sind bestimmte
Gradle-Versionen oft noch von bestimmten JDK-Versionen abhängig. In der Praxis
bedeutet dies, dass man Gradle-Skripte im Laufe der Zeit relativ oft überarbeiten
muss (einfach nur, damit das Skript wieder läuft - ohne dass man dabei
irgendwelche neuen Features oder sonstige Vorteile erzielen würde). Ein großer
Vorteil ist aber der Gradle-Wrapper (s.u.).
Gradle: Eine DSL in Groovy
DSL: Domain Specific Language
// build.gradle
plugins {
id 'java'
id 'application'
}
repositories {
mavenCentral()
}
dependencies {
testImplementation 'junit:junit:4.13.2'
}
application {
mainClass = 'fluppie.App'
}
Dies ist mit die einfachste Build-Datei für Gradle.
Über Plugins wird die Unterstützung für Java und das Bauen von Applikationen aktiviert,
d.h. es stehen darüber entsprechende spezifische Tasks zur Verfügung.
Abhängigkeiten sollen hier aus dem Maven-Repository MavenCentral
geladen werden. Zusätzlich wird hier als Abhängigkeit für den Test (testImplementation)
die JUnit-Bibliothek in einer Maven-artigen Notation angegeben (vgl.
mvnrepository.com). (Für nur zur Übersetzung der Applikation
benötigte Bibliotheken verwendet man stattdessen das Schlüsselwort implementation.)
Bei der Initialisierung wurde als Package fluppie angegeben. Gradle legt darunter per
Default die Klasse App mit einer main()-Methode an. Entsprechend kann man über den
Eintrag application den Einsprungpunkt in die Applikation konfigurieren.
Gradle-DSL
Ein Gradle-Skript ist letztlich ein in Groovy geschriebenes Skript.
Groovy ist eine auf Java basierende und auf
der JVM ausgeführte Skriptsprache. Seit einigen Versionen kann man die
Gradle-Build-Skripte auch in der Sprache Kotlin schreiben.
Dateien
Für das Bauen mit Gradle benötigt man drei Dateien im Projektordner:
-
build.gradle: Die auf der Gradle-DSL beruhende Definition des Builds
mit den Tasks (und ggf. Abhängigkeiten) eines Projekts.
Ein Multiprojekt hat pro Projekt eine solche Build-Datei. Dabei können
die Unterprojekte Eigenschaften der Eltern-Buildskripte "erben" und so
relativ kurz ausfallen.
-
settings.gradle: Eine optionale Datei, in der man beispielsweise den
Projektnamen oder bei einem Multiprojekt die relevanten Unterprojekte
festlegt.
-
gradle.properties: Eine weitere optionale Datei, in der projektspezifische
Properties für den Gradle-Build spezifizieren kann.
Gradle Init
Um eine neue Gradle-Konfiguration anlegen zu lassen, geht man in einen Ordner
und führt darin gradle init aus. Gradle fragt der Reihe nach einige Einstellungen
ab:
$ gradle init
Select type of project to generate:
1: basic
2: application
3: library
4: Gradle plugin
Enter selection (default: basic) [1..4] 2
Select implementation language:
1: C++
2: Groovy
3: Java
4: Kotlin
5: Scala
6: Swift
Enter selection (default: Java) [1..6] 3
Split functionality across multiple subprojects?:
1: no - only one application project
2: yes - application and library projects
Enter selection (default: no - only one application project) [1..2] 1
Select build script DSL:
1: Groovy
2: Kotlin
Enter selection (default: Groovy) [1..2] 1
Select test framework:
1: JUnit 4
2: TestNG
3: Spock
4: JUnit Jupiter
Enter selection (default: JUnit Jupiter) [1..4] 1
Project name (default: tmp): wuppie
Source package (default: tmp): fluppie
Typischerweise möchte man eine Applikation bauen (Auswahl 2 bei der ersten Frage).
Als nächstes wird nach der Sprache des Projekts gefragt sowie nach der Sprache für
das Gradle-Build-Skript (Default ist Groovy) sowie nach dem Testframework, welches
verwendet werden soll.
Damit wird die eingangs gezeigte Konfiguration angelegt.
Ordner
Durch gradle init wird ein neuer Ordner wuppie/ mit folgender Ordnerstruktur
angelegt:
drwxr-xr-x 4 cagix cagix 4096 Apr 8 11:43 ./
drwxrwxrwt 1 cagix cagix 4096 Apr 8 11:43 ../
-rw-r--r-- 1 cagix cagix 154 Apr 8 11:43 .gitattributes
-rw-r--r-- 1 cagix cagix 103 Apr 8 11:43 .gitignore
drwxr-xr-x 3 cagix cagix 4096 Apr 8 11:43 app/
drwxr-xr-x 3 cagix cagix 4096 Apr 8 11:42 gradle/
-rwxr-xr-x 1 cagix cagix 8070 Apr 8 11:42 gradlew*
-rw-r--r-- 1 cagix cagix 2763 Apr 8 11:42 gradlew.bat
-rw-r--r-- 1 cagix cagix 370 Apr 8 11:43 settings.gradle
Es werden Einstellungen für Git erzeugt (.gitattributes und
.gitignore).
Im Ordner gradle/ wird der Gradle-Wrapper abgelegt (s.u.). Dieser
Ordner wird normalerweise mit ins Repo eingecheckt. Die Skripte
gradlew und gradlew.bat sind die Startskripte für den Gradle-Wrapper
(s.u.) und werden normalerweise ebenfalls ins Repo mit eingecheckt.
Der Ordner .gradle/ (erscheint ggf. nach dem ersten Lauf von Gradle
auf dem neuen Projekt) ist nur ein Hilfsordner ("Cache") von Gradle.
Hier werden heruntergeladene Dateien etc. abgelegt. Dieser Order
sollte nicht ins Repo eingecheckt werden und ist deshalb auch
per Default im generierten .gitignore enthalten. (Zusätzlich gibt es
im User-Verzeichnis auch noch einen Ordner .gradle/ mit einem globalen
Cache.)
In settings.gradle finden sich weitere Einstellungen. Die eigentliche
Gradle-Konfiguration befindet sich zusammen mit dem eigentlichen Projekt
im Unterordner app/:
drwxr-xr-x 4 root root 4096 Apr 8 11:50 ./
drwxr-xr-x 5 root root 4096 Apr 8 11:49 ../
drwxr-xr-x 5 root root 4096 Apr 8 11:50 build/
-rw-r--r-- 1 root root 852 Apr 8 11:43 build.gradle
drwxr-xr-x 4 root root 4096 Apr 8 11:43 src/
Die Datei build.gradle ist die durch gradle init erzeugte (und
eingangs gezeigte) Konfigurationsdatei, vergleichbar mit build.xml
für Ant oder pom.xml für Maven. Im Unterordner build/ werden die
generierten .class-Dateien etc. beim Build-Prozess abgelegt.
Unter src/ findet sich dann eine Maven-typische Ordnerstruktur
für die Sourcen:
$ tree src/
src/
|-- main
| |-- java
| | `-- fluppie
| | `-- App.java
| `-- resources
`-- test
|-- java
| `-- fluppie
| `-- AppTest.java
`-- resources
Unterhalb von src/ ist ein Ordner main/ für die Quellen der Applikation (Sourcen
und Ressourcen). Für jede Sprache gibt es einen eigenen Unterordner, hier entsprechend
java/. Unterhalb diesem folgt dann die bei der Initialisierung angelegte Package-Struktur
(hier fluppie mit der Default-Main-Klasse App mit einer main()-Methode). Diese
Strukturen wiederholen sich für die Tests unterhalb von src/test/.
Wer die herkömmlichen, deutlich flacheren Strukturen bevorzugt, also unterhalb von src/
direkt die Java-Package-Strukturen für die Sourcen der Applikation und unterhalb von test/
entsprechend die Strukturen für die JUnit-Test, der kann dies im Build-Skript einstellen:
sourceSets {
main {
java {
srcDirs = ['src']
}
resources {
srcDirs = ['res']
}
test {
java {
srcDirs = ['test']
}
}
}
Ablauf eines Gradle-Builds
Ein Gradle-Build hat zwei Hauptphasen: Konfiguration und Ausführung.
Während der Konfiguration wird das gesamte Skript durchlaufen (vgl. Ausführung
der direkten Anweisungen eines Tasks). Dabei wird ein Graph erzeugt: welche
Tasks hängen von welchen anderen ab etc.
Anschließend wird der gewünschte Task ausgeführt. Dabei werden zuerst alle
Tasks ausgeführt, die im Graphen auf dem Weg zu dem gewünschten Task liegen.
Mit gradle tasks kann man sich die zur Verfügung stehenden Tasks ansehen.
Diese sind der Übersicht halber noch nach "Themen" sortiert.
Für eine Java-Applikation sind die typischen Tasks gradle build zum Bauen der
Applikation (inkl. Ausführen der Tests) sowie gradle run zum Starten der Anwendung.
Wer nur die Java-Sourcen compilieren will, würde den Task gradle compileJava nutzen.
Mit gradle check würde man compilieren und die Tests ausführen sowie weitere Checks
durchführen (gradle test würde nur compilieren und die Tests ausführen), mit gradle jar
die Anwendung in ein .jar-File packen und mit gradle javadoc die Javadoc-Dokumentation
erzeugen und mit gradle clean die generierten Hilfsdateien aufräumen (löschen).
Plugin-Architektur
Für bestimmte Projekttypen gibt es immer wieder die gleichen Aufgaben. Um hier
Schreibaufwand zu sparen, existieren verschiedene Plugins für verschiedene
Projekttypen. In diesen Plugins sind die entsprechenden Tasks bereits mit den
jeweiligen Abhängigkeiten formuliert. Diese Idee stammt aus Maven, wo dies
für Java-basierte Projekte umgesetzt ist.
Beispielsweise erhält man über das Plugin java den Task clean zum Löschen
aller generierten Build-Artefakte, den Task classes, der die Sourcen zu
.class-Dateien kompiliert oder den Task test, der die JUnit-Tests
ausführt ...
Sie können sich Plugins und weitere Tasks relativ leicht auch selbst definieren.
Auflösen von Abhängigkeiten
Analog zu Maven kann man Abhängigkeiten (etwa in einer bestimmten Version
benötigte Bibliotheken) im Gradle-Skript angeben. Diese werden (transparent für
den User) von einer ebenfalls angegeben Quelle, etwa einem Maven-Repository,
heruntergeladen und für den Build genutzt. Man muss also nicht mehr die
benötigten .jar-Dateien der Bibliotheken mit ins Projekt einchecken.
Analog zu Maven können erzeugte Artefakte automatisch publiziert werden, etwa
in einem Maven-Repository.
Für das Projekt benötigte Abhängigkeiten kann man über den Eintrag dependencies
spezifizieren. Dabei unterscheidet man u.a. zwischen Applikation und Tests:
implementation und testImplementation für das Compilieren und Ausführen von
Applikation bzw. Tests. Diese Abhängigkeiten werden durch Gradle über die im
Abschnitt repositories konfigurierten Repositories aufgelöst und die entsprechenden
.jar-Files geladen (in den .gradle/-Ordner).
Typische Repos sind das Maven-Repo selbst (mavenCentral()) oder das Google-Maven-Repo
(google()).
Die Einträge in dependencies erfolgen dabei in einer Maven-Notation, die Sie
auch im Maven-Repo mvnrepository.com finden.
Beispiel mit weiteren Konfigurationen (u.a. Checkstyle und Javadoc)
plugins {
id 'java'
id 'application'
id 'checkstyle'
}
repositories {
mavenCentral()
}
application {
mainClass = 'hangman.Main'
}
java {
sourceCompatibility = JavaVersion.VERSION_11
targetCompatibility = JavaVersion.VERSION_11
}
run {
standardInput = System.in
}
sourceSets {
main {
java {
srcDirs = ['src']
}
resources {
srcDirs = ['res']
}
}
}
checkstyle {
configFile = file(“${rootDir}/google_checks.xml”)
toolVersion = '8.32'
}
dependencies {
implementation group: 'org.apache.poi', name: 'poi', version: '4.1.2'
}
javadoc {
options.showAll()
}
Hier sehen Sie übrigens noch eine weitere mögliche Schreibweise für das Notieren
von Abhängigkeiten: implementation group: 'org.apache.poi', name: 'poi', version: '4.1.2'
und implementation 'org.apache.poi:poi:4.1.2' sind gleichwertig, wobei die letztere
Schreibweise sowohl in den generierten Builds-Skripten und in der offiziellen Dokumentation
bevorzugt wird.
Gradle und Ant (und Maven)
Vorhandene Ant-Buildskripte kann man nach Gradle importieren und ausführen
lassen. Über die DSL kann man auch direkt Ant-Tasks aufrufen. Siehe auch
"Using Ant from Gradle".
Gradle-Wrapper
project
|-- app/
|-- build.gradle
|-- gradlew
|-- gradlew.bat
`-- gradle/
`-- wrapper/
|-- gradle-wrapper.jar
`-- gradle-wrapper.properties
Zur Ausführung von Gradle-Skripten benötigt man eine lokale Gradle-Installation.
Diese sollte für i.d.R. alle User, die das Projekt bauen wollen, identisch sein.
Leider ist dies oft nicht gegeben bzw. nicht einfach lösbar.
Zur Vereinfachung gibt es den Gradle-Wrapper gradlew (bzw. gradlew.bat für Windows).
Dies ist ein kleines Shellskript, welches zusammen mit einigen kleinen .jar-Dateien im
Unterordner gradle/ mit ins Repo eingecheckt wird und welches direkt die Rolle des
gradle-Befehls einer Gradle-Installation übernehmen kann. Man kann also in Konfigurationskripten,
beispielsweise für Gitlab CI, alle Aufrufe von gradle durch Aufrufe von gradlew ersetzen.
Beim ersten Aufruf lädt gradlew dann die spezifizierte Gradle-Version herunter und speichert
diese in einem lokalen Ordner .gradle/. Ab dann greift gradlew auf diese lokale (nicht
"installierte") gradle-Version zurück.
gradle init erzeugt den Wrapper automatisch in der verwendeten Gradle-Version mit.
Alternativ kann man den Wrapper nachträglich über gradle wrapper --gradle-version 6.5
in einer bestimmten (gewünschten) Version anlegen lassen.
Da der Gradle-Wrapper im Repository eingecheckt ist, benutzen alle Entwickler damit
automatisch die selbe Version, ohne diese auf ihrem System zuvor installieren zu müssen.
Deshalb ist der Einsatz des Wrappers einem fest installierten Gradle vorzuziehen!
Wrap-Up
Link-Sammlung Gradle
Challenges
Betrachten Sie das Buildskript gradle.build aus Dungeon-CampusMinden/Dungeon.
Erklären Sie, in welche Abschnitte das Buildskript unterteilt ist und welche Aufgaben diese
Abschnitte jeweils erfüllen. Gehen Sie dabei im Detail auf das Plugin java und die dort
bereitgestellten Tasks und deren Abhängigkeiten untereinander ein.
Continuous Integration (CI)
TL;DR
In größeren Projekten mit mehreren Teams werden die Beteiligten i.d.R. nur noch "ihre"
Codestellen compilieren und testen. Dennoch ist es wichtig, das gesamte Projekt regelmäßig
zu "bauen" und auch umfangreichere Testsuiten regelmäßig laufen zu lassen. Außerdem ist
es wichtig, das in einer definierten Umgebung zu tun und nicht auf einem oder mehreren
Entwicklerrechnern, die i.d.R. (leicht) unterschiedlich konfiguriert sind, um zuverlässige
und nachvollziehbare Ergebnisse zu bekommen. Weiterhin möchte man auf bestimmte Ereignisse
reagieren, wie etwa neue Commits im Git-Server, oder bei Pull-Requests möchte man vor dem
Merge automatisiert sicherstellen, dass damit die vorhandenen Tests alle "grün" sind und
auch die Formatierung etc. stimmt.
Dafür hat sich "Continuous Integration" etabliert. Hier werden die angesprochenen Prozesse
regelmäßig auf einem dafür eingerichteten System durchgeführt. Aktivitäten wie Übersetzen,
Testen, Style-Checks etc. werden in sogenannten "Pipelines" oder "Workflows" zusammengefasst
und automatisiert durch Commits, Pull-Requests oder Merges auf dem Git-Server ausgelöst. Die
Aktionen können dabei je nach Trigger und Branch unterschiedlich sein, d.h. man könnte etwa
bei PR gegen den Master umfangreichere Tests laufen lassen als bei einem PR gegen einen
Develop-Branch. In einem Workflow oder einer Pipeline können einzelne Aktionen wiederum von
anderen Aktionen abhängen. Das Ergebnis kann man dann auf dem Server einsehen oder bekommt
man komfortabel als Report per Mail zugeschickt.
Wir schauen uns hier exemplarisch GitHub Actions und GitLab CI/CD an. Um CI sinnvoll einsetzen
zu können, benötigt man Kenntnisse über Build-Tools. "CI" tritt üblicherweise zusammen mit "CD"
(Continuous Delivery) auf, also als "CI/CD". Der "CD"-Teil ist nicht Gegenstand der Betrachtung
in dieser Lehrveranstaltung.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Arbeitsweise von/mit CI
Motivation: Zusammenarbeit in Teams
Szenario
- Projekt besteht aus diversen Teilprojekten
- Verschiedene Entwicklungs-Teams arbeiten (getrennt) an verschiedenen Projekten
- Tester entwickeln Testsuiten für die Teilprojekte
- Tester entwickeln Testsuiten für das Gesamtprojekt
Manuelle Ausführung der Testsuiten reicht nicht
- Belastet den Entwicklungsprozess
- Keine (einheitliche) Veröffentlichung der Ergebnisse
- Keine (einheitliche) Eskalation bei Fehlern
- Keine regelmäßige Integration in Gesamtprojekt
Continuous Integration
- Regelmäßige, automatische Ausführung: Build und Tests
- Reporting
- Weiterführung der Idee: Regelmäßiges Deployment (Continuous Deployment)
Continuous Integration (CI)

Vorgehen
- Entwickler und Tester committen ihre Änderungen regelmäßig (Git, SVN, ...)
- CI-Server arbeitet Build-Skripte ab, getriggert durch Events: Push-Events, Zeit/Datum, ...
- Typischerweise wird dabei:
- Das Gesamtprojekt übersetzt ("gebaut")
- Die Unit- und die Integrationstests abgearbeitet
- Zu festen Zeiten werden zusätzlich Systemtests gefahren
- Typische weitere Builds: "Nightly Build", Release-Build, ...
- Ergebnisse jeweils auf der Weboberfläche einsehbar (und per E-Mail)
Einige Vorteile
- Tests werden regelmäßig durchgeführt (auch wenn sie lange dauern oder die
Maschine stark belasten)
- Es wird regelmäßig ein Gesamt-Build durchgeführt
- Alle Teilnehmer sind über aktuellen Projekt(-zu-)stand informiert
Beispiele für verbreitete CI-Umgebungen
GitLab CI/CD
Siehe auch "Get started with Gitlab CI/CD".
(Für den Zugriff wird VPN benötigt!)
Übersicht über Pipelines

- In Spalte "Status" sieht man das Ergebnis der einzelnen Pipelines:
"pending" (die Pipeline läuft gerade), "cancelled" (Pipeline wurde manuell
abgebrochen), "passed" (alle Jobs der Pipeline sind sauber durchgelaufen),
"failed" (ein Job ist fehlgeschlagen, Pipeline wurde deshalb abgebrochen)
- In Spalte "Pipeline" sind die Pipelines eindeutig benannt aufgeführt,
inkl. Trigger (Commit und Branch)
- In Spalte "Stages" sieht man den Zustand der einzelnen Stages
Wenn man mit der Maus auf den Status oder die Stages geht, erfährt man mehr bzw.
kann auf eine Seite mit mehr Informationen kommen.
Detailansicht einer Pipeline

Wenn man in eine Pipeline in der Übersicht klickt, werden die einzelnen
Stages dieser Pipeline genauer dargestellt.
Detailansicht eines Jobs

Wenn man in einen Job einer Stage klickt, bekommt man quasi die Konsolenausgabe
dieses Jobs. Hier kann man ggf. Fehler beim Ausführen der einzelnen Skripte
oder die Ergebnisse beispielsweise der JUnit-Läufe anschauen.
GitLab CI/CD: Konfiguration mit YAML-Datei
Datei .gitlab-ci.yml im Projekt-Ordner:
stages:
- my.compile
- my.test
job1:
script:
- echo "Hello"
- ./gradlew compileJava
- echo "wuppie!"
stage: my.compile
only:
- wuppie
job2:
script: "./gradlew test"
stage: my.test
job3:
script:
- echo "Job 3"
stage: my.compile
Stages
Unter stages werden die einzelnen Stages einer Pipeline definiert. Diese werden
in der hier spezifizierten Reihenfolge durchgeführt, d.h. zuerst würde my.compile
ausgeführt, und erst wenn alle Jobs in my.compile erfolgreich ausgeführt wurden,
würde anschließend my.test ausgeführt.
Dabei gilt: Die Jobs einer Stage werden (potentiell) parallel zueinander ausgeführt,
und die Jobs der nächsten Stage werden erst dann gestartet, wenn alle Jobs der
aktuellen Stage erfolgreich beendet wurden.
Wenn keine eigenen stages definiert werden, kann man
(lt. Doku)
auf die Default-Stages build, test und deploy zurückgreifen. Achtung: Sobald
man eigene Stages definiert, stehen diese Default-Stages nicht mehr zur Verfügung!
Jobs
job1, job2 und job3 definieren jeweils einen Job.
-
job1 besteht aus mehreren Befehlen (unter script). Alternativ
kann man die bei job2 gezeigte Syntax nutzen, wenn nur ein
Befehl zu bearbeiten ist.
Die Befehle werden von GitLab CI/CD in einer Shell ausgeführt.
-
Die Jobs job1 und job2 sind der Stage my.compile zugeordnet (Abschnitt
stage). Einer Stage können mehrere Jobs zugeordnet sein, die dann parallel
ausgeführt werden.
Wenn ein Job nicht explizit einer Stage zugeordnet ist, wird er
(lt. Doku)
zur Default-Stage test zugewiesen. (Das geht nur, wenn es diese
Stage auch gibt!)
-
Mit only und except kann man u.a. Branches oder Tags angeben,
für die dieser Job ausgeführt (bzw. nicht ausgeführt) werden soll.
Durch die Kombination von Jobs mit der Zuordnung zu Stages und Events lassen
sich unterschiedliche Pipelines für verschiedene Zwecke definieren.
Hinweise zur Konfiguration von GitLab CI/CD
Im Browser in den Repo-Einstellungen arbeiten:
- Unter
Settings > General > Visibility, project features, permissions
das CI/CD aktivieren
- Prüfen unter
Settings > CI/CD > Runners, dass unter
Available shared Runners mind. ein shared Runner verfügbar ist
(mit grün markiert ist)
- Unter
Settings > CI/CD > General pipelines einstellen:
Git strategy: git cloneTimeout: 10mPublic pipelines: false (nicht angehakt)
- YAML-File (
.gitlab-ci.yml) in Projektwurzel anlegen,
Aufbau siehe oben
- Build-Skript erstellen, lokal lauffähig bekommen, dann in Jobs nutzen
- Im
.gitlab-ci.yml die relevanten Branches einstellen (s.o.)
- Pushen, und unter
CI/CD > Pipelines das Builden beobachten
- in Status reinklicken und schauen, ob und wo es hakt
README.md anlegen in Projektwurzel (neben .gitlab-ci.yml),
Markdown-Schnipsel aus Settings > CI/CD > General pipelines > Pipeline status
auswählen und einfügen .…
Optional:
- Ggf. Schedules unter
CI/CD > Schedules anlegen
- Ggf. extra Mails einrichten:
Settings > Integrations > Pipeline status emails
GitHub Actions
Siehe "GitHub Actions: Automate your workflow from idea to production"
und auch "GitHub: CI/CD explained".
Übersicht über Workflows

Hier sieht man das Ergebnis der letzten Workflows. Dazu sieht man den
Commit und den Branch, auf dem der Workflow gelaufen ist sowie wann er
gelaufen ist. Über die Spalten kann man beispielsweise nach Status oder
Event filtern.
In der Abbildung ist ein Workflow mit dem Namen "GitHub CI" zu sehen, der
aktuell noch läuft.
Detailansicht eines Workflows

Wenn man in einen Workflow in der Übersicht anklickt, werden die einzelnen
Jobs dieses Workflows genauer dargestellt. "job3" ist erfolgreich gelaufen, "job1"
läuft gerade, und "job2" hängt von "job1" ab, d.h. kann erst nach dem erfolgreichen
Lauf von "job2" starten.
Detailansicht eines Jobs

Wenn man in einen Job anklickt, bekommt man quasi die Konsolenausgabe
dieses Jobs. Hier kann man ggf. Fehler beim Ausführen der einzelnen Skripte
oder die Ergebnisse beispielsweise der JUnit-Läufe anschauen.
GitHub Actions: Konfiguration mit YAML-Datei
Workflows werden als YAML-Dateien im Ordner .github/workflows/ angelegt.
name: GitHub CI
on:
# push on master branch
push:
branches: [master]
# manually triggered
workflow_dispatch:
jobs:
job1:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-java@v3
with:
java-version: '17'
distribution: 'temurin'
- uses: gradle/wrapper-validation-action@v1
- run: echo "Hello"
- run: ./gradlew compileJava
- run: echo "wuppie!"
job2:
needs: job1
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-java@v3
with:
java-version: '17'
distribution: 'temurin'
- uses: gradle/wrapper-validation-action@v1
- run: ./gradlew test
job3:
runs-on: ubuntu-latest
steps:
- run: echo "Job 3"
Workflowname und Trigger-Events
Der Name des Workflows wird mit dem Eintrag name spezifiziert und sollte sich im
Dateinamen widerspiegeln, also im Beispiel .github/workflows/github_ci.yml.
Im Eintrag on können die Events definiert werden, die den Workflow triggern. Im
Beispiel ist ein Push-Event auf dem master-Branch definiert sowie mit workflow_dispatch:
das manuelle Triggern (auf einem beliebigen Branch) freigeschaltet.
Jobs
Die Jobs werden unter dem Eintrag jobs definiert: job1, job2 und job3 definieren
jeweils einen Job.
-
job1 besteht aus mehreren Befehlen (unter steps), die auf einem aktuellen
virtualisierten Ubuntu-Runner ausgeführt werden.
Es wird zunächst das Repo mit Hilfe der Checkout-Action ausgecheckt
(uses: actions/checkout@v4), das JDK eingerichtet/installiert
(uses: actions/setup-java@v3) und der im Repo enthaltene Gradle-Wrapper
auf Unversehrtheit geprüft (uses: gradle/wrapper-validation-action@v1).
Die Actions sind vordefinierte Actions und im Github unter github.com/ + Action
zu finden, d.h. actions/checkout oder
actions/setup-java. Actions können
von jedermann definiert und bereitgestellt werden, in diesem Fall handelt es sich
um von GitHub selbst im Namespace "actions" bereit gestellte direkt nutzbare Actions.
Man kann Actions auch selbst im Ordner .github/actions/ für das Repo definieren
(Beispiel:
plfa.github.io).
Mit run werden Befehle in der Shell auf dem genutzten Runner (hier Ubuntu) ausgeführt.
-
Die Jobs job2 ist von job1 abhängig und wird erst gestartet, wenn job1 erfolgreich
abgearbeitet ist.
Ansonsten können die Jobs prinzipiell parallel ausgeführt werden.
Durch die Kombination von Workflows mit verschiedenen Jobs und Abhängigkeiten zwischen Jobs
lassen sich unterschiedliche Pipelines ("Workflows") für verschiedene Zwecke definieren.
Es lassen sich auch andere Runner benutzen, etwa ein virtualisiertes Windows oder macOS.
Man kann auch über einen "Matrix-Build" den Workflow auf mehreren Betriebssystemen gleichzeitig
laufen lassen.
Man kann auch einen Docker-Container benutzen. Dabei muss man beachten, dass dieser am besten
aus einer Registry (etwa von Docker-Hub oder aus der GitHub-Registry) "gezogen" wird, weil das
Bauen des Docker-Containers aus einem Docker-File in der Action u.U. relativ lange dauert.
Hinweise zur Konfiguration von GitHub Actions
Im Browser in den Repo-Einstellungen arbeiten:
-
Unter Settings > Actions > General > Actions permissions die Actions aktivieren
(Auswahl, welche Actions erlaubt sind)

-
Unter Settings > Actions > General > Workflow permissions ggf. bestimmen, ob die
Actions das Repo nur lesen dürfen oder auch zusätzlich schreiben dürfen

-
Unter Actions > <WORKFLOW> den Workflow ggf. deaktivieren:

Wrap-Up
Überblick über Continuous Integration:
- Konfigurierbare Aktionen, die auf dem Gitlab-/GitHub-Server ausgeführt werden
- Unterschiedliche Trigger: Commit, Merge, ...
- Aktionen können Branch-spezifisch sein
- Aktionen können von anderen Aktionen abhängen
Einführung in Docker
TL;DR
Container sind im Gegensatz zu herkömmlichen VMs eine schlanke Virtualisierungslösung.
Dabei laufen die Prozesse direkt im Kernel des Host-Betriebssystems, aber abgeschottet
von den anderen Prozessen durch Linux-Techniken wie cgroups und namespaces (unter
Windows kommt dafür der WSL2 zum Einsatz, unter macOS wird eine kleine Virtualisierung
genutzt).
Container sind sehr nützlich, wenn man an mehreren Stellen eine identische Arbeitsumgebung
benötigt. Man kann dabei entweder die Images (fertige Dateien) oder die Dockerfiles
(Anweisungen zum Erzeugen eines Images) im Projekt verteilen. Tatsächlich ist es nicht
unüblich, ein Dockerfile in das Projekt-Repo mit einzuchecken.
Durch Container hat man allerdings im Gegensatz zu herkömmlichen VMs keinen Sicherheitsgewinn,
da die im Container laufende Software ja direkt auf dem Host-Betriebssystem ausgeführt wird.
Es gibt auf DockerHub fertige Images, die man sich ziehen und starten kann. Ein solches
gestartetes Image nennt sich dann Container und enthält beispielsweise Dateien, die
in den Container gemountet oder kopiert werden. Man kann auch eigene Images bauen, indem
man eine entsprechende Konfiguration (Dockerfile) schreibt. Jeder Befehl bei der Erstellung
eines Images erzeugt einen neuen Layer, die sich dadurch mehrere Images teilen können.
In der Konfiguration einer Gitlab-CI-Pipeline kann man mit image ein Docker-Image
angeben, welches dann in der Pipeline genutzt wird.
VSCode kann über das Remote-Plugin sich (u.a.) mit Containern verbinden und dann im
Container arbeiten (editieren, compilieren, debuggen, testen, ...).
In dieser kurzen Einheit kann ich Ihnen nur einen ersten Einstieg in das Thema geben.
Wir haben uns beispielsweise nicht Docker Compose oder Kubernetes angeschaut, und auch
die Themen Netzwerk (zwischen Containern oder zwischen Containern und anderen Rechnern)
und Volumnes habe ich außen vor gelassen. Dennoch kommt man in der Praxis bereits mit
den hier vermittelten Basiskenntnissen erstaunlich weit ...
Videos (HSBI-Medienportal)
Lernziele
- (K2) Unterschied zwischen Containern und VMs
- (K2) Einsatzgebiete für Container
- (K2) Container laufen als abgeschottete Prozesse auf dem Host - kein Sandbox-Effekt
- (K3) Container von DockerHub ziehen
- (K3) Container starten
- (K3) Eigene Container definieren und bauen
- (K3) Einsatz von Containern in GitLab CI/CD und GitHub Actions
- (K3) Einsatz von VSCode und Containern
Motivation CI/CD: WFM (Works For Me)

Auf dem CI-Server muss man eine Arbeitsumgebung konfigurieren und bereitstellen, für
Java-basierte Projekte muss beispielsweise ein JDK existieren und man benötigt Tools
wie Maven oder Gradle, um die Buildskripte auszuführen. Je nach Projekt braucht man
dann noch weitere Tools und Bibliotheken. Diese Konfigurationen sind unabhängig vom
CI-Server und werden üblicherweise nicht direkt installiert, sondern über eine
Virtualisierung bereitgestellt.
Selbst wenn man keine CI-Pipelines einsetzt, hat man in Projekten mit mehreren
beteiligten Personen häufig das Problem "WFM" ("works for me"). Jeder Entwickler
hat sich auf ihrem Rechner eine Entwicklungsumgebung aufgesetzt und nutzt in der Regel
seine bevorzugte IDE oder sogar unterschiedliche JDK-Versionen ... Dadurch kann es
schnell passieren, dass Probleme oder Fehler auftreten, die sich nicht von allen
Beteiligten immer nachvollziehen lassen. Hier wäre eine einheitliche Entwicklungsumgebung
sinnvoll, die in einer "schlanken" Virtualisierung bereitgestellt wird.
Als Entwickler kann man zeitgleich in verschiedenen Projekten beteiligt sein, die
unterschiedliche Anforderungen an die Entwicklungstools mit sich bringen. Es könnte
beispielsweise passieren, dass man zeitgleich drei bestimmte Python-Versionen benötigt.
In den meisten Fällen schafft man es (mit ein wenig Aufwand), diese Tools nebeneinander
zu installieren. Oft ist das in der Praxis aber schwierig und fehleranfällig.
In diesen Fällen kann eine Virtualisierung helfen.
Virtualisierung: Container vs. VM

Wenn man über Virtualisierung auf dem Desktop spricht, kann man grob zwei Varianten
unterscheiden. In beiden Fällen ist die Basis die Hardware (Laptop, Desktop-Rechner)
und das darauf laufende (Host-) Betriebssystem (Linux, FreeBSD, macOS, Windows, ...).
Darauf läuft dann wiederum die Virtualisierung.
Im rechten Bild wird eine herkömmliche Virtualisierung mit virtuellen Maschinen (VM)
dargestellt. Dabei wird in der VM ein komplettes Betriebssystem (das "Gast-Betriebssystem")
installiert und darin läuft dann die gewünschte Anwendung. Die Virtualisierung (VirtualBox,
VMware, ...) läuft dabei als Anwendung auf dem Host-Betriebssystem und stellt dem
Gast-Betriebssystem in der VM einen Rechner mit CPU, RAM, ... zur Verfügung und übersetzt
die Systemaufrufe in der VM in die entsprechenden Aufrufe im Host-Betriebssystem. Dies benötigt
in der Regel entsprechende Ressourcen: Durch das komplette Betriebssystem in der VM ist eine
VM (die als Datei im Filesystem des Host-Betriebssystems liegt) oft mehrere 10GB groß. Für die
Übersetzung werden zusätzlich Hardwareressourcen benötigt, d.h. hier gehen CPU-Zyklen und RAM
"verloren" ... Das Starten einer VM dauert entsprechend lange, da hier ein komplettes
Betriebssystem hochgefahren werden muss. Dafür sind die Prozesse in einer VM relativ stark
vom Host-Betriebssystem abgekapselt, so dass man hier von einer "Sandbox" sprechen kann: Viren
o.ä. können nicht so leicht aus einer VM "ausbrechen" und auf das Host-Betriebssystem zugreifen
(quasi nur über Lücken im Gast-Betriebssystem kombiniert mit Lücken in der Virtualisierungssoftware).
Im linken Bild ist eine schlanke Virtualisierung auf Containerbasis dargestellt. Die Anwendungen
laufen direkt als Prozesse im Host-Betriebssystem, ein Gast-Betriebssystem ist nicht notwendig.
Durch den geschickten Einsatz von namespaces und cgroups und anderen in Linux und FreeBSD
verfügbaren Techniken werden die Prozesse abgeschottet, d.h. der im Container laufende Prozess
"sieht" die anderen Prozesse des Hosts nicht. Die Erstellung und Steuerung der Container übernimmt
hier beispielsweise Docker. Die Container sind dabei auch wieder Dateien im Host-Filesystem.
Dadurch benötigen Container wesentlich weniger Platz als herkömmliche VMs, der Start einer Anwendung
geht deutlich schneller und die Hardwareressourcen (CPU, RAM, ...) werden effizient genutzt.
Nachteilig ist, dass hier in der Regel ein Linux-Host benötigt wird (für Windows wird mittlerweile
der Linux-Layer (WSL) genutzt; für macOS wurde bisher eine Linux-VM im Hintergrund hochgefahren,
mittlerweile wird aber eine eigene schlanke Virtualisierung eingesetzt). Außerdem steht im Container
üblicherweise kein graphisches Benutzerinterface zur Verfügung. Da die Prozesse direkt im
Host-Betriebssystem laufen, stellen Container keine Sicherheitsschicht ("Sandboxen") dar!
In allen Fällen muss die Hardwarearchitektur beachtet werden: Auf einer Intel-Maschine können
normalerweise keine VMs/Container basierend auf ARM-Architektur ausgeführt werden und umgekehrt.
Getting started
-
DockerHub: fertige Images => hub.docker.com/search
-
Image downloaden: docker pull <IMAGE>
-
Image starten: docker run <IMAGE>
Begriffe
- Docker-File: Beschreibungsdatei, wie Docker ein Image erzeugen soll.
- Image: Enthält die Dinge, die lt. dem Docker-File in das Image gepackt werden sollen.
Kann gestartet werden und erzeugt damit einen Container.
- Container: Ein laufendes Images (genauer: eine laufende Instanz eines Images). Kann
dann auch zusätzliche Daten enthalten.
Beispiele
docker pull debian:stable-slim
docker run --rm -it debian:stable-slim /bin/sh
debian ist ein fertiges Images, welches über DockerHub bereit gestellt wird. Mit dem
Postfix stable-slim wird eine bestimmte Version angesprochen.
Mit docker run debian:stable-slim startet man das Image, es wird ein Container
erzeugt. Dieser enthält den aktuellen Datenstand, d.h. wenn man im Image eine Datei
anlegt, wäre diese dann im Container enthalten.
Mit der Option --rm wird der Container nach Beendigung automatisch wieder gelöscht. Da
jeder Aufruf von docker run <IMAGE> einen neuen Container erzeugt, würden sich sonst
recht schnell viele Container auf dem Dateisystem des Hosts ansammeln, die man dann manuell
aufräumen müsste. Man kann aber einen beendeten Container auch erneut laufen lassen ...
(vgl. Dokumentation von docker). Mit der Option --rm sind aber auch im Container angelegte
Daten wieder weg! Mit der Option -it wird der Container interaktiv gestartet und man landet
in einer Shell.
Bei der Definition eines Images kann ein "Entry Point" definiert werden, d.h. ein Programm,
welches automatisch beim Start des Container ausgeführt wird. Häufig erlauben Images aber auch,
beim Start ein bestimmtes auszuführendes Programm anzugeben. Im obigen Beispiel ist das /bin/sh,
also eine Shell ...
docker pull openjdk:latest
docker run --rm -v "$PWD":/data -w /data openjdk:latest javac Hello.java
docker run --rm -v "$PWD":/data -w /data openjdk:latest java Hello
Auch für Java gibt es vordefinierte Images mit einem JDK. Das Tag "latest" zeigt dabei auf die
letzte stabile Version des openjdk-Images. Üblicherweise wird "latest" von den Entwicklern immer
wieder weiter geschoben, d.h. auch bei anderen Images gibt es ein "latest"-Tag. Gleichzeitig ist
es die Default-Einstellung für die Docker-Befehle, d.h. es kann auch weggelassen werden:
docker run openjdk:latest und docker run openjdk sind gleichwertig. Alternativ kann man hier auch
hier wieder eine konkrete Version angeben.
Über die Option -v wird ein Ordner auf dem Host (hier durch "$PWD" dynamisch ermittelt) in den
Container eingebunden ("gemountet"), hier auf den Ordner /data. Dort sind dann die Dateien sichtbar,
die im Ordner "$PWD" enthalten sind. Über die Option -w kann ein Arbeitsverzeichnis definiert
werden.
Mit javac Hello.java wird javac im Container aufgerufen auf der Datei /data/Hello.java
im Container, d.h. die Datei Hello.java, die im aktuellen Ordner des Hosts liegt (und in den
Container gemountet wurde). Das Ergebnis (Hello.class) wird ebenfalls in den Ordner /data/
im Container geschrieben und erscheint dann im Arbeitsverzeichnis auf dem Host ... Analog kann
dann mit java Hello die Klasse ausgeführt werden.
Images selbst definieren
FROM debian:stable-slim
ARG USERNAME=pandoc
ARG USER_UID=1000
ARG USER_GID=1000
RUN apt-get update && apt-get install -y --no-install-recommends \
apt-utils bash wget make graphviz biber \
texlive-base texlive-plain-generic texlive-latex-base \
#
&& groupadd --gid $USER_GID $USERNAME \
&& useradd -s /bin/bash --uid $USER_UID --gid $USER_GID -m $USERNAME \
#
&& apt-get autoremove -y && apt-get clean -y && rm -rf /var/lib/apt/lists/*
WORKDIR /pandoc
USER $USERNAME
docker build -t <NAME> -f <DOCKERFILE> .
FROM gibt die Basis an, d.h. hier ein Image von Debian in der Variante stable-slim,
d.h. das ist der Basis-Layer für das zu bauende Docker-Image.
Über ARG werden hier Variablen gesetzt.
RUN ist der Befehl, der im Image (hier Debian) ausgeführt wird und einen neuen Layer
hinzufügt. In diesen Layer werden alle Dateien eingefügt, die bei der Ausführung des
Befehls erzeugt oder angelegt werden. Hier im Beispiel wird das Debian-Tool apt-get
gestartet und weitere Debian-Pakete installiert.
Da jeder RUN-Befehl einen neuen Layer anlegt, werden die restlichen Konfigurationen
ebenfalls in diesem Lauf durchgeführt. Insbesondere wird ein nicht-Root-User angelegt,
der von der UID und GID dem Default-User in Linux entspricht. Die gemounteten Dateien
haben die selben Rechte wie auf dem Host, und durch die Übereinstimmung von UID/GID
sind die Dateien problemlos zugreifbar und man muss nicht mit dem Root-User arbeiten
(dies wird aus offensichtlichen Gründen als Anti-Pattern angesehen). Bevor der RUN-Lauf
abgeschlossen wird, werden alle temporären und später nicht benötigten Dateien von
apt-get entfernt, damit diese nicht Bestandteil des Layers werden.
Mit WORKDIR und USER wird das Arbeitsverzeichnis gesetzt und auf den angegebenen User
umgeschaltet. Damit muss der User nicht mehr beim Aufruf von außen gesetzt werden.
Über docker build -t <NAME> -f <DOCKERFILE> . wird aus dem angegebenen Dockerfile und
dem Inhalt des aktuellen Ordners (".") ein neues Image erzeugt und mit dem angegebenen
Namen benannt.
Hinweis zum Umgang mit Containern und Updates:
Bei der Erstellung eines Images sind bestimmte Softwareversionen Teil des Images geworden.
Man kann prinzipiell in einem Container die Software aktualisieren, aber dies geht in dem
Moment wieder verloren, wo der Container beendet und gelöscht wird. Außerdem widerspricht
dies dem Gedanken, dass mehrere Personen mit dem selben Image/Container arbeiten und damit
auch die selben Versionsstände haben. In der Praxis löscht man deshalb das alte Image einfach
und erstellt ein neues, welches dann die aktualisierte Software enthält.
CI-Pipeline (GitLab)
default:
image: openjdk:17
job1:
stage: build
script:
- java -version
- javac Hello.java
- java Hello
- ls -lags
In den Gitlab-CI-Pipelines (analog wie in den GitHub-Actions) kann man Docker-Container
für die Ausführung der Pipeline nutzen.
Mit image: openjdk:17 wird das Docker-Image openjdk:17 vom DockerHub geladen und durch
den Runner für die Stages als Container ausgeführt. Die Aktionen im script-Teil, wie
beispielsweise javac Hello.java werden vom Runner an die Standard-Eingabe der Shell des
Containers gesendet. Im Prinzip entspricht das dem Aufruf auf dem lokalen Rechner:
docker run openjdk:17 javac Hello.java.
CI-Pipeline (GitHub)
name: demo
on:
push:
branches: [master]
workflow_dispatch:
jobs:
job1:
runs-on: ubuntu-latest
container: docker://openjdk:17
steps:
- uses: actions/checkout@v4
- run: java -version
- run: javac Hello.java
- run: java Hello
- run: ls -lags
https://stackoverflow.com/questions/71283311/run-github-workflow-on-docker-image-with-a-dockerfile
https://docs.github.com/en/actions/using-jobs/running-jobs-in-a-container
In den GitHub-Actions kann man Docker-Container für die Ausführung der Pipeline nutzen.
Mit docker://openjdk:17 wird das Docker-Image openjdk:17 vom DockerHub geladen und auf dem
Ubuntu-Runner als Container ausgeführt. Die Aktionen im steps-Teil, wie beispielsweise
javac Hello.java werden vom Runner an die Standard-Eingabe der Shell des Containers gesendet.
Im Prinzip entspricht das dem Aufruf auf dem lokalen Rechner: docker run openjdk:17 javac Hello.java.
VSCode und das Plugin "Remote - Containers"

- VSCode (Host): Plugin "Remote - Containers" installieren
- Docker (Host): Container starten mit Workspace gemountet
- VSCode (Host): Attach to Container => neues Fenster (Container)
- VSCode (Container): Plugin "Java Extension Pack" installieren
- VSCode (Container): Dateien editieren, kompilieren, debuggen, ...
Mit Visual Studio Code (VSC) kann man über SSH oder in einem Container arbeiten. Dazu installiert man sich
VSC lokal auf dem Host und installiert dort das Plugin "Remote - Containers". VSC kann darüber vordefinierte
Docker-Images herunterladen und darin arbeiten oder man kann alternativ einen Container selbst starten und
diesen mit VSC verbinden ("attachen").
Beim Verbinden öffnet VSC ein neues Fenster, welches mit dem Container verbunden ist. Nun kann man in diesem
neuen Fenster ganz normal arbeiten, allerdings werden alle Dinge in dem Container erledigt. Man öffnet also
Dateien in diesem Container, editiert sie im Container, übersetzt und testet im Container und nutzt dabei die
im Container installierten Tools. Sogar die entsprechenden VSC-Plugins kann man im Container installieren.
Damit benötigt man auf einem Host eigentlich nur noch VSC und Docker, aber keine Java-Tools o.ä. und kann
diese über einen im Projekt definierten Container (über ein mit versioniertes Dockerfile) nutzen.
Anmerkung: IntelliJ kann remote nur debuggen, d.h. das Editieren, Übersetzen, Testen läuft lokal auf dem
Host (und benötigt dort den entsprechenden Tool-Stack). Für das Debuggen kann Idea das übersetzte Projekt
auf ein Remote (SSH, Docker) schieben und dort debuggen.
Noch einen Schritt weiter geht das Projekt code-server: Dieses stellt
u.a. ein Docker-Image codercom/code-server bereit, welches
einen Webserver startet und über diesen kann man ein im Container laufendes (angepasstes) VSC erreichen. Man
braucht also nur noch Docker und das Image und kann dann über den Webbrowser programmieren. Der Projektordner
wird dabei in den Container gemountet, so dass die Dateien entsprechend zur Verfügung stehen:
docker run -it --name code-server -p 127.0.0.1:8080:8080 -v "$HOME/.config:/home/coder/.config" -v "$PWD:/home/coder/project" codercom/code-server:latest
Auf diesem Konzept setzt auch der kommerzielle Service GitHub Codespaces
von GitHub auf.
Link-Sammlung
Wrap-Up
-
Schlanke Virtualisierung mit Containern (kein eigenes OS)
-
Kein Sandbox-Effekt
-
Begriffe: Docker-File vs. Image vs. Container
-
Ziehen von vordefinierten Images
-
Definition eines eigenen Images
-
Arbeiten mit Containern: lokal, CI/CD, VSCode ...
Quellen
- [DockerInAction] Docker in Action
Nickoloff, D., Manning Publications, 2019. ISBN 978-1-6172-9476-1. - [DockerInPractice] Docker in Practice
Miell, I. und Sayers, A. H., Manning Publications, 2019. ISBN 978-1-6172-9480-8. - [Inden2013] Der Weg zum Java-Profi
Inden, M., dpunkt.verlag, 2013. ISBN 978-3-8649-1245-0.
Build-Systeme: Apache Ant
TL;DR
Zum Automatisieren von Arbeitsabläufen (Kompilieren, Testen, ...) stehen in der Java-Welt
verschiedene Tools zur Verfügung: Apache Ant, Apache Maven und Gradle sind sicher die am
bekanntesten darunter.
In Apache Ant werden die Build-Skripte in XML definiert. Die äußere Klammer ist dabei das
<project>. In einem Projekt kann es ein oder mehrere Teilziele (Targets) geben, die
untereinander abhängig sein können. Die Targets können quasi "aufgerufen" werden bzw. in
der IDE selektiert und gestartet werden.
In einem Target kann man schließlich mit Tasks Aufgaben wie Kompilieren, Testen, Aufräumen,
... erledigen lassen. Dazu gibt es eine breite Palette an vordefinierten Tasks. Zusätzlich
sind umfangreiche Operationen auf dem Filesystem möglich (Ordner erstellen, löschen, Dinge
kopieren, ...).
Über Properties können Werte und Namen definiert werden, etwa für bestimmte Ordner. Die
Properties sind unveränderliche Variablen (auch wenn man sie im Skript scheinbar neu setzen
kann).
Über Apache Ivy können analog zu Maven und Gradle definierte Abhängigkeiten aus Maven-Central
aufgelöst werden.
Im Unterschied zu Maven und Gradle ist in Ant kein Java-Entwicklungsmodell eingebaut. Man
muss sämtliche Targets selbst definieren.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Schreiben einfacher Ant-Skripte mit Abhängigkeiten zwischen den Targets
- (K3) Nutzung von Ant-Filesets (Dateisystemoperationen, Classpath)
- (K3) Nutzung von Ant-Properties
- (K3) Ausführen von Ant-Targets aus der IDE heraus
Automatisieren von Arbeitsabläufen
-
Build-Tools:
- Apache Ant
- Apache Maven
- Gradle
-
Aufgaben:
- Übersetzen des Quellcodes
- Ausführen der Unit-Tests
- Generieren der Dokumentation
- Packen der Distribution
- Aufräumen temporärer Dateien
- ...
=> Automatisieren mit Apache Ant: ant.apache.org
Aufbau von Ant-Skripten: Projekte und Targets
<project name="Vorlesung" default="clean" basedir=".">
<target name="init" />
<target name="compile" depends="init" />
<target name="test" depends="compile" />
<target name="dist" depends="compile,test" />
<target name="clean" />
</project>
- Ein Hauptziel:
project
- Ein oder mehrere Teilziele:
target
- Abhängigkeiten der Teilziele untereinander möglich:
depends
- Vorbedingung für Targets mit
if oder unless
Aufgaben erledigen: Tasks
- Tasks: Aufgaben bzw. Befehle ("Methodenaufruf"), in Targets auszuführen
- Struktur:
<taskname attr1="value1" attr2="value2" />
<target name="simplecompile" depends="clean,init">
<javac srcdir="src" destdir="build" classpath="." />
</target>
- Beispiele:
echo, javac, jar, javadoc, junit, ...
- Je Target mehrere Tasks möglich
- Quellen:
- Eingebaute Tasks
- Optionale Task-Bibliotheken
- Selbst definierte Tasks
=> Überblick: ant.apache.org/manual/tasksoverview.html
Properties: Name-Wert-Paare
<property name="app" value="MyProject" />
<property name="build.dir" location="build" />
<target name="init">
<mkdir dir="${build.dir}" />
</target>
-
Setzen von Eigenschaften: <property name="wuppie" value="fluppie" />
- Properties lassen sich nur einmal setzen ("immutable")
- Erneute Definition ist wirkungslos, erzeugt aber leider keinen Fehler
-
Nutzung von Properties: <property name="db" value="${wuppie}.db" />
-
Pfade: "location" statt "value" nutzen:
<property name="ziel" location="${p}/bla/blub" />
-
Properties beim Aufruf setzen mit Option "-D":
ant -Dwuppie=fluppie
Tasks zum Umgang mit Dateien und Ordnern
<target name="demo">
<mkdir dir="${build.dir}/lib" />
<delete dir="${build.dir}" />
<delete file="${dist.dir}/wuppie.jar" />
<copy file="myfile.txt" tofile="../bak/mycopy.txt" />
<move file="src/file.orig" tofile="bak/file.moved" />
</target>
<mkdir dir="${dist}/lib" />
- Legt auch direkte Unterverzeichnisse an
- Keine Aktion, falls Verzeichnis existiert
<delete dir="${builddir}" />
- Löscht eine Datei ("
file") oder ein Verzeichnis ("dir") (rekursiv!)
<copy file="myfile.txt" tofile="../bak/mycopy.txt" /><move file="src/file.orig" tofile="bak/file.moved" />
Nutzung von Filesets in Tasks
<copy todir="archive">
<fileset dir="src">
<include name="**/*.java" />
<exclude name="**/*.ba?" />
</fileset>
</copy>
<delete>
<fileset dir="." includes="**/*.ba?" />
</delete>
- "
*" für beliebig viele Zeichen
- "
?" für genau ein Zeichen
- "
**" alle Unterverzeichnisse
Es gibt auch die Variante <dirset dir="...">, um Verzeichnisse zu
gruppieren.
Pfade und externe Bibliotheken
-
Als Element direkt im Task:
<classpath>
<pathelement location="${lib}/helper.jar" />
<pathelement path="${project.classpath}" />
</classpath>
D.h. die Einbettung in den javac-Task würde etwa so erfolgen:
<target ... >
<javac ...>
<classpath>
<pathelement location="${lib}/helper.jar" />
<pathelement path="${project.classpath}" />
</classpath>
</javac>
</target>
Anmerkung: Neben dem pathelement können Sie hier auch (wie im nächsten
Beispiel gezeigt) ein oder mehrere fileset nutzen.
-
Wiederverwendbar durch ID und "refid":
<path id="java.class.path">
<fileset dir="${lib}">
<include name="**/*.jar" />
</fileset>
</path>
<classpath refid="java.class.path" />
Die Einbettung in den javac-Task würde hier etwa so erfolgen:
<path id="java.class.path">
<fileset dir="${lib}">
<include name="**/*.jar" />
</fileset>
</path>
<target ... >
<javac ...>
<classpath refid="java.class.path" />
</javac>
</target>
Anmerkung: Neben dem fileset können Sie hier auch (wie oben gezeigt)
ein oder mehrere pathelement nutzen.
Anmerkung: Laut ant.apache.org/manual/Tasks/junit.html
benötigt man neben der aktuellen junit.jar noch die ant-junit.jar im Classpath, um mit dem junit-Ant-Task
entsprechende JUnit4-Testfälle ausführen zu können.
Für JUnit5 gibt es einen neuen Task JUnitLauncher (vgl.
ant.apache.org/manual/Tasks/junitlauncher.html).
Beispiele
Beispiel-Task: Kompilieren
<path id="project.classpath">
<fileset dir="${lib.dir}" includes="**/*.jar" />
</path>
<target name="compile" depends="init" description="compile the source " >
<javac srcdir="${src.dir}" destdir="${build.dir}">
<classpath refid="project.classpath" />
</javac>
</target>
Beispiel-Task: Packen
<target name="dist" depends="compile" description="generate the distribution" >
<mkdir dir="${dist.dir}" />
<jar jarfile="${dist.dir}/${app}.jar" basedir="${build.dir}">
<manifest>
<attribute name="Main-Class" value="${app}" />
</manifest>
</jar>
</target>
Beispiel-Task: Testen
-
Tests einer Testklasse ausführen:
<junit>
<test name="my.test.TestCase" />
</junit>
-
Test ausführen und XML mit Ergebnissen erzeugen:
<junit printsummary="yes" fork="yes" haltonfailure="yes">
<formatter type="xml" />
<test name="my.test.TestCase" />
</junit>
-
Verschiedene Tests als Batch ausführen:
<junit printsummary="yes" haltonfailure="yes">
<classpath>
<pathelement location="${build.tests}" />
<pathelement path="${java.class.path}" />
</classpath>
<formatter type="plain"/>
<test name="my.test.TestCase" haltonfailure="no" outfile="result">
<formatter type="xml" />
</test>
<batchtest fork="yes" todir="${reports.tests}">
<fileset dir="${src.tests}">
<include name="**/*Test*.java" />
<exclude name="**/AllTests.java" />
</fileset>
</batchtest>
</junit>
-
Aus Testergebnis (XML) einen Report generieren:
<junitreport todir="${reportdir}">
<fileset dir="...">
<include name="TEST-*.xml" />
</fileset>
<report format="frames" todir="..." />
</junitreport>
-
Abbruch bei Fehler:
<junit ... failureproperty="tests.failed" ... >
<fail if="tests.failed" />
</junit>
=> junit.jar und ant-junit.jar (JUnit4.x) im Pfad!
Programme ausführen
<target name="run">
<java jar="build/jar/HelloWorld.jar" fork="true" classname ="test.Main">
<arg value ="-h" />
<classpath>
<pathelement location="./lib/test.jar" />
</ classpath>
</ java>
</target>
Ausblick: Laden von Abhängigkeiten mit Apache Ivy
Apache Ivy: Dependency Manager für Ant
<!-- build.xml -->
<project xmlns:ivy="antlib:org.apache.ivy.ant">
<target name="resolve">
<ivy:retrieve/>
</target>
</project>
Wenn Ivy installiert ist, kann man durch den Eintrag xmlns:ivy="antlib:org.apache.ivy.ant"
in der Projekt-Deklaration im Ant-Skript die Ivy-Tasks laden. Der wichtigste Task ist dabei
ivy:retrieve, mit dem externe Projektabhängigkeiten heruntergeladen werden können.
<!-- ivy.xml -->
<ivy-module version="2.0">
<dependencies>
<dependency org="commons-cli" name="commons-cli" rev="1.5.0" />
<dependency org="junit" name="junit" rev="4.13.2" />
</dependencies>
</ivy-module>
Zur Steuerung von Ivy legt man eine weitere Datei ivy.xml an. Das Wurzelelement ist ivy-module,
wobei die version die niedrigste kompatible Ivy-Version angibt.
Der dependencies-Abschnitt definiert dann die Abhängigkeiten, die Ivy auflösen muss. Die Schreibweise
ist dabei wie im Maven2 Repository (mvnrepository.com) angelegt. Dort
findet man beispielsweise für Apache Commons CLI den Eintrag für Maven ("POM"-Datei):
<!-- https://mvnrepository.com/artifact/commons-cli/commons-cli -->
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.4</version>
</dependency>
Für die Ivy-Konfiguration übernimmt man die groupId als org, die artifactId als name und die
version als rev im Eintrag dependency.
Damit kann Ivy diese Bibliothek über den Ant-Task ivy:retrieve vor dem Bauen herunterladen, sofern
die Bibliothek noch nicht lokal vorhanden ist. Eventuelle Abhängigkeiten werden dabei ebenfalls aufgelöst.
Im Detail: Der Ant-Task ivy:retrieve löst zunächst die Abhängigkeiten auf und lädt die Dateien (sofern
sie noch nicht vorhanden oder veraltet sind) in den Ivy-Cache (per Default: ~/.ivy2/cache/). Danach
werden die Dateien in den Default-Library-Order im Projekt kopiert (per Defaul: ./lib/). Die Ordner kann
man über Optionen im ivy:retrieve-Task einstellen.
Ausblick: Weitere Build-Systeme
-
Maven
- War als Nachfolger von Ant gedacht
- Statt wie bei Ant explizit Targets zu formulieren, geht Maven
von einem Standardprojekt aus - nur noch Abweichungen müssen
formuliert werden
- Zieht Abhängigkeiten in zentralen
.maven-Ordner
-
Gradle
- Eine Art Mischung aus Ant und Maven unter Nutzung der Sprache Groovy
-
Make
- DER Klassiker, stammt aus der C-Welt. Kann aber natürlich auch Java.
- Analog zu Ant: Aktionen und Ziele müssen explizit definiert werden
Wrap-Up
Apache Ant: ant.apache.org
- Automatisieren von Arbeitsabläufen
- Apache Ant: Targets, Tasks, Properties
- Targets sind auswählbare Teilziele
- Abhängigkeiten zwischen Targets möglich
- Tasks erledigen Aufgaben (innerhalb Targets)
- Properties sind nicht änderbare Variablen
- Umfangreiche Operationen auf Filesystem möglich
Quellen
- [Inden2013] Der Weg zum Java-Profi
Inden, M., dpunkt.verlag, 2013. ISBN 978-3-8649-1245-0.
Abschnitt 2.5.2: Ant
Build-Systeme: Apache Maven
TL;DR
Zum Automatisieren von Arbeitsabläufen (Kompilieren, Testen, ...) stehen in der Java-Welt
verschiedene Tools zur Verfügung: Apache Ant, Apache Maven und Gradle sind sicher die am
bekanntesten darunter.
In Apache Maven ist bereits der typische Java-Standard-Lebenszyklus eingebaut und es müssen
nur noch Abweichungen davon und Festlegung von Versionen und Dependencies in XML formuliert
werden. Dies nennt man auch "Convention over Configuration".
Die Maven-Goals sind auswählbare Ziele und werden durch Plugins bereitgestellt. Zwischen den
Goals sind Abhängigkeiten möglich (und bereits eingebaut). Über Properties kann man noch
Namen und Versionsnummern o.ä. definieren.
Abhängigkeiten zu externen Bibliotheken werden als Dependencies formuliert: Am besten den
Abschnitt von Maven-Central kopieren.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Schreiben einfacher Maven-Skripte zu Übersetzen des Projekts, zum Testen und zum Erzeugen von Jar-Files
- (K3) Nutzung von Maven-Properties
- (K3) Einbinden externer Bibliotheken als Dependencies
- (K3) Ausführen von Maven-Goals aus IDE heraus und Einbindung als Builder
mvn archetype:generate -DgroupId=de.hsbi.pm -DartifactId=my-project
-DarchetypeArtifactId=maven-archetype-quickstart

Von der zeitlichen Entstehung her kommt Maven nach Ant, aber vor Gradle. Wie in Ant sind
auch die Maven-Buildskripte XML-basierte Textdateien (Gradle nutzt eine Groovy-basierte DSL).
Allerdings hat Maven im Gegensatz zu Ant bereits ein Modell des Java-Entwicklungsprozess
"eingebaut": Im Ant-Skript muss alles, was man tun möchte, explizit als Target formuliert
werden, d.h. auch ein Kompilieren der Sourcen oder Ausführen der Tests muss extra als Target
ins Ant-Skript geschrieben werden, um benutzbar zu sein. In Maven ist dieses Modell bereits
implementiert, d.h. hier muss man lediglich zusätzliche oder abweichende Dinge im XML-File
konfigurieren. Das nennt man auch "convention over configuration".
Der Maven-Aufruf
mvn archetype:generate -DgroupId=de.hsbi.pm -DartifactId=my-project -DarchetypeArtifactId=maven-archetype-quickstart
erzeugt mit Hilfe des Plugins archetype, welches das Ziel (engl.: "Maven goal") generate
bereitstellt, ein neues Projekt mit dem Namen my-project und der initialen Package-Struktur
de.hsbi.pm. Das von Maven für die Projekterstellung genutzte Plugin ist unter der ID
maven-archetype-quickstart in den Maven-Repositories (etwa Maven-Central)
verfügbar, hier kann man mit der zusätzlichen Option -DarchetypeVersion=1.4 auf die letzte
Version schalten.
Die erzeugte Ordnerstruktur entspricht der Standardstruktur von Gradle (Gradle hat diese
quasi von Maven übernommen). Die Konfigurationsdatei für Maven hat den Namen pom.xml.
Hinweis: Die groupId und artifactId werden auch für eine Veröffentlichung des Jar-Files
des Projekts auf dem zentralen Maven-Repository Maven-Central
genutzt. Von hier würde Maven auch als Abhängigkeit konfigurierte Bibliotheken herunterladen.
Lebenszyklus (eingebaut in Maven)

In Maven ist das typische Java-Entwicklungsmodell als "Lebenszyklus" implementiert.
Entsprechende Plugins stellen die jeweiligen "Goals" (Ziele) bereit. Dabei sind
auch die Abhängigkeiten berücksichtigt, d.h. das Ziel test erfordert ein compile ...
Project Object Model: pom.xml
<project>
<!-- aktuelle Version für Maven 2.x-->
<modelVersion>4.0.0</modelVersion>
<!-- Basisinformationen -->
<groupId>de.hsbi.pm</groupId>
<artifactId>my-project</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- Eigenschaften, vergleichbar zu den Properties in Ant -->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.release>17</maven.compiler.release>
</properties>
<!-- Abhängigkeiten zu externen Bibliotheken -->
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
Die Konfigurationsdatei pom.xml stellt die Konfiguration für das Maven-Projekt bereit
("Project Object Model").
Es werden mindestens der Name des Projekts sowie die Abhängigkeiten definiert.
Die groupId ist ein eindeutiger Bezeichner für die Organisation oder den Autor des Projekts. Oft
wird hier einfach wie im obigen Beispiel eine Package-Struktur genutzt, aber wie im Fall von JUnit
kann dies auch ein einfacher String (dort "junit") sein.
Die artifactId ist der eindeutige Name für das Projekt, d.h. unter diesem Namen wird das generierte
Jar-File im Maven-Repository zu finden sein (sofern es denn veröffentlicht wird).
Über dependencies kann man benötigte Abhängigkeiten definieren, hier als Beispiel JUnit in der
4.x Variante ... Diese werden bei Bedarf von Maven vom Maven-Repository heruntergeladen. Die Einträge
für die Dependencies findet man ebenfalls auf MavenCentral.
Project Object Model: Plugins
<project>
...
<!-- Plugins: Stellen eigene "Goals" zur Verfügung -->
<build>
<plugins>
<plugin>
<!-- https://mvnrepository.com/artifact/org.apache.maven.plugins/maven-compiler-plugin -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.10.1</version>
</plugin>
<plugin>
<!-- https://mvnrepository.com/artifact/org.apache.maven.plugins/maven-surefire-plugin -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.2</version>
</plugin>
</plugins>
</build>
</project>
Zusätzlich können die Phasen des Build-Prozesses konfiguriert werden, d.h. für die
entsprechenden Plugins finden sich Abschnitte unter <build><plugins> in der pom.xml.
Auf maven.apache.org/plugins/index.html
finden Sie eine Übersicht über häufig benutzte Plugins sowie die von den Plugins
bereitgestellten Goals sowie Konfigurationsmöglichkeiten.
Die entsprechenden POM-Einträge finden Sie analog zu den Dependencies ebenfalls auf
MavenCentral (Tag "plugin" statt "dependency").
Plugins können aber auch selbst erstellt werden und in das Projekt eingebunden werden,
ein erster Einstieg ist die Plugin-API.
Und wie lasse ich jetzt eine Anwendung mal laufen?
mvn clean: Lösche alle generierten Artefakte, beispielsweise .class-Dateien.mvn compile => mvn compiler:compile: Übersetze die Sourcen und schiebe die
generierten .class-Dateien in den Ordner target/classes/ (Default). Dazu werden alle
Abhängigkeiten aufgelöst und bei Bedarf (neu) heruntergeladen (Default: Userverzeichnis,
Ordner .m2/).mvn test => mvn surefire:test: Lasse die Tests laufen. Hängt von compile
ab. Namenskonvention: Alle Klassen mit *Test.java und Test*.java im Standard-Testordner
src/test/java/ werden betrachtet (und weitere, vgl.
maven.apache.org/surefire/maven-surefire-plugin/examples/junit-platform.html).mvn package: Hängt von compile ab und erzeugt ein Jar-File mit dem Namen
"artifactId-version.jar" im Ordner target/. Mit mvn install kann man dieses
Jar-File dann auch dem lokalen Repository im Home-Verzeichnis des Users (.m2/)
hinzufügen.mvn exec:java -Dexec.mainClass="de.hsbi.pm.Main": Hängt von compile ab und
führt die Klasse de.hsbi.pm.Main aus.
Wrap-Up
Apache Maven: maven.apache.org, Maven Getting Started Guide
- Automatisieren von Arbeitabläufen
- Apache Maven: Goals, Properties, Dependencies => "Convention over Configuration",
Java-Standard-Lebenszyklus eingebaut
- Goals sind auswählbare Ziele, bereitgestellt durch Plugins
- Abhängigkeiten zwischen Goals möglich
- Properties agieren wie Variablen, etwa für Versionsnummern
- Abhängigkeiten zu externen Bibliotheken werden als Dependencies
formuliert: Abschnitt von Maven-Central kopieren
Quellen
- [Inden2013] Der Weg zum Java-Profi
Inden, M., dpunkt.verlag, 2013. ISBN 978-3-8649-1245-0.
Subsections of Entwurfsmuster
Strategy-Pattern
TL;DR
Das Verhalten von Klassen kann über Vererbungshierarchien weitergegeben und durch
Überschreiben in den erbenden Klassen verändert werden. Dies führt häufig schnell
zu breiten und tiefen Vererbungsstrukturen.
Das Strategy-Pattern ist ein Entwurfsmuster, in dem Verhalten stattdessen an
passende Klassen/Objekte ausgelagert (delegiert) wird.
Es wird eine Schnittstelle benötigt (Interface oder abstrakte Klasse), in dem
Methoden zum Abrufen des gewünschten Verhaltens definiert werden. Konkrete Klassen
leiten davon ab und implementieren das gewünschte konkrete Verhalten.
In den nutzenden Klassen wird zur Laufzeit eine passende Instanz der (Strategie-)
Klassen übergeben (Konstruktor, Setter, ...) und beispielsweise über ein Attribut
referenziert. Das gewünschte Verhalten muss nun nicht mehr in der nutzenden Klasse
selbst implementiert werden, stattdessen wird einfach auf dem übergebenen Objekt
die Methode aus der Schnittstelle aufgerufen. Dies nennt man auch "Delegation",
weil die Aufgabe (das Verhalten) an ein anderes Objekt (hier das Strategie-Objekt)
weiter gereicht (delegiert) wurde.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Strategie-Entwurfsmuster praktisch anwenden
Wie kann man das Verhalten einer Klasse dynamisch ändern?

Modellierung unterschiedlicher Hunderassen: Jede Art bellt anders.
Es bietet sich an, die Hunderassen von einer gemeinsamen Basisklasse
Hund abzuleiten, um die Hundeartigkeit allgemein sicherzustellen.
Da jede Rasse anders bellen soll, muss jedes Mal die Methode bellen
überschrieben werden. Das ist relativ aufwändig und fehleranfällig.
Außerdem kann man damit nicht modellieren, dass es beispielsweise
auch konkrete Bulldoggen geben mag, die nur leise fiepen ...
Lösung: Delegation der Aufgabe an geeignetes Objekt

Der Hund delegiert das Verhalten beim Bellen an ein Objekt,
welches beispielsweise bei der Instantiierung der Klasse übergeben
wurde (oder später über einen Setter). D.h. die Methode Hund#bellen
bellt nicht mehr selbst, sondern ruft auf einem passenden Objekt
eine vereinbarte Methode auf.
Dieses passende Objekt ist hier im Beispiel vom Typ Bellen und
hat eine Methode bellen (Interface). Die verschiedenen Bell-Arten
kann man über eigene Klassen implementieren, die das Interface
einhalten.
Damit braucht man in den Klassen für die Hunderassen die Methode
bellen nicht jeweils neu überschreiben, sondern muss nur bei
der Instantiierung eines Hundes ein passendes Bellen-Objekt
mitgeben.
Als netten Nebeneffekt kann man so auch leicht eine konkrete
Bulldogge realisieren, die eben nicht fies knurrt, sondern
leise fiept ...
Entwurfsmuster: Strategy Pattern
Exkurs UML: Assoziation vs. Aggregation vs. Komposition
Eine Assoziation beschreibt eine Beziehung zwischen zwei (oder mehr)
UML-Elementen (etwa Klassen oder Interfaces).
Eine Aggregation (leere Raute) ist eine Assoziation, die eine
Teil-Ganzes-Beziehung hervorhebt. Teile können dabei ohne das Ganze
existieren (Beispiel: Personen als Partner in einer Ehe-Beziehung).
D.h. auf der einbindenden Seite (mit der leeren Raute) hat man implizit
0..* stehen.
Eine Komposition (volle Raute) ist eine Assoziation, die eine
Teil-Ganzes-Beziehung hervorhebt. Teile können aber nicht ohne das Ganze
existieren (Beispiel: Gebäude und Stockwerke: Ein Gebäude besteht aus
Stockwerken, die ohne das Gebäude aber nicht existieren.). D.h. auf der
einbindenden Seite (mit der vollen Raute) steht implizit eine 1 (ein
Stockwerk gehört genau zu einem Gebäude, ein Gebäude besteht aber aus
mehreren Stockwerken).
Siehe auch Aggregation,
Assoziation
und Klassendiagramm.
Zweites Beispiel: Sortieren einer Liste von Studis
Sortieren einer Liste von Studis: Collections.sort kann eine Liste
nach einem Default-Kriterium sortieren oder aber über einen extra
Comparator nach benutzerdefinierten Kriterien ... Das Verhalten der
Sortiermethode wird also quasi an dieses Comparator-Objekt delegiert ...
public class Studi {
private String name;
public Studi(String name) { this.name = name; }
public static void main(String[] args) {
List<Studi> list = new ArrayList<Studi>();
list.add(new Studi("Klaas"));
list.add(new Studi("Hein"));
list.add(new Studi("Pit"));
// Sortieren der Liste (Standard-Reihenfolge)?!
// Sortieren der Liste (eigene Reihenfolge)?!
}
}
Anmerkung:
Die Interfaces Comparable und Comparator und deren Nutzung wurde(n) in
OOP besprochen. Anonyme Klassen wurden ebenfalls in OOP besprochen. Bitte
lesen Sie dies noch einmal in der Semesterliteratur nach, wenn Sie hier
unsicher sind!
Hands-On: Strategie-Muster
Implementieren Sie das Strategie-Muster für eine Übersetzungsfunktion:
- Eine Klasse liefert eine Nachricht (
String) mit getMessage() zurück.
- Diese Nachricht ist in der Klasse in Englisch implementiert.
- Ein passendes Übersetzerobjekt soll die Nachricht beim Aufruf der Methode
getMessage() in die Ziel-Sprache übersetzen.
Fragen:
- Wie muss das Pattern angepasst werden?
- Wie sieht die Implementierung aus?
Auflösung
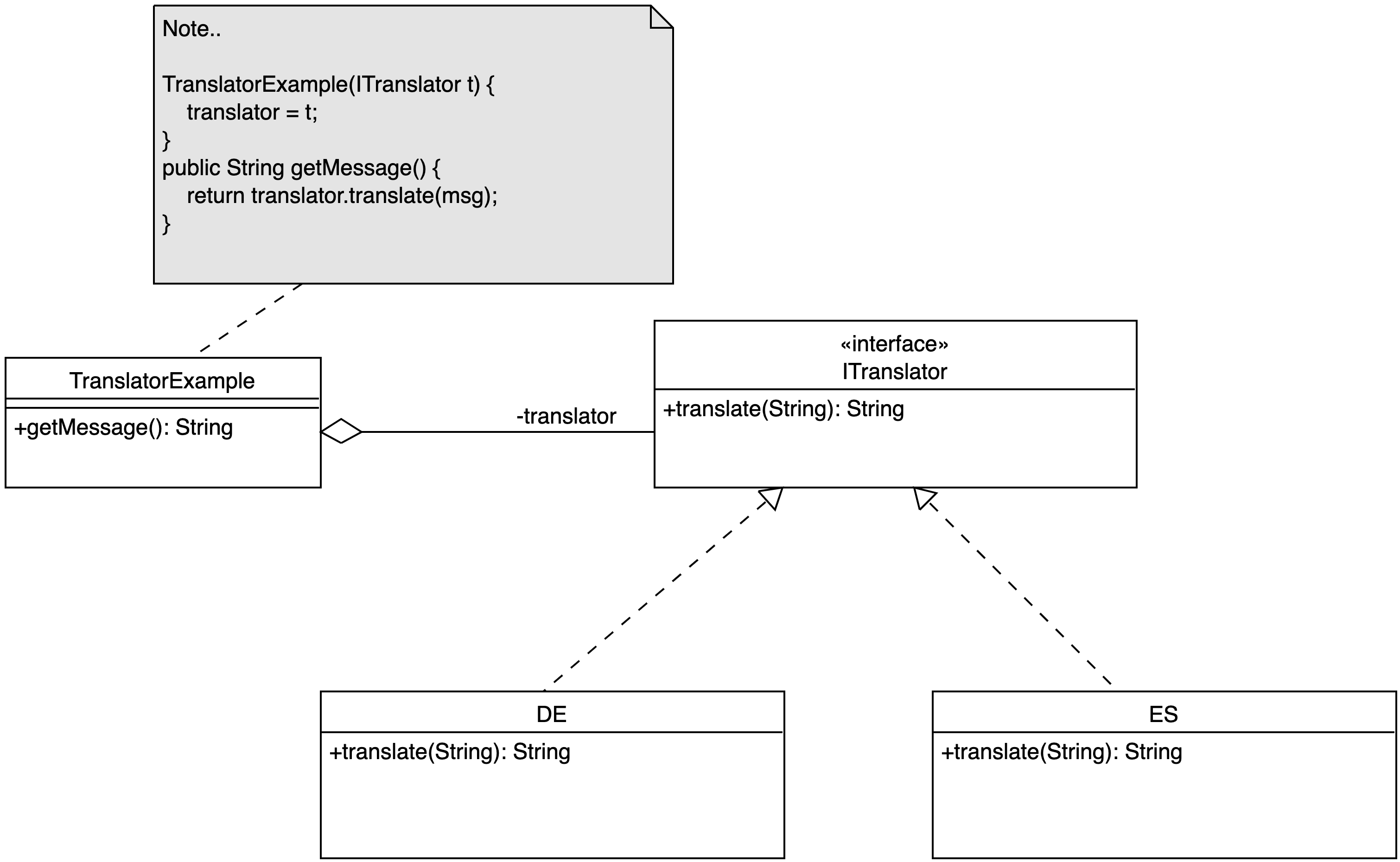
Wrap-Up
Strategy-Pattern: Verhaltensänderung durch Delegation an passendes Objekt
- Interface oder abstrakte Klasse als Schnittstelle
- Konkrete Klassen implementieren Schnittstelle => konkrete Strategien
- Zur Laufzeit Instanz dieser Klassen übergeben (Aggregation) ...
- ... und nutzen (Delegation)
Challenges
Implementieren Sie das Spiel "Schere,Stein,Papier" (Spielregeln vergleiche
wikipedia.org/wiki/Schere,Stein,Papier) in Java.
Nutzen Sie das Strategy-Pattern, um den Spielerinstanzen zur Laufzeit eine konkrete Spielstrategie mitzugeben, nach denen die Spieler ihre Züge berechnen.
Implementieren Sie mindestens drei unterschiedliche konkrete Strategien.
Hinweis: Eine mögliche Strategie könnte sein, den Nutzer via Tastatureingabe nach dem nächsten Zug zu fragen.
Gehen Sie bei der Lösung der Aufgabe methodisch vor:
- Stellen Sie sich eine Liste mit relevanten Anforderungen zusammen.
- Erstellen Sie (von Hand) ein Modell (UML-Klassendiagramm):
- Welche Klassen und Interfaces werden benötigt?
- Welche Aufgaben sollen die Klassen haben?
- Welche Attribute und Methoden sind nötig?
- Wie sollen die Klassen interagieren, wer hängt von wem ab?
- Implementieren Sie Ihr Modell in Java. Schreiben Sie ein Hauptprogramm, welches das Spiel startet,
die Spieler ziehen lässt und dann das Ergebnis ausgibt.
- Überlegen Sie, wie Sie Ihr Programm sinnvoll manuell testen können und tun Sie das.
Quellen
- [Eilebrecht2013] Patterns kompakt
Eilebrecht, K. und Starke, G., Springer, 2013. ISBN 978-3-6423-4718-4. - [Gamma2011] Design Patterns
Gamma, E. und Helm, R. und Johnson, R. E. und Vlissides, J., Addison-Wesley, 2011. ISBN 978-0-2016-3361-0. - [Kleuker2018] Grundkurs Software-Engineering mit UML
Kleuker, S., Springer Vieweg, 2018. ISBN 978-3-658-19969-2. DOI 10.1007/978-3-658-19969-2.
Visitor-Pattern
TL;DR
Häufig bietet es sich bei Datenstrukturen an, die Traversierung nicht direkt in den Klassen
der Datenstrukturen zu implementieren, sondern in Hilfsklassen zu verlagern. Dies gilt vor
allem dann, wenn die Datenstruktur aus mehreren Klassen besteht (etwa ein Baum mit verschiedenen
Knotentypen) und/oder wenn man nicht nur eine Traversierungsart ermöglichen will oder/und wenn
man immer wieder neue Arten der Traversierung ergänzen will. Das würde nämlich bedeuten, dass
man für jede weitere Form der Traversierung in allen Klassen eine entsprechende neue Methode
implementieren müsste.
Das Visitor-Pattern lagert die Traversierung in eigene Klassenstruktur aus.
Die Klassen der Datenstruktur bekommen nur noch eine accept()-Methode, in der ein Visitor
übergeben wird und rufen auf diesem Visitor einfach dessen visit()-Methode auf (mit einer
Referenz auf sich selbst als Argument).
Der Visitor hat für jede Klasse der Datenstruktur eine Überladung der visit()-Methode. In
diesen kann er je nach Klasse die gewünschte Verarbeitung vornehmen. Üblicherweise gibt es
ein Interface oder eine abstrakte Klasse für die Visitoren, von denen dann konkrete Visitoren
ableiten.
Bei Elementen mit "Kindern" muss man sich entscheiden, wie die Traversierung implementiert
werden soll. Man könnte in der accept()-Methode den Visitor an die Kinder weiter reichen
(also auf den Kindern accept() mit dem Visitor aufrufen), bevor man die visit()-Methode
des Visitors mit sich selbst als Referenz aufruft. Damit ist die Form der Traversierung in
den Klassen der Datenstruktur fest verankert und über den Visitor findet "nur" noch eine
unterschiedliche Form der Verarbeitung statt. Alternativ überlässt man es dem Visitor, die
Traversierung durchzuführen: Hier muss in den visit()-Methoden für die einzelnen Elemente
entsprechend auf mögliche Kinder reagiert werden.
In diesem Pattern findet ein sogenannter "Double-Dispatch" statt: Zur Laufzeit wird ein konkreter
Visitor instantiiert und über accept() an ein Element der Datenstruktur übergeben. Dort ist
zur Compile-Zeit aber nur der Obertyp der Visitoren bekannt, d.h. zur Laufzeit wird hier der
konkrete Typ bestimmt und entsprechend die richtige visit()-Methode auf der "echten" Klasse
des Visitors aufgerufen (erster Dispatch). Da im Visitor die visit()-Methoden für jeden Typ
der Datenstrukur überladen sind, findet nun zur Laufzeit die Auflösung der korrekten Überladung
statt (zweiter Dispatch).
Videos (HSBI-Medienportal)
Lernziele
- (K2) Aufbau des Visitor-Patterns (Besucher-Entwurfsmusters)
- (K3) Anwendung des Visitor-Patterns auf konkrete Beispiele, etwa den PM-Dungeon
Motivation: Parsen von "5*4+3"
Zum Parsen von Ausdrücken (Expressions) könnte man diese einfache Grammatik
einsetzen. Ein Ausdruck ist dabei entweder ein einfacher Integer oder eine
Addition oder Multiplikation zweier Ausdrücke.
expr : e1=expr '*' e2=expr # MUL
| e1=expr '+' e2=expr # ADD
| INT # NUM
;
Beim Parsen von "5*4+3" würde dabei der folgende Parsetree entstehen:

Strukturen für den Parsetree

Der Parsetree für diese einfache Grammatik ist ein Binärbaum. Die Regeln
werden auf Knoten im Baum zurückgeführt. Es gibt Knoten mit zwei Kindknoten,
und es gibt Knoten ohne Kindknoten ("Blätter").
Entsprechend kann man sich einfache Klassen definieren, die die verschiedenen
Knoten in diesem Parsetree repräsentieren. Als Obertyp könnte es ein (noch
leeres) Interface Expr geben.
public interface Expr {}
public class NumExpr implements Expr {
private final int d;
public NumExpr(int d) { this.d = d; }
}
public class MulExpr implements Expr {
private final Expr e1;
private final Expr e2;
public MulExpr(Expr e1, Expr e2) {
this.e1 = e1; this.e2 = e2;
}
}
public class AddExpr implements Expr {
private final Expr e1;
private final Expr e2;
public AddExpr(Expr e1, Expr e2) {
this.e1 = e1; this.e2 = e2;
}
}
public class DemoExpr {
public static void main(final String... args) {
// 5*4+3
Expr e = new AddExpr(new MulExpr(new NumExpr(5), new NumExpr(4)), new NumExpr(3));
}
}
Ergänzung I: Ausrechnen des Ausdrucks
Es wäre nun schön, wenn man mit dem Parsetree etwas anfangen könnte. Vielleicht
möchte man den Ausdruck ausrechnen?

Zum Ausrechnen des Ausdrucks könnte man dem Interface eine eval()-Methode
spendieren. Jeder Knoten kann für sich entscheiden, wie die entsprechende
Operation ausgewertet werden soll: Bei einer NumExpr ist dies einfach der
gespeicherte Wert, bei Addition oder Multiplikation entsprechend die Addition
oder Multiplikation der Auswertungsergebnisse der beiden Kindknoten.
public interface Expr {
int eval();
}
public class NumExpr implements Expr {
private final int d;
public NumExpr(int d) { this.d = d; }
public int eval() { return d; }
}
public class MulExpr implements Expr {
private final Expr e1;
private final Expr e2;
public MulExpr(Expr e1, Expr e2) {
this.e1 = e1; this.e2 = e2;
}
public int eval() { return e1.eval() * e2.eval(); }
}
public class AddExpr implements Expr {
private final Expr e1;
private final Expr e2;
public AddExpr(Expr e1, Expr e2) {
this.e1 = e1; this.e2 = e2;
}
public int eval() { return e1.eval() + e2.eval(); }
}
public class DemoExpr {
public static void main(final String... args) {
// 5*4+3
Expr e = new AddExpr(new MulExpr(new NumExpr(5), new NumExpr(4)), new NumExpr(3));
int erg = e.eval();
}
}
Ergänzung II: Pretty-Print des Ausdrucks
Nachdem das Ausrechnen so gut geklappt hat, will der Chef nun noch flink eine Funktion,
mit der man den Ausdruck hübsch ausgeben kann:

Das fängt an, sich zu wiederholen. Wir implementieren immer wieder ähnliche Strukturen,
mit denen wir diesen Parsetree traversieren ... Und wir müssen für jede Erweiterung
immer alle Expression-Klassen anpassen!
Das geht besser.
Visitor-Pattern (Besucher-Entwurfsmuster)

Das Entwurfsmuster "Besucher" (Visitor Pattern) lagert die Aktion beim Besuchen eines
Knotens in eine separate Klasse aus.
Dazu bekommt jeder Knoten im Baum eine neue Methode, die einen Besucher akzeptiert.
Dieser Besucher kümmert sich dann um die entsprechende Verarbeitung des Knotens, also
um das Auswerten oder Ausgeben im obigen Beispiel.
Die Besucher haben eine Methode, die für jeden zu bearbeitenden Knoten überladen wird.
In dieser Methode findet dann die eigentliche Verarbeitung statt: Auswerten des Knotens
oder Ausgeben des Knotens ...
public interface Expr {
void accept(ExprVisitor v);
}
public class NumExpr implements Expr {
private final int d;
public NumExpr(int d) { this.d = d; }
public int getValue() { return d; }
public void accept(ExprVisitor v) { v.visit(this); }
}
public class MulExpr implements Expr {
private final Expr e1;
private final Expr e2;
public MulExpr(Expr e1, Expr e2) {
this.e1 = e1; this.e2 = e2;
}
public Expr getE1() { return e1; }
public Expr getE2() { return e2; }
public void accept(ExprVisitor v) { v.visit(this); }
}
public class AddExpr implements Expr {
private final Expr e1;
private final Expr e2;
public AddExpr(Expr e1, Expr e2) {
this.e1 = e1; this.e2 = e2;
}
public Expr getE1() { return e1; }
public Expr getE2() { return e2; }
public void accept(ExprVisitor v) { v.visit(this); }
}
public interface ExprVisitor {
void visit(NumExpr e);
void visit(MulExpr e);
void visit(AddExpr e);
}
public class EvalVisitor implements ExprVisitor {
private final Stack<Integer> erg = new Stack<>();
public void visit(NumExpr e) { erg.push(e.getValue()); }
public void visit(MulExpr e) {
e.getE1().accept(this); e.getE1().accept(this);
erg.push(erg.pop() * erg.pop());
}
public void visit(AddExpr e) {
e.getE1().accept(this); e.getE1().accept(this);
erg.push(erg.pop() + erg.pop());
}
public int getResult() { return erg.peek(); }
}
public class PrintVisitor implements ExprVisitor {
private final Stack<String> erg = new Stack<>();
public void visit(NumExpr e) { erg.push("NumExpr(" + e.getValue() + ")"); }
public void visit(MulExpr e) {
e.getE1().accept(this); e.getE1().accept(this);
erg.push("MulExpr(" + erg.pop() + ", " + erg.pop() + ")");
}
public void visit(AddExpr e) {
e.getE1().accept(this); e.getE1().accept(this);
erg.push("AddExpr(" + erg.pop() + ", " + erg.pop() + ")");
}
public String getResult() { return erg.peek(); }
}
public class DemoExpr {
public static void main(final String... args) {
// 5*4+3
Expr e = new AddExpr(new MulExpr(new NumExpr(5), new NumExpr(4)), new NumExpr(3));
EvalVisitor v1 = new EvalVisitor();
e.accept(v1);
int erg = v1.getResult();
PrintVisitor v2 = new PrintVisitor();
e.accept(v2);
String s = v2.getResult();
}
}
Implementierungsdetail
In den beiden Klasse AddExpr und MulExpr müssen auch die beiden Kindknoten besucht
werden, d.h. hier muss der Baum weiter traversiert werden.
Man kann sich überlegen, diese Traversierung in den Klassen AddExpr und MulExpr
selbst anzustoßen.
Alternativ könnte auch der Visitor die Traversierung vornehmen. Gerade bei der Traversierung
von Datenstrukturen ist diese Variante oft von Vorteil, da man hier unterschiedliche
Traversierungsarten haben möchte (Breitensuche vs. Tiefensuche, Pre-Order vs. Inorder vs.
Post-Order, ...) und diese elegant in den Visitor verlagern kann.
(Double-) Dispatch
Zur Laufzeit wird in accept() der Typ des Visitors aufgelöst und dann in visit() der
Typ der zu besuchenden Klasse. Dies nennt man auch "Double-Dispatch".
Hinweis I
Man könnte versucht sein, die accept()-Methode aus den Knotenklassen in die gemeinsame
Basisklasse zu verlagern: Statt
public void accept(ExprVisitor v) {
v.visit(this);
}
in jeder Knotenklasse einzeln zu definieren, könnte man das doch einmalig in der
Basisklasse definieren:
public abstract class Expr {
/** Akzeptiere einen Visitor für die Verarbeitung */
public void accept(ExprVisitor v) {
v.visit(this);
}
}
Dies wäre tatsächlich schön, weil man so Code-Duplizierung vermeiden könnte. Aber es
funktioniert in Java leider nicht. (Warum?)
Hinweis II
Während die accept()-Methode nicht in die Basisklasse der besuchten Typen (im Bild oben
die Klasse Elem bzw. im Beispiel oben die Klasse Expr) verlagert werden kann, kann man
aber die visit()-Methoden im Interface Visitor durchaus als Default-Methoden im Interface
implementieren.
Ausrechnen des Ausdrucks mit einem Visitor

Wrap-Up
Visitor-Pattern: Auslagern der Traversierung in eigene Klassenstruktur
Challenges
In den Vorgaben
finden Sie Code zur Realisierung von (rudimentären) binären Suchbäumen.
-
Betrachten Sie die Klassen BinaryNode und Main. Die Klasse BinaryNode dient zur einfachen Repräsentierung von
binären Suchbäumen, in Main ist ein Versuchsaufbau vorbereitet.
- Implementieren Sie das Visitor-Pattern für den Binärbaum (in den Klassen
BinaryNode und Main). Der
nodeVisitor soll einen Binärbaum inorder traversieren.
- Führen Sie in
Main die Aufrufe auf binaryTree aus (3a).
- Worin besteht der Unterschied zwischen den Aufrufen
binaryTree.accept(nodeVisitor) und
nodeVisitor.visit(binaryTree) (3a)?
-
In BinaryNode wird ein Blatt aktuell durch einen Knoten repräsentiert, der für beide Kindbäume den Wert null
hat. Um Blätter besser zu repräsentieren, gibt es die Klasse UnaryNode.
- Passen Sie
BinaryNode so an, dass die Kindbäume auch UnaryNode sein können.
- Entfernen Sie in
Main die Auskommentierung um die Definition von mixedTree.
- Führen Sie in
Main die Aufrufe auf mixedTree aus (3b). Passen Sie dazu ggf. Ihre Implementierung des
Visitor-Patterns an.
- Worin besteht der Unterschied zwischen den Aufrufen
mixedTree.accept(nodeVisitor) und
nodeVisitor.visit(mixedTree) (3b)?
-
Sowohl binaryTree als auch mixedTree werden in Main als BinaryNode<String> deklariert. Das ist eine
unschöne Praxis: Es soll nach Möglichkeit der Obertyp genutzt werden. Dies ist in diesem Fall Node<String>.
- Entfernen Sie in
Main die Auskommentierung um die Definition von tree.
- Führen Sie in
Main die Aufrufe auf tree aus (3c). Passen Sie dazu ggf. Ihre Implementierung des
Visitor-Patterns an.
- Worin besteht der Unterschied zwischen den Aufrufen
tree.accept(nodeVisitor) und
nodeVisitor.visit(tree) (3c)?
-
Implementieren Sie analog zu nodeVisitor einen weiteren Visitor, der die Bäume postorder traversiert
und wiederholen Sie für diesen neuen Visitor die Aufrufe in (3a) bis (3c).
-
Erklären Sie, wieso im Visitor-Pattern für den Start der Traversierung statt visitor.visit(tree) der Aufruf
tree.accept(visitor) genutzt wird.
-
Erklären Sie, wieso im Visitor-Pattern in der accept-Methode der Knoten der Aufruf visitor.visit(this)
genutzt wird. Erklären Sie, wieso dieser Aufruf nicht in der Oberklasse bzw. im gemeinsamen Interface der
Knoten implementiert werden kann.
-
Erklären Sie, wieso im Visitor-Pattern in der visit-Methode der Visitoren statt visit(node.left()) der
Aufruf node.left().accept(this) genutzt wird.
Quellen
- [Eilebrecht2013] Patterns kompakt
Eilebrecht, K. und Starke, G., Springer, 2013. ISBN 978-3-6423-4718-4. - [Gamma2011] Design Patterns
Gamma, E. und Helm, R. und Johnson, R. E. und Vlissides, J., Addison-Wesley, 2011. ISBN 978-0-2016-3361-0.
Observer-Pattern
TL;DR
Eine Reihe von Objekten möchte über eine Änderung in einem anderen ("zentralen") Objekt informiert werden.
Dazu könnte das "zentrale" Objekt eine Zugriffsmethode anbieten, die die anderen Objekte regelmäßig
abrufen ("pollen").
Mit dem Observer-Pattern kann man das aktive Polling vermeiden. Die interessierten Objekte "registrieren"
sich beim "zentralen" Objekt. Sobald dieses eine Änderung erfährt oder Informationen bereitstehen o.ä.,
wird das "zentrale" Objekt alle registrierten Objekte über den Aufruf einer Methode benachrichtigen. Dazu
müssen diese eine gemeinsame Schnittstelle implementieren.
Das "zentrale" Objekt, welches abgefragt wird, nennt man "Observable" oder "Subject". Die Objekte, die
die Information abfragen möchten, nennt man "Observer".
Videos (HSBI-Medienportal)
Lernziele
- (K2) Aufbau des Observer-Patterns (Beobachter-Entwurfsmusters)
- (K3) Anwendung des Observer-Patterns auf konkrete Beispiele, etwa den PM-Dungeon
Verteilung der Prüfungsergebnisse

Die Studierenden möchten nach einer Prüfung wissen, ob für einen bestimmten Kurs
die/ihre Prüfungsergebnisse im LSF bereit stehen.
Dazu modelliert man eine Klasse LSF und implementiert eine Abfragemethode, die
dann alle Objekte regelmäßig aufrufen können. Dies sieht dann praktisch etwa so
aus:
final Person[] persons = { new Lecturer("Frau Holle"),
new Student("Heinz"),
new Student("Karla"),
new Tutor("Kolja"),
new Student("Wuppie") };
final LSF lsf = new LSF();
for (Person p : persons) {
lsf.getGradings(p, "My Module"); // ???!
}
Elegantere Lösung: Observer-Entwurfsmuster

Sie erstellen im LSF eine Methode register(), mit der sich interessierte Objekte
beim LSF registrieren können.
Zur Benachrichtigung der registrierten Objekte brauchen diese eine geeignete Methode,
die traditionell update() genannt wird.
Observer-Pattern verallgemeinert

Im vorigen Beispiel wurde die Methode update() einfach der gemeinsamen Basisklasse Person
hinzugefügt. Normalerweise möchte man die Aspekte Person und Observer aber sauber trennen
und definiert sich dazu ein separates Interface Observer mit der Methode update(), die
dann alle "interessierten" Klassen (zusätzlich zur bestehenden Vererbungshierarchie) implementieren.
Die Klasse für das zu beobachtende Objekt benötigt dann eine Methode register(), mit der sich
Observer registrieren können. Die Objektreferenzen werden dabei einfach einer internen Sammlung
hinzugefügt.
Häufig findet sich dann noch eine Methode unregister(), mit der sich bereits registrierte
Beobachter wieder abmelden können. Weiterhin findet man häufig eine Methode notifyObservers(),
die man von außen auf dem beobachteten Objekt aufrufen kann und die dann auf allen registrierten
Beobachtern deren Methoden update() aufruft. (Dieser Vorgang kann aber auch durch eine sonstige
Zustandsänderung im beobachteten Objekt durchgeführt werden.)
In der Standarddefinition des Observer-Patterns nach [Gamma2011] werden beim Aufruf der Methode
update() keine Werte an die Beobachter mitgegeben. Der Beobachter muss sich entsprechend eine
eigene Referenz auf das beobachtete Objekt halten, um dort dann weitere Informationen erhalten
zu können. Dies kann vereinfacht werden, indem das beobachtete Objekt beim Aufruf der
update()-Methode die Informationen als Parameter mitgibt, beispielsweise eine Referenz auf sich
selbst o.ä. ... Dies muss dann natürlich im Observer-Interface nachgezogen werden.
Hinweis: Es gibt in Swing bereits die Interfaces Observer und Observable, die aber als
"deprecated" gekennzeichnet sind. Sinnvollerweise nutzen Sie nicht diese Interfaces aus Swing,
sondern implementieren Ihre eigenen Interfaces, wenn Sie das Observer-Pattern einsetzen wollen!
Wrap-Up
Observer-Pattern: Benachrichtige registrierte Objekte über Statusänderungen
- Interface
Observer mit Methode update()
- Interessierte Objekte
- implementieren das Interface
Observer
- registrieren sich beim zu beobachtenden Objekt (
Observable)
- Beobachtetes Objekt ruft auf allen registrierten Objekten
update() auf
update() kann auch Parameter haben
Challenges
In den Vorgaben
finden Sie ein Modell für eine Lieferkette zwischen Großhandel und Einzelhandel.
Wenn beim Einzelhändler eine Bestellung von einem Kunden eingeht (Einzelhandel#bestellen), speichert
dieser den Auftrag zunächst in einer Liste ab. In regelmäßigen Abständen (Einzelhandel#loop) sendet
der Einzelhändler die offenen Bestellungen an seinen Großhändler (Grosshandel#bestellen). Hat der
Großhändler die benötigte Ware vorrätig, sendet er diese an den Einzelhändler (Einzelhandel#empfangen).
Dieser kann dann den Auftrag gegenüber seinem Kunden erfüllen (keine Methode vorgesehen).
Anders als der Einzelhandel speichert der Großhandel keine Aufträge ab. Ist die benötigte Ware bei einer
Bestellung also nicht oder nicht in ausreichender Zahl auf Lager, wird diese nicht geliefert und der
Einzelhandel muss (später) eine neue Bestellung aufgeben.
Der Großhandel bekommt regelmäßig (Grosshandel#loop) neue Ware für die am wenigsten vorrätigen Positionen.
Im aktuellen Modell wird der Einzelhandel nicht über den neuen Lagerbestand des Großhändlers informiert
und kann daher nur "zufällig" neue Bestellanfragen an den Großhändler senden.
Verbessern Sie das Modell, indem Sie das Observer-Pattern integrieren. Wer ist Observer? Wer ist Observable?
Welche Informationen werden bei einem update mitgeliefert?
Bauen Sie in alle Aktionen vom Einzelhändler und vom Großhändler passendes Logging ein.
Anmerkung: Sie dürfen nur die Vorgaben-Klassen Einzelhandel und Grosshandel verändern, die anderen
Vorgaben-Klassen dürfen Sie nicht bearbeiten. Sie können zusätzlich benötigte eigene Klassen/Interfaces
implementieren.
Command-Pattern
TL;DR
Das Command-Pattern ist die objektorientierte Antwort auf Callback-Funktionen: Man
kapselt Befehle in einem Objekt.
-
Die Command-Objekte haben eine Methode execute() und führen dabei Aktion auf einem
bzw. "ihrem" Receiver aus.
-
Receiver sind Objekte, auf denen Aktionen ausgeführt werden, im Dungeon könnten dies
etwa Hero, Monster, ... sein. Receiver müssen keine der anderen Akteure in diesem Pattern
kennen.
-
Damit die Command-Objekte aufgerufen werden, gibt es einen Invoker, der
Command-Objekte hat und zu gegebener Zeit auf diesen die Methode execute() aufruft.
Der Invoker muss dabei die konkreten Kommandos und die Receiver nicht kennen (nur die
Command-Schnittstelle).
-
Zusätzlich gibt es einen Client, der die anderen Akteure kennt und alles zusammen baut.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Aufbau des Command-Patterns
- (K3) Anwendung des Command-Patterns auf konkrete Beispiele, etwa den PM-Dungeon
Motivation
Irgendwo im Dungeon wird es ein Objekt einer Klasse ähnlich wie InputHandler
geben mit einer Methode ähnlich zu handleInput():
public class InputHandler {
public void handleInput() {
switch (keyPressed()) {
case BUTTON_W -> hero.jump();
case BUTTON_A -> hero.moveX();
case ...
default -> { ... }
}
}
}
Diese Methode wird je Frame einmal aufgerufen, um auf eventuelle Benutzereingaben
reagieren zu können. Je nach gedrücktem Button wird auf dem Hero eine bestimmte
Aktion ausgeführt ...
Das funktioniert, ist aber recht unflexibel. Die Aktionen sind den Buttons fest
zugeordnet und erlauben keinerlei Konfiguration.
Auflösen der starren Zuordnung über Zwischenobjekte
public interface Command { void execute(); }
public class Jump implements Command {
private Entity e;
public void execute() { e.jump(); }
}
public class InputHandler {
private final Command wbutton = new Jump(hero); // Über Ctor/Methoden setzen!
private final Command abutton = new Move(hero); // Über Ctor/Methoden setzen!
public void handleInput() {
switch (keyPressed()) {
case BUTTON_W -> wbutton.execute();
case BUTTON_A -> abutton.execute();
case ...
default -> { ... }
}
}
}
Die starre Zuordnung "Button : Aktion" wird aufgelöst und über Zwischenobjekte konfigurierbar
gemacht.
Für die Zwischenobjekte wird ein Typ Command eingeführt, der nur eine execute()-Methode
hat. Für jede gewünschte Aktion wird eine Klasse davon abgeleitet, diese Klassen können auch
einen Zustand pflegen.
Den Buttons wird nun an geeigneter Stelle (Konstruktor, Methoden, ...) je ein Objekt der
jeweiligen Command-Unterklassen zugeordnet. Wenn ein Button betätigt wird, wird auf dem
Objekt die Methode execute() aufgerufen.
Damit die Kommandos nicht nur auf den Helden wirken können, kann man den Kommando-Objekten
beispielsweise noch eine Entität mitgeben, auf der das Kommando ausgeführt werden soll. Im
Beispiel oben wurde dafür der hero genutzt.
Command: Objektorientierte Antwort auf Callback-Funktionen

Im Command-Pattern gibt es vier beteiligte Parteien: Client, Receiver, Command und Invoker.
Ein Command ist die objektorientierte Abstraktion eines Befehls. Es hat möglicherweise
einen Zustand, und und kennt "seinen" Receiver und kann beim Aufruf der execute()-Methode
eine vorher verabredete Methode auf diesem Receiver-Objekt ausführen.
Ein Receiver ist eine Klasse, die Aktionen durchführen kann. Sie kennt die anderen Akteure
nicht.
Der Invoker (manchmal auch "Caller" genannt) ist eine Klasse, die Commands aggregiert und die
die Commandos "ausführt", indem hier die execute()-Methode aufgerufen wird. Diese Klasse
kennt nur das Command-Interface und keine spezifischen Kommandos (also keine der Sub-Klassen).
Es kann zusätzlich eine gewisse Buchführung übernehmen, etwa um eine Undo-Funktionalität zu
realisieren.
Der Client ist ein Programmteil, der ein Command-Objekt aufbaut und dabei einen passenden
Receiver übergibt und der das Command-Objekt dann zum Aufruf an den Invoker weiterreicht.
In unserem Beispiel lassen sich die einzelnen Teile so sortieren:
- Client: Klasse
InputHandler (erzeugt neue Command-Objekte im obigen Code) bzw. main(),
wenn man die Command-Objekte dort erstellt und an den Konstruktor von InputHandler
weiterreicht
- Receiver: Objekt
hero der Klasse Hero (auf diesem wird eine Aktion ausgeführt)
- Command:
Jump und Move
- Invoker:
InputHandler (in der Methode handleInput())
Undo
Wir könnten das Command-Interface um ein paar Methoden erweitern:
public interface Command {
void execute();
void undo();
Command newCommand(Entity e);
}
Jetzt kann jedes Command-Objekt eine neue Instanz erzeugen mit der
Entity, die dann dieses Kommando empfangen soll:
public class Move implements Command {
private Entity e;
private int x, y, oldX, oldY;
public void execute() { oldX = e.getX(); oldY = e.getY(); x = oldX + 42; y = oldY; e.moveTo(x, y); }
public void undo() { e.moveTo(oldX, oldY); }
public Command newCommand(Entity e) { return new Move(e); }
}
public class InputHandler {
private final Command wbutton;
private final Command abutton;
private final Stack<Command> s = new Stack<>();
public void handleInput() {
Entity e = getSelectedEntity();
switch (keyPressed()) {
case BUTTON_W -> { s.push(wbutton.newCommand(e)); s.peek().execute(); }
case BUTTON_A -> { s.push(abutton.newCommand(e)); s.peek().execute(); }
case BUTTON_U -> s.pop().undo();
case ...
default -> { ... }
}
}
}
Über den Konstruktor von InputHandler (im Beispiel nicht gezeigt) würde man
wie vorher die Command-Objekte für die Buttons setzen. Es würde aber in jedem
Aufruf von handleInput() abgefragt, was gerade die selektierte Entität ist und
für diese eine neue Instanz des zur Tastatureingabe passenden Command-Objekts
erzeugt. Dieses wird nun in einem Stack gespeichert und danach ausgeführt.
Wenn der Button "U" gedrückt wird, wird das letzte Command-Objekt aus dem
Stack genommen (Achtung: Im echten Leben müsste man erst einmal schauen, ob hier
noch was drin ist!) und auf diesem die Methode undo() aufgerufen. Für das
Kommando Move ist hier skizziert, wie ein Undo aussehen könnte: Man muss einfach
bei jedem execute() die alte Position der Entität speichern, dann kann man
sie bei einem undo() wieder auf diese Position verschieben. Da für jeden Move
ein neues Objekt angelegt wird und dieses nur einmal benutzt wird, braucht man
keine weitere Buchhaltung ...
Wrap-Up
Command-Pattern: Kapsele Befehle in ein Objekt
Command-Objekte haben eine Methode execute() und führen darin Aktion auf Receiver ausReceiver sind Objekte, auf denen Aktionen ausgeführt werden (Hero, Monster, ...)Invoker hat Command-Objekte und ruft darauf execute() aufClient kennt alle und baut alles zusammen
Objektorientierte Antwort auf Callback-Funktionen
Challenges
Schreiben Sie für den Dwarf in den
Vorgaben
einen Controller, welcher das Command-Pattern verwendet.
- "W" führt Springen aus
- "A" bewegt den Zwerg nach links
- "D" bewegt den Zwerg nach rechts
- "S" führt Ducken aus
Schreiben Sie zusätzlich für den Cursor einen Controller, welcher das Command-Pattern mit Historie
erfüllt (ebenfalls über die Tasten "W", "A", "S" und "D").
Schreiben Sie eine Demo, um die Funktionalität Ihres Programmes zu demonstrieren.
Singleton-Pattern
TL;DR
Wenn von einer Klasse nur genau ein Objekt angelegt werden kann, nennt man dies auch das
"Singleton-Pattern".
Dazu muss verhindert werden, dass der Konstruktor aufgerufen werden kann. Üblicherweise
"versteckt" man diesen einfach (Sichtbarkeit auf private setzen). Für den Zugriff auf
die Instanz bietet man eine statische Methode an.
Im Prinzip kann man die Instanz direkt beim Laden der Klasse anlegen ("Eager") oder
abwarten, bis die Instanz über die statische Methode angefordert wird, und das Objekt
erst dann anlegen ("Lazy").
Videos (HSBI-Medienportal)
Lernziele
- (K2) Was ist ein Singleton? Was ist der Unterschied zw. einem Lazy und einem Eager Singleton?
- (K3) Anwendung des Singleton-Patterns
Motivation
public enum Fach { IFM, ELM, ARC }
Logger l = Logger.getLogger(MyClass.class.getName());
Von den Enum-Konstanten soll es nur genau eine Instantiierung, also jeweils nur genau ein Objekt
geben. Ähnlich war es beim Logging: Für jeden Namen soll/darf es nur einen tatsächlichen Logger
(== Objekt) geben.
Dies nennt man "Singleton Pattern".
Anmerkung: Im Logger-Fall handelt es sich streng genommen nicht um ein Singleton, da es vom
Logger mehrere Instanzen geben kann (wenn der Name sich unterscheidet). Aber jeden Logger mit
einem bestimmten Namen gibt es nur einmal im ganzen Programm, insofern ist es doch wieder ein
Beispiel für das Singleton-Pattern ...
Umsetzung: "Eager" Singleton Pattern
Damit man von "außen" keine Instanzen einer Klasse anlegen kann, versteckt man den Konstruktor,
d.h. man setzt die Sichtbarkeit auf private. Zusätzlich benötigt man eine Methode, die das
Objekt zurückliefern kann. Beim Logger war dies beispielsweise der Aufruf Logger.getLogger("name").
Man kann verschiedene Ausprägungen bei der Umsetzung des Singleton Patterns beobachten. Die
beiden wichtigsten sind das "Eager Singleton Pattern" und das "Lazy Singleton Pattern". Der
Unterschied liegt darin, wann genau das Objekt erzeugt wird: Beim "Eager Singleton Pattern"
wird es direkt beim Laden der Klasse erzeugt.
public class SingletonEager {
private static final SingletonEager inst = new SingletonEager();
// Privater Constructor: Niemand kann Objekte außerhalb der Klasse anlegen
private SingletonEager() {}
public static SingletonEager getInst() {
return inst;
}
}
Umsetzung: "Lazy" Singleton Pattern
Beim "Lazy Singleton Pattern" wird das Objekt erst erzeugt, wenn die Instanz tatsächlich benötigt
wird (also erst beim Aufruf der get-Methode).
public class SingletonLazy {
private static SingletonLazy inst = null;
// Privater Constructor: Niemand kann Objekte außerhalb der Klasse anlegen
private SingletonLazy() {}
public static SingletonLazy getInst() {
// Thread-safe. Kann weggelassen werden bei Single-Threaded-Gebrauch
synchronized (SingletonLazy.class) {
if (inst == null) {
inst = new SingletonLazy();
}
}
return inst;
}
}
Vorsicht!
Sie schaffen damit eine globale Variable!
Da es von der Klasse nur eine Instanz gibt, und Sie sich diese dank der statischen Methode an jeder
Stelle im Programm "geben" lassen können, haben Sie in der Praxis eine globale Variable geschaffen.
Das kann direkt zu schlechter Programmierung (ver-) führen. Zudem wird der Code schwerer lesbar/navigierbar,
da diese Singletons nicht über die Schnittstellen von Methoden übergeben werden müssen.
Nutzen Sie das Pattern sparsam.
Wrap-Up
Singleton-Pattern: Klasse, von der nur genau ein Objekt instantiiert werden kann
- Konstruktor "verstecken" (Sichtbarkeit auf
private setzen)
- Methode zum Zugriff auf die eine Instanz
- Anlegen der Instanz beispielsweise beim Laden der Klasse ("Eager") oder
beim Aufruf der Zugriffsmethode ("Lazy")
Template-Method-Pattern
TL;DR
Das Template-Method-Pattern ist ein Entwurfsmuster, bei dem ein gewisses Verhalten
in einer Methode implementiert wird, die wie eine Schablone agiert, der sogenannten
"Template-Methode". Darin werden dann u.a. Hilfsmethoden aufgerufen, die in der
Basisklasse entweder als abstract markiert sind oder mit einem leeren Body
implementiert sind ("Hook-Methoden"). Über diese Template-Methode legt also die
Basisklasse ein gewisses Verhaltensschema fest ("Template") - daher auch der Name.
In den ableitenden Klassen werden dann die abstrakten Methoden und/oder die Hook-Methoden
implementiert bzw. überschrieben und damit das Verhalten verfeinert.
Zur Laufzeit ruft man auf den Objekten die Template-Methode auf. Dabei wird von der
Laufzeitumgebung der konkrete Typ der Objekte bestimmt (auch wenn man sie unter dem
Typ der Oberklasse führt) und die am tiefsten in der Vererbungshierarchie implementierten
Methoden aufgerufen. D.h. die Aufrufe der Hilfsmethoden in der Template-Methode führen
zu den in der jeweiligen ableitenden Klasse implementierten Varianten.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Template-Method-Entwurfsmuster praktisch anwenden
Motivation: Syntax-Highlighting im Tokenizer
In einem Compiler ist meist der erste Arbeitsschritt, den Eingabestrom in einzelne
Token aufzubrechen. Dies sind oft die verschiedenen Schlüsselwörter, Operationen,
Namen von Variablen, Methoden, Klassen etc. ... Aus der Folge von Zeichen (also dem
eingelesenen Programmcode) wird ein Strom von Token, mit dem die nächste Stufe im
Compiler dann weiter arbeiten kann.
public class Lexer {
private final List<Token> allToken; // alle verfügbaren Token-Klassen
public List<Token> tokenize(String string) {
List<Token> result = new ArrayList<>();
while (string.length() > 0) {
for (Token t : allToken) {
Token token = t.match(string);
if (token != null) {
result.add(token);
string = string.substring(token.getContent().length(), string.length());
}
}
}
return result;
}
}
Dazu prüft man jedes Token, ob es auf den aktuellen Anfang des Eingabestroms passt.
Wenn ein Token passt, erzeugt man eine Instanz dieser Token-Klasse und speichert darin
den gematchten Eingabeteil, den man dann vom Eingabestrom entfernt. Danach geht man
in die Schleife und prüft wieder alle Token ... bis irgendwann der Eingabestrom leer
ist und man den gesamten eingelesenen Programmcode in eine dazu passende Folge von
Token umgewandelt hat.
Anmerkung: Abgesehen von fehlenden Javadoc etc. hat das obige Code-Beispiel mehrere
Probleme: Man würde im realen Leben nicht mit String, sondern mit einem Zeichenstrom
arbeiten. Außerdem fehlt noch eine Fehlerbehandlung, wenn nämlich keines der Token in
der Liste allToken auf den aktuellen Anfang des Eingabestroms passt.
Um den eigenen Tokenizer besser testen zu können, wurde beschlossen, dass jedes Token
seinen Inhalt als formatiertes HTML-Schnipsel zurückliefern soll. Damit kann man dann
alle erkannten Token formatiert ausgeben und erhält eine Art Syntax-Highlighting für
den eingelesenen Programmcode.
public abstract class Token {
protected String content;
abstract protected String getHtml();
}
public class KeyWord extends Token {
@Override
protected String getHtml() {
return "<font color=\"red\"><b>" + this.content + "</b></font>";
}
}
public class StringContent extends Token {
@Override
protected String getHtml() {
return "<font color=\"green\">" + this.content + "</font>";
}
}
Token t = new KeyWord();
LOG.info(t.getHtml());
In der ersten Umsetzung erhält die Basisklasse Token eine weitere abstrakte
Methode, die jede Token-Klasse implementieren muss und in der die Token-Klassen
einen String mit dem Token-Inhalt und einer Formatierung für HTML zurückgeben.
Dabei fällt auf, dass der Aufbau immer gleich ist: Es werden ein oder mehrere
Tags zum Start der Format-Sequenz mit dem Token-Inhalt verbunden, gefolgt mit
einem zum verwendeten startenden HTML-Format-Tag passenden End-Tag.
Auch wenn die Inhalte unterschiedlich sind, sieht das stark nach einer Verletzung
von DRY aus ...
Don't call us, we'll call you
public abstract class Token {
protected String content;
public final String getHtml() {
return htmlStart() + this.content + htmlEnd();
}
abstract protected String htmlStart();
abstract protected String htmlEnd();
}
public class KeyWord extends Token {
@Override protected String htmlStart() { return "<font color=\"red\"><b>"; }
@Override protected String htmlEnd() { return "</b></font>"; }
}
public class StringContent extends Token {
@Override protected String htmlStart() { return "<font color=\"green\">"; }
@Override protected String htmlEnd() { return "</font>"; }
}
Token t = new KeyWord();
LOG.info(t.getHtml());
Wir können den Spaß einfach umdrehen ("inversion of control")
und die Methode zum Zusammenbasteln des HTML-Strings bereits in der Basisklasse
implementieren. Dazu "rufen" wir dort drei Hilfsmethoden auf, die die jeweiligen
Bestandteile des Strings (Format-Start, Inhalt, Format-Ende) erzeugen und deren
konkrete Implementierung wir in der Basisklasse nicht kennen. Dies ist dann Sache
der ableitenden konkreten Token-Klassen.
Objekte vom Typ KeyWord sind dank der Vererbungsbeziehung auch Token (Vererbung:
is-a-Beziehung). Wenn man nun auf einem Token t die Methode getHtml() aufruft,
wird zur Laufzeit geprüft, welchen Typ t tatsächlich hat (im Beispiel KeyWord).
Methodenaufrufe werden dann mit den am tiefsten in der vorliegenden Vererbungshierarchie
implementierten Methoden durchgeführt: Hier wird also die von Token geerbte Methode
getHtml() in KeyWord aufgerufen, die ihrerseits die Methoden htmlStart() und
htmlEnd() aufruft. Diese sind in KeyWord implementiert und liefern nun die passenden
Ergebnisse.
Die Methode getHtml() wird auch als "Template-Methode" bezeichnet. Die beiden darin
aufgerufenen Methoden htmlStart() und htmlEnd() in Token werden auch als "Hilfsmethoden"
(oder "Helper Methods") bezeichnet.
Dies ist ein Beispiel für das Template-Method-Pattern.
Template-Method-Pattern

Aufbau Template-Method-Pattern
In der Basisklasse implementiert man eine Template-Methode (in der Skizze templateMethod),
die sich auf anderen in der Basisklasse deklarierten (Hilfs-) Methoden "abstützt" (diese also
aufruft; in der Skizze method1, method2, method3). Diese Hilfsmethoden können als
abstract markiert werden und müssen dann von den ableitenden Klassen implementiert werden
(in der Skizze method1 und method2). Man kann aber auch einige/alle dieser aufgerufenen
Hilfsmethoden in der Basisklasse implementieren (beispielsweise mit einem leeren Body - sogenannte
"Hook"-Methoden) und die ableitenden Klassen können dann diese Methoden überschreiben und das
Verhalten so neu formulieren (in der Skizze method3).
Damit werden Teile des Verhaltens an die ableitenden Klassen ausgelagert.
Verwandtschaft zum Strategy-Pattern
Das Template-Method-Pattern hat eine starke Verwandtschaft zum Strategy-Pattern.
Im Strategy-Pattern haben wir Verhalten komplett an andere Objekte delegiert, indem wir in
einer Methode einfach die passende Methode auf dem übergebenen Strategie-Objekt aufgerufen haben.
Im Template-Method-Pattern nutzen wir statt Delegation die Mechanismen Vererbung und dynamische
Polymorphie und definieren in der Basis-Klasse abstrakte oder Hook-Methoden, die wir bereits in
der Template-Methode der Basis-Klasse aufrufen. Damit ist das grobe Verhalten in der Basis-Klasse
festgelegt, wird aber in den ableitenden Klassen durch das dortige Definieren oder Überschreiben
der Hilfsmethoden verfeinert. Zur Laufzeit werden dann durch die dynamische Polymorphie die
tatsächlich implementierten Hilfsmethoden in den ableitenden Klassen aufgerufen. Damit lagert man
im Template-Method-Pattern gewissermaßen nur Teile des Verhaltens an die ableitenden Klassen aus.
Wrap-Up
Template-Method-Pattern: Verhaltensänderung durch Vererbungsbeziehungen
- Basis-Klasse:
- Template-Methode, die Verhalten definiert und Hilfsmethoden aufruft
- Hilfsmethoden: Abstrakte Methoden (oder "Hook": Basis-Implementierung)
- Ableitende Klassen: Verfeinern Verhalten durch Implementieren der Hilfsmethoden
- Zur Laufzeit: Dynamische Polymorphie: Aufruf der Template-Methode nutzt
die im tatsächlichen Typ des Objekts implementierten Hilfsmethoden
Challenges
Schreiben Sie eine abstrakte Klasse Drucker. Implementieren Sie die Funktion
kopieren, bei der zuerst die Funktion scannen und dann die Funktion drucken
aufgerufen wird. Der Kopiervorgang ist für alle Druckertypen identisch,
das Scannen und Drucken ist abhängig vom Druckertyp.
Implementieren Sie zusätzlich zwei unterschiedliche Druckertypen.
Tintendrucker extends DruckerLaserdrucker extends DruckerTintendrucker#scannen loggt den Text "Scanne das Dokument mit dem Tintendrucker."Laserdrucker#scannen loggt den Text "Scanne das Dokument mit dem Laserdrucker."Tintendrucker#drucken loggt den Text "Drucke das Dokument auf dem Tintendrucker."Laserdrucker#drucken loggt den Text "Drucke das Dokument auf dem Laserdrucker."
Nutzen Sie das Template-Method-Pattern.
Quellen
- [Eilebrecht2013] Patterns kompakt
Eilebrecht, K. und Starke, G., Springer, 2013. ISBN 978-3-6423-4718-4. - [Gamma2011] Design Patterns
Gamma, E. und Helm, R. und Johnson, R. E. und Vlissides, J., Addison-Wesley, 2011. ISBN 978-0-2016-3361-0.
Factory-Method-Pattern
TL;DR
Oft ist es wünschenswert, dass Nutzer nicht direkt Objekte von bestimmten Klassen anlegen (können).
Hier kann eine "Fabrik-Methode" (Factory-Method) helfen, der man die gewünschten Parameter
übergibt und die daraus dann das passende Objekt (der richtigen Klasse) erzeugt und zurückliefert.
Dadurch erreicht man eine höhere Entkoppelung, die Nutzer müssen nur noch das Interface oder die
abstrakte Klasse, also den Obertyp des Ergebnisses kennen. Außerdem lassen sich so leicht die
konkreten Klassen austauschen.
Dieses Entwurfsmuster kommt häufig zusammen mit dem Singleton-Pattern vor, wo es nur eine einzige
Instanz einer Klasse geben soll. Über eine Fabrik-Methode kann man diese Instanz ggf. erzeugen und
dann die Referenz darauf zurückliefern.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Entwurfsmuster Factory-Methode anwenden
Motivation: Ticket-App
=> Factory-Method-Pattern: Objekte sollen nicht direkt durch den Nutzer erzeugt werden
Factory-Method-Pattern

Hands-On: Ticket-App
Implementieren Sie eine Ticket-App, die verschiedene Tickets mit
Hilfe des Factory-Method Entwurfsmusters generiert.
Wrap-Up
-
Konkrete Objekte sollen nicht direkt über Konstruktor erzeugt werden
-
(Statische) Hilfsmethode, die aus Parameter das "richtige" Objekte erzeugt
-
Vorteil:
- Nutzer kennt nur das Interface
- Konkrete Klassen lassen sich leicht austauschen
Challenges
Ein Kunde kommt in unser Computergeschäft und möchte bei uns einen Computer
bestellen. Dabei gibt er an, wie er diesen vorwiegend nutzen möchte bzw. für
welchen Zweck er gedacht ist ("stationär" oder "mobil"). Nach reichlicher
Überlegung, ob er den neuen Rechner zu Hause stehen haben möchte oder lieber
keinen weiteren Rechner, egal ob "mobil" oder "stationär", bei sich im Weg
herumstehen haben will, teilt er Ihnen seine Entscheidung darüber mit
("stationär" oder "mobil" vs. "nicht daheim"). Bei diesem Gespräch merkt er
beiläufig an, dass es ein Rechner mit "viel Wumms" sein könnte oder vielleicht
doch besser etwas Kleines, was leise vor sich hin schnurrt ("viel Wumms" vs.
"leise schnurrend").
Je nach gewünschter Konfiguration soll ein den oben genannten Auswahlkriterien
entsprechender Rechner mit den aus der unten stehenden Konfigurationsmatrix zu
entnehmenden Eigenschaften automatisch erzeugt werden. Die Größe des installierten
RAM, die Anzahl der eingebauten CPU-Kerne mit ihrer jeweiligen Taktrate,
sowie die Art und Größe der installierten Festplatte (HDD oder SSD) sollte
dabei zu dem gewählten Paket passend gesetzt werden.
Implementieren Sie eine "Computerfabrik" (Klasse ComputerFactory), die Ihnen
den richtig konfigurierten Rechner zusammenbaut. Nutzen Sie dabei das
"Factory-Method-Pattern" zum Erzeugen der Objekte der einzelnen Subklassen. Dabei
soll Ihre Computerfabrik anhand der ihr übergebenen Konfiguration eigenständig
entscheiden, welche Art von Computer dabei erstellt werden soll.
Implementieren Sie dazu in Ihrer Factory die Factory-Methode buildComputer,
welche das jeweils passend konfigurierte Objekt zurückgibt.
public class ComputerFactory {
...
public static Computer buildComputer(..."stationär",..."viel Wumms") {
...
return myComputer;
}
}
Konfigurationsmatrix
|
"stationär" (DesktopComputer) |
"mobil" (LaptopComputer) |
"nicht daheim" (CloudComputer) |
| "leise schnurrend" |
8 Cores, 1.21GHZ, 16GB RAM, 256GB HDD |
4 Cores, 1.21GHZ, 8GB RAM, 256GB HDD |
8 Cores, 1.21GHZ, 24GB RAM, 1000GB HDD |
| "viel Wumms" |
16 Cores, 4.2GHZ, 32GB RAM, 2000GB SSD |
8 Cores, 2.4GHZ, 16GB RAM, 256GB SSD |
42 Cores, 9.001GHZ, 128GB RAM, 10000GB SSD |
Quellen
- [Eilebrecht2013] Patterns kompakt
Eilebrecht, K. und Starke, G., Springer, 2013. ISBN 978-3-6423-4718-4. - [Gamma2011] Design Patterns
Gamma, E. und Helm, R. und Johnson, R. E. und Vlissides, J., Addison-Wesley, 2011. ISBN 978-0-2016-3361-0. - [Kleuker2018] Grundkurs Software-Engineering mit UML
Kleuker, S., Springer Vieweg, 2018. ISBN 978-3-658-19969-2. DOI 10.1007/978-3-658-19969-2.
Type-Object-Pattern
TL;DR
Das Type-Object-Pattern dient dazu, die Anzahl der Klassen auf Code-Ebene zu reduzieren und
durch eine Konfiguration zu ersetzen und damit eine höhere Flexibilität zu erreichen.
Dazu werden sogenannte Type-Objects definiert: Sie enthalten genau die Eigenschaften, die
in verschiedenen (Unter-) Klassen gemeinsam vorkommen. Damit können diese Eigenschaften
aus den ursprünglichen Klassen entfernt und durch eine Referenz auf ein solches Type-Object
ersetzt werden. In den Klassen muss man dann nur noch die für die einzelnen Typen
individuellen Eigenschaften implementieren. Zusätzlich kann man nun verschiedene (Unter-)
Klassen zusammenlegen, da der Typ über das geteilte Type-Object definiert wird (zur Laufzeit)
und nicht mehr durch eine separate Klasse auf Code-Ebene repräsentiert werden muss.
Die Type-Objects werden zur Laufzeit mit den entsprechenden Ausprägungen der früheren (Unter-)
Klassen angelegt und dann über den Konstruktor in die nutzenden Objekte übergeben. Dadurch
teilen sich alle Objekte einer früheren (Unter-) Klasse das selbe Type-Objekt und zeigen nach
außen das selbe Verhalten. Die Type-Objects werden häufig über eine entsprechende
Konfiguration erzeugt, so dass man beispielsweise unterschiedliche Monsterklassen und
-eigenschaften ausprobieren kann, ohne den Code neu kompilieren zu müssen. Man kann
sogar eine Art "Vererbung" unter den Type-Objects implementieren.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Verschieben des Typ-definierenden Teils der Eigenschaften in ein Type-Object
- (K2) Erklären der Ähnlichkeit zum Flyweight-Pattern
- (K3) Praktischer Einsatz des Type-Object-Patterns
Motivation: Monster und spezialisierte Monster
public abstract class Monster {
protected int attackDamage;
protected int movementSpeed;
public Monster(int attackDamage, int movementSpeed) { ... }
public void attack(Monster m) { ... }
}
public class Rat extends Monster {
public Rat() { super(10, 10); } // Ratten haben 10 Damage und 10 Speed
@Override public void attack(Monster m) { ... }
}
public class Gnoll extends Monster { ... }
public static void main(String[] args) {
Monster harald = new Rat();
Monster eve = new Gnoll();
...
}
Sie haben sich eine Monster-Basisklasse geschrieben. Darin gruppieren Sie typische
Eigenschaften eines Monsters: Es kann sich mit einer bestimmten Geschwindigkeit
bewegen und es kann anderen Monstern bei einem Angriff einen bestimmten Schaden
zufügen.
Um nun andere Monstertypen zu erzeugen, greifen Sie zur Vererbung und leiten von
der Basisklasse Ihre spezialisierten Monster ab und überschreiben die Defaultwerte
und bei Bedarf auch das Verhalten (die Methoden).
Damit entsteht aber recht schnell eine tiefe und verzweigte Vererbungshierarchie,
Sie müssen ja für jede Variation eine neue Unterklasse anlegen. Außerdem müssen
für jede (noch so kleine) Änderung an den Monster-Eigenschaften viele Klassen
editiert und das gesamte Projekt neu kompiliert werden.
Es würde auch nicht wirklich helfen, die Eigenschaften der Unterklassen über
deren Konstruktor einstellbar zu machen (die Rat könnte in ihrem Konstruktor
beispielsweise noch die Werte für Damage und Speed übergeben bekommen). Dann
würden die Eigenschaften an allen Stellen im Programm verstreut, wo Sie den
Konstruktor aufrufen.
Vereinfachen der Vererbungshierarchie (mit Enums als Type-Object)
public enum Species { RAT, GNOLL, ... }
public final class Monster {
private final Species type;
private int attackDamage;
private int movementSpeed;
public Monster(Species type) {
switch (type) {
case RAT: attackDamage = 10; movementSpeed = 10; break;
...
}
}
public void attack(Monster m) { ... }
}
public static void main(String[] args) {
Monster harald = new Monster(Species.RAT);
Monster eve = new Monster(Species.GNOLL);
...
}
Die Lösung für die Vermeidung der Vererbungshierarchie: Die Monster-Basisklasse bekommt ein
Attribut, welches den Typ des Monsters bestimmt (das sogenannte "Type-Object"). Das könnte
wie im Beispiel ein einfaches Enum sein, das in den Methoden des Monsters abgefragt wird.
So kann zur Laufzeit bei der Erzeugung der Monster-Objekte durch Übergabe des Enums bestimmt
werden, was genau dieses konkrete Monster genau ist bzw. wie es sich verhält.
Im obigen Beispiel wird eine Variante gezeigt, wo das Enum im Konstruktor ausgewertet
wird und die Attribute entsprechend gesetzt werden. Man könnte das auch so implementieren,
dass man auf die Attribute verzichtet und stattdessen stets das Enum auswertet.
Allerdings ist das Hantieren mit den Enums etwas umständlich: Man muss an allen Stellen,
wo das Verhalten der Monster unterschiedlich ist, ein switch/case einbauen und den Wert
des Type-Objects abfragen. Das bedeutet einerseits viel duplizierten Code und andererseits
muss man bei Erweiterungen des Enums auch alle switch/case-Blöcke anpassen.
Monster mit Strategie
public final class Species {
private final int attackDamage;
private final int movementSpeed;
private final int xp;
public Species(int attackDamage, int movementSpeed, int xp) { ... }
public void attack(Monster m) { ... }
}
public final class Monster {
private final Species type;
private int xp;
public Monster(Species type) { this.type = type; xp = type.xp(); }
public int movementSpeed() { return type.movementSpeed(); }
public void attack(Monster m) { type.attack(m); }
}
public static void main(String[] args) {
final Species RAT = new Species(10, 10, 4);
final Species GNOLL = new Species(...);
Monster harald = new Monster(RAT);
Monster eve = new Monster(GNOLL);
}
Statt des Enums nimmt man eine "echte" Klasse mit Methoden für die Type-Objects.
Davon legt man zur Laufzeit Objekte an (das sind dann die möglichen Monster-Typen)
und bestückt damit die zu erzeugenden Monster.
Im Monster selbst rufen die Monster-Methoden dann einfach nur die Methoden des Type-Objects
auf (Delegation => Strategie-Pattern). Man
kann aber auch Attribute im Monster selbst pflegen und durch das Type-Object nur passend
initialisieren.
Vorteil: Änderungen erfolgen bei der Parametrisierung der Objekte (an einer Stelle im
Code, vermutlich main() oder beispielsweise durch Einlesen einer Konfig-Datei).
Fabrikmethode für die Type-Objects
public final class Species {
...
public Monster newMonster() {
return new Monster(this);
}
}
public static void main(String[] args) {
final Species RAT = new Species(10, 10, 4);
final Species GNOLL = new Species(...);
Monster harald = RAT.newMonster();
Monster eve = GNOLL.newMonster();
}
Das Hantieren mit den Type-Objects und den Monstern ist nicht so schön. Deshalb kann
man in der Klasse für die Type-Objects noch eine Fabrikmethode (=>
Factory-Method-Pattern) mit
einbauen, über die dann die Monster erzeugt werden.
Vererbung unter den Type-Objects
public final class Species {
...
public Species(int attackDamage, int movementSpeed, int xp) {
this.attackDamage = attackDamage; this.movementSpeed = movementSpeed; this.xp = xp;
}
public Species(Species parent, int attackDamage) {
this.attackDamage = attackDamage;
movementSpeed = parent.movementSpeed; xp = parent.xp;
}
}
public static void main(String[] args) {
final Species RAT = new Species(10, 10, 4);
final Species BOSS_RAT = new Species(RAT, 100);
final Species GNOLL = new Species(...);
Monster harald = RAT.newMonster();
Monster eve = GNOLL.newMonster();
}
Es wäre hilfreich, wenn die Type-Objects Eigenschaften untereinander teilen/weitergeben
könnten. Damit man aber jetzt nicht hier eine tiefe Vererbungshierarchie aufbaut und
damit wieder am Anfang des Problems wäre, baut man die Vererbung quasi selbst ein über
eine Referenz auf ein Eltern-Type-Object. Damit kann man zur Laufzeit einem Type-Object
sagen, dass es bestimmte Eigenschaften von einem anderen Type-Object übernehmen soll.
Im Beispiel werden die Eigenschaften movementSpeed und xp "vererbt" und entsprechend
aus dem Eltern-Type-Object übernommen (sofern dieses übergeben wird).
Erzeugen der Type-Objects dynamisch über eine Konfiguration
{
"Rat": {
"attackDamage": 10,
"movementSpeed": 10,
"xp": 4
},
"BossRat": {
"parent": "Rat",
"attackDamage": 100
},
"Gnoll": {
"attackDamage": ...,
"movementSpeed": ...,
"xp": ...
}
}
Jetzt kann man die Konfiguration der Type-Objects in einer Konfig-Datei ablegen und einfach
an einer passenden Stelle im Programm einlesen. Dort werden dann damit die Type-Objects
angelegt und mit Hilfe dieser dann die passend konfigurierten Monster (und deren Unterarten)
erzeugt.
Vor- und Nachteile des Type-Object-Pattern
Vorteil
Es gibt nur noch wenige Klassen auf Code-Ebene (im Beispiel: 2), und man kann über die
Konfiguration beliebig viele Monster-Typen erzeugen.
Nachteil
Es werden zunächst nur Daten "überschrieben", d.h. man kann nur für die einzelnen Typen
spezifische Werte mitgeben/definieren.
Bei Vererbung kann man in den Unterklassen nahezu beliebig das Verhalten durch einfaches
Überschreiben der Methoden ändern. Das könnte man in diesem Entwurfsmuster erreichen, in
dem man beispielsweise eine Reihe von vordefinierten Verhaltensarten implementiert, die
dann anhand von Werten ausgewählt und anhand anderer Werte weiter parametrisiert werden.
Verwandtschaft zum Flyweight-Pattern
Das Type-Object-Pattern ist keines
der "klassischen" Design-Pattern der "Gang
of Four" [Gamma2011]. Dennoch ist es gerade in der Spiele-Entwicklung häufig anzutreffen.
Das Type-Object-Pattern ist sehr ähnlich zum Flyweight-Pattern.
In beiden Pattern teilen sich mehrere Objekte gemeinsame Daten, die über Referenzen auf
gemeinsame Hilfsobjekte eingebunden werden. Die Zielrichtung unterscheidet sich aber deutlich:
- Beim Flyweight-Pattern ist das Ziel vor allem die Erhöhung der Speichereffizienz, und die
dort geteilten Daten müssen nicht unbedingt den "Typ" des nutzenden Objekts definieren.
- Beim Type-Objekt-Pattern ist das Ziel die Flexibilität auf Code-Ebene, indem man die Anzahl
der Klassen minimiert und die Typen in ein eigenes Objekt-Modell verschiebt. Das Teilen von
Speicher ist hier nur ein Nebeneffekt.
Wrap-Up
Type-Object-Pattern: Implementierung eines eigenen Objekt-Modells
-
Ziel: Minimierung der Anzahl der Klassen
-
Ziel: Erhöhung der Flexibilität
-
Schiebe "Typen" in ein eigenes Objekt-Modell
-
Type-Objects lassen sich dynamisch über eine Konfiguration anlegen
-
Objekte erhalten eine Referenz auf "ihr" Type-Object
-
"Vererbung" unter den Type-Objects möglich
Challenges
Betrachten Sie das folgende IMonster-Interface:
public interface IMonster {
String getVariety();
int getXp();
int getMagic();
String makeNoise();
}
Leiten Sie von diesem Interface eine Klasse Monster ab. Nutzen Sie das Type-Object-Pattern
und erzeugen Sie verschiedene "Klassen" von Monstern, die sich in den Eigenschaften variety,
xp und magic unterscheiden und in der Methode makeNoise() entsprechend unterschiedlich
verhalten. Die Eigenschaft xp wird dabei von jedem Monster während seiner Lebensdauer selbst
verwaltet, die anderen Eigenschaften bleiben während der Lebensdauer eines Monsters konstant
(ebenso wie die Methode makeNoise()).
- Was wird Bestandteil des Type-Objects? Begründen Sie Ihre Antwort.
- Implementieren Sie das Type-Object und integrieren Sie es in die Klasse
Monster.
- Implementieren Sie eine Factory-Methode in der Klasse für die Type-Objects, um ein neues
Monster mit diesem Type-Objekt erzeugen zu können.
- Implementieren Sie einen "Vererbungs"-Mechanismus für die Type-Objects (nicht Vererbung
im Java-/OO-Sinn!). Dabei soll eine Eigenschaft überschrieben werden können.
- Erzeugen Sie einige Monstertypen und jeweils einige Monster und lassen Sie diese ein
Geräusch machen (
makeNoise()).
- Ersetzen Sie das Type-Object durch ein selbst definiertes (komplexes) Enum.
Flyweight-Pattern
TL;DR
Das Flyweight-Pattern dient der Steigerung der (Speicher-) Effizienz, indem gemeinsame
Daten durch gemeinsam genutzte Objekte repräsentiert werden.
Den sogenannten Intrinsic State, also die Eigenschaften, die sich alle Objekte teilen,
werden in gemeinsam genutzte Objekte ausgelagert, und diese werden in den ursprünglichen
Klassen bzw. Objekten nur referenziert. So werden diese Eigenschaften nur einmal in den
Speicher geladen.
Den sogenannten Extrinsic State, also alle individuellen Eigenschaften, werden
entsprechend individuell je Objekt modelliert/eingestellt.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Unterscheiden von Intrinsic State und Extrinsic State
- (K2) Verschieben des Intrinsic States in gemeinsam genutzte Objekte
- (K2) Erklären der Ähnlichkeit zum Type-Object-Pattern
- (K3) Praktischer Einsatz des Flyweight-Patterns
Motivation: Modellierung eines Levels
Variante I: Einsatz eines Enums für die Felder
public enum Tile { WATER, FLOOR, WALL, ... }
public class Level {
private Tile[][] tiles;
public Level() {
tiles[0][0] = Tile.WALL; tiles[1][0] = Tile.WALL; tiles[2][0] = Tile.WALL; ...
tiles[0][1] = Tile.WALL; tiles[1][1] = Tile.FLOOR; tiles[2][1] = Tile.FLOOR; ...
tiles[0][2] = Tile.WALL; tiles[1][2] = Tile.WATER; tiles[2][2] = Tile.FLOOR; ...
...
}
public boolean isAccessible(int x, int y) {
switch (tiles[x][y]) {
case: WATER: return false;
case: FLOOR: return true;
...
}
}
...
}
Ein Level kann als Array mit Feldern modelliert werden. Die Felder selbst könnten mit
Hilfe eines Enums repräsentiert werden.
Allerdings muss dann bei jedem Zugriff auf ein Feld und dessen Eigenschaften eine
entsprechende switch/case-Fallunterscheidung eingebaut werden. Damit verstreut man
die Eigenschaften über die gesamte Klasse, und bei jeder Änderung am Enum für die Tiles
müssen alle switch/case-Blöcke entsprechend angepasst werden.
Variante II: Einsatz einer Klasse/Klassenhierarchie für die Felder
public abstract class Tile {
protected boolean isAccessible;
protected Texture texture;
public boolean isAccessible() { return isAccessible; }
}
public class Floor extends Tile {
public Floor() { isAccessible = true; texture = Texture.loadTexture("path/to/floor.png"); }
}
...
public class Level {
private final Tile[][] tiles;
public Level() {
tiles[0][0] = new Wall(); tiles[1][0] = new Wall(); tiles[2][0] = new Wall(); ...
tiles[0][1] = new Wall(); tiles[1][1] = new Floor(); tiles[2][1] = new Floor(); ...
tiles[0][2] = new Wall(); tiles[1][2] = new Water(); tiles[2][2] = new Floor(); ...
...
}
public boolean isAccessible(int x, int y) { return tiles[x][y].isAccessible(); }
}
Hier werden die Felder über eine Klassenhierarchie mit gemeinsamer Basisklasse modelliert.
Allerdings wird hier die Klassenhierarchie unter Umständen sehr schnell sehr umfangreich.
Außerdem werden Eigenschaften wie Texturen beim Anlegen der Tile-Objekte immer wieder neu
geladen und entsprechend mehrfach im Speicher gehalten (großer Speicherbedarf).
Flyweight: Nutze gemeinsame Eigenschaften gemeinsam
Idee: Eigenschaften, die nicht an einem konkreten Objekt hängen, werden in gemeinsam genutzte
Objekte ausgelagert (Shared Objects/Memory).
Ziel: Erhöhung der Speichereffizienz (geringerer Bedarf an Hauptspeicher, geringere Bandbreite
bei der Übertragung der Daten/Objekt an die GPU, ...).
Lösungsvorschlag I
public final class Tile {
private final boolean isAccessible;
private final Texture texture;
public boolean isAccessible() { return isAccessible; }
}
public class Level {
private static final Tile FLOOR = new Tile(true, Texture.loadTexture("path/to/floor.png"));
private static final Tile WALL = new Tile(false, Texture.loadTexture("path/to/wall.png"));
private static final Tile WATER = new Tile(false, Texture.loadTexture("path/to/water.png"));
private final Tile[][] tiles;
public Level() {
tiles[0][0] = WALL; tiles[1][0] = WALL; tiles[2][0] = WALL; ...
tiles[0][1] = WALL; tiles[1][1] = FLOOR; tiles[2][1] = FLOOR; ...
tiles[0][2] = WALL; tiles[1][2] = WATER; tiles[2][2] = FLOOR; ...
...
}
public boolean isAccessible(int x, int y) { return tiles[x][y].isAccessible(); }
}
Man legt die verschiedenen Tiles nur je einmal an und nutzt dann Referenzen auf diese Objekte.
Dadurch werden die speicherintensiven Elemente wie Texturen o.ä. nur je einmal geladen und im
Speicher vorgehalten.
Bei dieser Modellierung können die einzelnen Felder aber keine individuellen Eigenschaften haben,
wie etwa, ob ein Feld bereits durch den Helden untersucht/betreten wurde o.ä. ...
Lösungsvorschlag II
public final class TileModel {
private final boolean isAccessible;
private final Texture texture;
public boolean isAccessible() { return isAccessible; }
}
public final class Tile {
private boolean wasEntered;
private final TileModel model;
public boolean isAccessible() { return model.isAccessible(); }
public boolean wasEntered() { return wasEntered; }
}
public class Level {
private static final TileModel FLOOR = new TileModel(true, Texture.loadTexture("path/to/floor.png"));
...
private final Tile[][] tiles;
public Level() {
tiles[0][0] = new Tile(WALL); tiles[1][0] = new Tile(WALL); tiles[2][0] = new Tile(WALL); ...
tiles[0][1] = new Tile(WALL); tiles[1][1] = new Tile(FLOOR); tiles[2][1] = new Tile(FLOOR); ...
tiles[0][2] = new Tile(WALL); tiles[1][2] = new Tile(WATER); tiles[2][2] = new Tile(FLOOR); ...
...
}
public boolean isAccessible(int x, int y) { return tiles[x][y].isAccessible(); }
}
In dieser Variante werden die Eigenschaften eines Tile in Eigenschaften aufgeteilt, die von den
Tiles geteilt werden können (im Beispiel Textur und Betretbarkeit) und in Eigenschaften, die je
Feld individuell modelliert werden müssen (im Beispiel: wurde das Feld bereits betreten?).
Entsprechend könnte man für das Level-Beispiel ein TileModel anlegen, welches die gemeinsamen
Eigenschaften verwaltet. Man erzeugt dann im Level die nötigen Modelle je genau einmal und nutzt
sie, um damit dann die konkreten Felder zu erzeugen und im Level-Array zu referenzieren. Damit
werden Tile-Modelle von Tiles der gleichen "Klasse" gemeinsam genutzt und die Texturen u.ä. nur
je einmal im Speicher repräsentiert.
Flyweight-Pattern: Begriffe
-
Intrinsic State: invariant, Kontext-unabhängig, gemeinsam nutzbar
=> auslagern in gemeinsame Objekte
-
Extrinsic State: variant, Kontext-abhängig und kann nicht geteilt werden
=> individuell modellieren
Flyweight-Pattern: Klassische Modellierung

Im klassischen Flyweight-Pattern der "Gang of Four" [Gamma2011] wird ein gemeinsames Interface
erstellt, von dem die einzelnen Fliegengewicht-Klassen ableiten. Der Nutzer kennt nur dieses
Interface und nicht direkt die implementierenden Klassen.
Das Interface wird von zwei Arten von Klassen implementiert: Klassen, die nur intrinsischen
Zustand modellieren, und Klassen, die extrinsischen Zustand modellieren.
Für die Klassen, die den intrinsischen Zustand modellieren, werden die Objekte gemeinsam genutzt
(nicht im Diagramm darstellbar) und deshalb eine Factory davor geschaltet, die die Objekte der
entsprechenden Fliegengewicht-Klassen erzeugt und dabei darauf achtet, dass diese Objekte nur
einmal angelegt und bei erneuter Anfrage einfach nur wieder zurückgeliefert werden.
Zusätzlich gibt es Klassen, die extrinsischen Zustand modellieren und deshalb nicht unter den
Nutzern geteilt werden können und deren Objekte bei jeder Anfrage neu erstellt werden. Aber
auch diese werden von der Factory erzeugt/verwaltet.
Kombination mit dem Composite-Pattern
In der Praxis kann man das Pattern so direkt meist nicht einsetzen, sondern verbindet es mit
dem Composite-Pattern:

Ein Element kann eine einfache Komponente sein (im obigen Beispiel war das die Klasse TileModel)
oder eine zusammengesetzte Komponente, die ihrerseits andere Komponenten speichert (im obigen
Beispiel war das die Klasse Tile, die ein Objekt vom Typ TileModel referenziert - allerdings
fehlt im obigen Beispiel das gemeinsame Interface ...).
Level-Beispiel mit Flyweight (vollständig) und Composite
Im obigen Beispiel wurde zum Flyweight-Pattern noch das Composite-Pattern hinzugenommen, aber
es wurde aus Gründen der Übersichtlichkeit auf ein gemeinsames Interface und auf die Factory
verzichtet. Wenn man es anpassen würde, dann würde das Beispiel ungefähr so aussehen:
public interface ITile {
public boolean isAccessible();
}
public final class TileModel implements ITile {
private final boolean isAccessible;
private final Texture texture;
public boolean isAccessible() { return isAccessible; }
}
public final class Tile implements ITile {
private boolean wasEntered;
private final TileModel model;
public boolean isAccessible() { return model.isAccessible(); }
public boolean wasEntered() { return wasEntered; }
}
public final class TileFactory {
private static final TileModel FLOOR = new TileModel(true, Texture.loadTexture("path/to/floor.png"));
...
public static final ITile getTile(String tile) {
switch (tile) {
case "WALL": return new Tile(WALL);
case "FLOOR": return new Tile(FLOOR);
case "WATER": return new Tile(WATER);
...
}
}
}
public class Level {
private ITile[][] tiles;
public Level() {
tiles[0][0] = TileFactory.getTile("WALL");
tiles[1][0] = TileFactory.getTile("WALL");
tiles[2][0] = TileFactory.getTile("WALL");
...
tiles[0][1] = TileFactory.getTile("WALL");
tiles[1][1] = TileFactory.getTile("FLOOR");
tiles[2][1] = TileFactory.getTile("FLOOR");
...
tiles[0][2] = TileFactory.getTile("WALL");
tiles[1][2] = TileFactory.getTile("WATER");
tiles[2][2] = TileFactory.getTile("FLOOR");
...
...
}
public boolean isAccessible(int x, int y) { return tiles[x][y].isAccessible(); }
}
Verwandtschaft zum Type-Object-Pattern
Das Flyweight-Pattern ist sehr ähnlich zum
Type-Object-Pattern. In beiden Pattern teilen
sich mehrere Objekte gemeinsame Daten, die über Referenzen auf gemeinsame Hilfsobjekte eingebunden
werden. Die Zielrichtung unterscheidet sich aber deutlich:
- Beim Flyweight-Pattern ist das Ziel vor allem die Erhöhung der Speichereffizienz, und die
dort geteilten Daten müssen nicht unbedingt den "Typ" des nutzenden Objekts definieren.
- Beim Type-Objekt-Pattern ist das Ziel die Flexibilität auf Code-Ebene, indem man die Anzahl
der Klassen minimiert und die Typen in ein eigenes Objekt-Modell verschiebt. Das Teilen von
Speicher ist hier nur ein Nebeneffekt.
Wrap-Up
Flyweight-Pattern: Steigerung der (Speicher-) Effizienz durch gemeinsame Nutzung von Objekten
- Lagere Intrinsic State in gemeinsam genutzte Objekte aus
- Modelliere Extrinsic State individuell
Challenges
In den Vorgaben
finden Sie ein Modellierung eines Schachspiels.
Identifizieren Sie die Stellen im Vorgabe-Code, wo Sie das Flyweight-Pattern
sinnvoll anwenden können und bauen Sie dieses Pattern über ein Refactoring ein.
Begründen Sie, wie Sie das Pattern eingesetzt haben und warum Sie welche Elemente
immutable oder mutable deklariert haben.
Wieso eignet sich das Flyweight-Pattern besonders im Bereich von Computerspielen?
Geben Sie mögliche Vor- und Nachteile an und begründen Sie Ihre Antwort.
Subsections of Testen mit JUnit und Mockito
Einführung Softwaretest
TL;DR
Fehler schleichen sich durch Zeitdruck und hohe Komplexität schnell in ein Softwareprodukt ein. Die
Folgen können von "ärgerlich" über "teuer" bis hin zu (potentiell) "tödlich" reichen. Richtiges
Testen ist also ein wichtiger Aspekt bei der Softwareentwicklung!
JUnit ist ein Java-Framework, mit dem Unit-Tests (aber auch andere Teststufen) implementiert werden
können. In JUnit 4 und 5 zeichnet man eine Testmethode mit Hilfe der Annotation @Test an der
entsprechenden Methode aus. Dadurch kann man Produktiv- und Test-Code prinzipiell mischen; Best
Practice ist aber das Anlegen eines weiteren Ordners test/ und das Spiegeln der Package-Strukturen.
Für die zu testende Klasse wird eine korrespondierende Testklasse mit dem Suffix "Test" (Konvention)
angelegt und dort die Testmethoden implementiert. Der IDE muss der neue test/-Ordner noch als
Ordner für Sourcen bzw. Tests bekannt gemacht werden. In den Testmethoden baut man den Test auf,
führt schließlich den Testschritt durch (beispielsweise konkreter Aufruf der zu testenden Methode)
und prüft anschließend mit einem assert*(), ob das erzielte Ergebnis dem erwarteten Ergebnis
entspricht. Ist alles OK, ist der Test "grün", sonst "rot".
Da ein fehlschlagendes assert*() den Test abbricht, werden eventuell danach folgende Prüfungen
nicht mehr durchgeführt und damit ggf. weitere Fehler maskiert. Deshalb ist es gute Praxis, in
einer Testmethode nur einen Testfall zu implementieren und i.d.R. auch nur ein (oder wenige) Aufrufe
von assert*() pro Testmethode zu haben.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Ursachen von Softwarefehlern
- (K3) Aufbauen von Tests mit JUnit 4 und 5 unter Nutzung der Annotation
@Test
Software-Fehler und ihre Folgen

(Einige) Ursachen für Fehler
- Zeit- und Kostendruck
- Mangelhafte Anforderungsanalyse
- Hohe Komplexität
- Mangelhafte Kommunikation
- Keine/schlechte Teststrategie
- Mangelhafte Beherrschung der Technologie
- ...
Irgendjemand muss mit Deinen Bugs leben!
Leider gibt es im Allgemeinen keinen Weg zu zeigen, dass eine Software korrekt ist.
Man kann (neben formalen Beweisansätzen) eine Software nur unter möglichst vielen
Bedingungen ausprobieren, um zu schauen, wie sie sich verhält, und um die dabei zu
Tage tretenden Bugs zu fixen.
Mal abgesehen von der verbesserten User-Experience führt weniger fehlerbehaftete
Software auch dazu, dass man seltener mitten in der Nacht geweckt wird, weil irgendwo
wieder ein Server gecrasht ist ... Weniger fehlerbehaftete Software ist auch leichter
zu ändern und zu pflegen! In realen Projekten macht Maintenance den größten Teil an der
Softwareentwicklung aus ... Während Ihre Praktikumsprojekte vermutlich nach der Abgabe
nie wieder angeschaut werden, können echte Projekte viele Jahre bis Jahrzehnte leben!
D.h. irgendwer muss sich dann mit Ihren Bugs herumärgern - vermutlich sogar Sie selbst ;)
Always code as if the guy who ends up maintaining your code will be a
violent psychopath who knows where you live. Code for readability.
-- John F. Woods
Dieses Zitat taucht immer mal wieder auf, beispielsweise auf der OSCON 2014 ...
Es scheint aber tatsächlich, dass John F. Woods
die ursprüngliche Quelle war (vgl. Stackoverflow: 876089).
Da wir nur wenig Zeit haben und zudem vergesslich sind und obendrein die Komplexität
eines Projekts mit der Anzahl der Code-Zeilen i.d.R. nicht-linear ansteigt, müssen wir
das Testen automatisieren. Und hier kommt JUnit ins Spiel :)
Was wann testen? Wichtigste Teststufen
-
Modultest
- Testen einer Klasse und ihrer Methoden
- Test auf gewünschtes Verhalten (Parameter, Schleifen, ...)
-
Integrationstest
- Test des korrekten Zusammenspiels mehrerer Komponenten
- Konzentration auf Schnittstellentests
-
Systemtest
- Test des kompletten Systems unter produktiven Bedingungen
- Orientiert sich an den aufgestellten Use Cases
- Funktionale und nichtfunktionale Anforderungen testen
=> Verweis auf Wahlfach "Softwarequalität"
JUnit: Test-Framework für Java
JUnit --- Open Source Java Test-Framework zur Erstellung und
Durchführung wiederholbarer Tests
-
JUnit 3
- Tests müssen in eigenen Testklassen stehen
- Testklassen müssen von Klasse
TestCase erben
- Testmethoden müssen mit dem Präfix "
test" beginnen
-
JUnit 4
- Annotation
@Test für Testmethoden
- Kein Zwang zu spezialisierten Testklassen (insbesondere kein Zwang mehr zur Ableitung von
TestCase)
- Freie Namenswahl für Testmethoden (benötigen nicht mehr Präfix "
test")
Damit können prinzipiell auch direkt im Source-Code Methoden als
JUnit-Testmethoden ausgezeichnet werden ... (das empfiehlt sich in der
Regel aber nicht)
-
JUnit 5 = JUnit Platform + JUnit Jupiter + JUnit Vintage
- Erweiterung um mächtigere Annotationen
- Aufteilung in spezialisierte Teilprojekte
Das Teilprojekt "JUnit Platform" ist die Grundlage für das JUnit-Framework. Es bietet
u.a. einen Console-Launcher, um Testsuiten manuell in der Konsole zu starten oder über
Builder wie Ant oder Gradle.
Das Teilprojekt "JUnit Jupiter" ist das neue Programmiermodell zum Schreiben von Tests
in JUnit 5. Es beinhaltet eine TestEngine zum Ausführen der in Jupiter geschriebenen
Tests.
Das Teilprojekt "JUnit Vintage" beinhaltet eine TestEngine zum Ausführen von Tests,
die in JUnit 3 oder JUnit 4 geschrieben sind.
Anmerkung: Wie der Name schon sagt, ist das Framework für Modultests
("Unit-Tests") gedacht. Man kann damit aber auch auf anderen Teststufen
arbeiten!
Anmerkung: Im Folgenden besprechen wir JUnit am Beispiel JUnit 4, da diese Version
des Frameworks besonders stark verbreitet ist und JUnit 5 (trotz offiziellem Release) immer
noch stellenweise unfertig wirkt. Auf Unterschiede zu JUnit 5 wird an geeigneter Stelle
hingewiesen (abgesehen von Import-Statements). Mit JUnit 3 sollte nicht mehr aktiv
gearbeitet werden, d.h. insbesondere keine neuen Tests mehr erstellt werden, da diese
Version nicht mehr weiterentwickelt wird.
Anlegen und Organisation der Tests mit JUnit
-
Anlegen neuer Tests: Klasse auswählen, Kontextmenü New > JUnit Test Case
-
Best Practice: Spiegeln der Paket-Hierarchie
- Toplevel-Ordner
test (statt src)
- Package-Strukturen spiegeln
- Testklassen mit Suffix "
Test"
Vorteile dieses Vorgehens:
- Die Testklassen sind aus Java-Sicht im selben Package wie die Source-Klassen,
d.h. Zugriff auf Package-sichtbare Methoden etc. ist gewährleistet
- Durch die Spiegelung der Packages in einem separaten Testordner erhält man
eine gute getrennte Übersicht über jeweils die Tests und die Sourcen
- Die Wiederverwendung des Klassennamens mit dem Anhang "Test" erlaubt die
schnelle Erkennung, welche Tests hier vorliegen
In der Paketansicht liegen dann die Source- und die Testklassen immer direkt
hintereinander (da sie im selben Paket sind und mit dem selben Namen anfangen)
=> besserer Überblick!
Anmerkung: Die (richtige) JUnit-Bibliothek muss im Classpath liegen!
Eclipse bringt für JUnit 4 und JUnit 5 die nötigen Jar-Dateien mit und fragt beim
erstmaligen Anlegen einer neuen Testklasse, ob die für die ausgewählte Version
passenden JUnit-Jars zum Build-Path hinzugefügt werden sollen.
IntelliJ bringt ebenfalls eine JUnit 4 Bibliothek mit, die zum Projekt als Abhängigkeit
hinzugefügt werden muss. Für JUnit 5 bietet IntelliJ an, die Jar-Dateien herunterzuladen
und in einem passenden Ordner abzulegen.
Alternativ lädt man die Bibliotheken entsprechend der Anleitung unter junit.org
herunter und bindet sie in das Projekt ein.
JUnit 4+5: Definition von Tests
Annotation @Test vor Testmethode schreiben
import org.junit.Test;
import static org.junit.Assert.*;
public class FactoryBeispielTest4 {
@Test
public void testGetTicket() {
fail("not implemented");
}
}
Für JUnit 5 muss statt org.junit.Test entsprechend org.junit.jupiter.api.Test importiert werden.
Während in JUnit 4 die Testmethoden mit der Sichtbarkeit public versehen sein müssen und keine
Parameter haben (dürfen), spielt die Sichtbarkeit in JUnit 5 keine Rolle (und die Testmethoden dürfen Parameter
aufweisen => vgl. Abschnitt "Dependency Injection for Constructors and Methods" in der JUnit-Doku).
JUnit 4: Ergebnis prüfen
Klasse org.junit.Assert enthält diverse statische Methoden zum Prüfen:
// Argument muss true bzw. false sein
void assertTrue(boolean);
void assertFalse(boolean);
// Gleichheit im Sinne von equals()
void assertEquals(Object, Object);
// Test sofort fehlschlagen lassen
void fail();
...
Für JUnit 5 finden sich die Assert-Methoden im Package org.junit.jupiter.api.Assertions.
Anmerkung zum statischen Import
Bei normalem Import der Klasse Assert muss man jeweils den voll qualifizierten Namen
einer statischen Methode nutzen: Assert.fail().
Alternative statischer Import: import static org.junit.Assert.fail;
=> Statische Member der importierten Klasse (oder Interface)
werden über ihre unqualifizierten Namen zugreifbar.
Achtung: Namenskollisionen möglich!
// nur bestimmtes Member importieren
import static packageName.className.staticMemberName;
// alle statischen Member importieren
import static packageName.className.*;
Mögliche Testausgänge bei JUnit
-
Error: Fehler im Programm (Test)
- Unbehandelte Exception
- Abbruch (Timeout)
-
Failure: Testausgang negativ
- Assert fehlgeschlagen
Assert.fail() aufgerufen
-
OK
Anmerkungen zu Assert
- Pro Testmethode möglichst nur ein Assert verwenden!
- Anderenfalls: Schlägt ein Assert fehl, wird der Rest nicht mehr überprüft ...
Wrap-Up
-
Testen ist genauso wichtig wie Coden
-
Richtiges Testen spart Geld, Zeit, ...
-
Tests auf verschiedenen Abstraktionsstufen
-
JUnit als Framework für (Unit-) Tests; hier JUnit 4 (mit Ausblick auf JUnit 5)
- Testmethoden mit Annotation
@Test
- Testergebnis mit
assert* prüfen
Quellen
- [fernunihagenJunit] Einführung in JUnit
Thies, A. und Noelke, C. und Ungerc, Fernuniversität in Hagen. - [junit4] JUnit 5
The JUnit Team, 2022. - [Kleuker2019] Qualitätssicherung durch Softwaretests
Kleuker, S., Springer Vieweg, 2019. ISBN 978-3-658-24886-4. DOI 10.1007/978-3-658-24886-4. - [Osherove2014] The Art of Unit Testing
Osherove, R., Manning, 2014. ISBN 978-1-6172-9089-3. - [Spillner2012] Basiswissen Softwaretest
Spillner, A. und Linz, T., dpunkt, 2012. ISBN 978-3-86490-024-2. - [vogellaJUnit] JUnit 5 tutorial - Learn how to write unit tests
vogella GmbH, 2021.
Testen mit JUnit (JUnit-Basics)
TL;DR
In JUnit 4 und 5 werden Testmethoden mit Hilfe der Annotation @Test ausgezeichnet. Über die
verschiedenen assert*()-Methoden kann das Testergebnis mit dem erwarteten Ergebnis verglichen
werden und entsprechend ist der Test "grün" oder "rot". Mit den verschiedenen assume*()-Methoden
kann dagegen geprüft werden, ob eventuelle Vorbedingungen für das Ausführen eines Testfalls
erfüllt sind - anderenfalls wird der Testfall dann übersprungen.
Mit Hilfe von @Before und @After können Methoden gekennzeichnet werden, die jeweils vor jeder
Testmethode und nach jeder Testmethode aufgerufen werden. Damit kann man seine Testumgebung auf-
und auch wieder abbauen (JUnit 4).
Erwartete Exceptions lassen sich in JUnit 4 mit einem Parameter expected in der Annotation @Test
automatisch prüfen: @Test(expected=package.Exception.class). In JUnit 4 besteht die Möglichkeit,
Testklassen zu Testsuiten zusammenzufassen und gemeinsam laufen zu lassen.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Steuern von Tests (ignorieren, zeitliche Begrenzung)
- (K3) Prüfung von Exceptions
- (K3) Aufbau von Testsuiten mit JUnit
JUnit: Ergebnis prüfen
Klasse org.junit.Assert enthält diverse statische Methoden zum Prüfen:
// Argument muss true bzw. false sein
void assertTrue(boolean);
void assertFalse(boolean);
// Gleichheit im Sinne von equals()
void assertEquals(Object, Object);
// Test sofort fehlschlagen lassen
void fail();
...
To "assert" or to "assume"?
Setup und Teardown: Testübergreifende Konfiguration
private Studi x;
@Before
public void setUp() { x = new Studi(); }
@Test
public void testToString() {
// Studi x = new Studi();
assertEquals(x.toString(), "Heinz (15cps)");
}
@Before- wird vor jeder Testmethode aufgerufen
@BeforeClass- wird einmalig vor allen Tests aufgerufen (
static!)
@After- wird nach jeder Testmethode aufgerufen
@AfterClass- wird einmalig nach allen Tests aufgerufen (
static!)
In JUnit 5 wurden die Namen dieser Annotationen leicht geändert:
| JUnit 4 |
JUnit 5 |
@Before |
@BeforeEach |
@After |
@AfterEach |
@BeforeClass |
@BeforeAll |
@AfterClass |
@AfterAll |
Beispiel für den Einsatz von @Before
Annahme: alle/viele Testmethoden brauchen neues Objekt x vom Typ Studi
private Studi x;
@Before
public void setUp() {
x = new Studi("Heinz", 15);
}
@Test
public void testToString() {
// Studi x = new Studi("Heinz", 15);
assertEquals(x.toString(), "Name: Heinz, credits: 15");
}
@Test
public void testGetName() {
// Studi x = new Studi("Heinz", 15);
assertEquals(x.getName(), "Heinz");
}
Ignorieren von Tests
- Hinzufügen der Annotation
@Ignore
- Alternativ mit Kommentar:
@Ignore("Erst im nächsten Release")
@Ignore("Warum ignoriert")
@Test
public void testBsp() {
Bsp x = new Bsp();
assertTrue(x.isTrue());
}
In JUnit 5 wird statt der Annotation @Ignore die Annotation @Disabled mit
der selben Bedeutung verwendet. Auch hier lässt sich als Parameter ein String
mit dem Grund für das Ignorieren des Tests hinterlegen.
Vermeidung von Endlosschleifen: Timeout
- Testfälle werden nacheinander ausgeführt
- Test mit Endlosschleife würde restliche Tests blockieren
- Erweitern der
@Test-Annotation mit Parameter "timeout":
=> @Test(timeout=2000) (Zeitangabe in Millisekunden)
@Test(timeout = 2000)
void testTestDauerlaeufer() {
while (true) { ; }
}
In JUnit 5 hat die Annotation @Test keinen timeout-Parameter mehr.
Als Alternative bietet sich der Einsatz von org.junit.jupiter.api.Assertions.assertTimeout
an. Dabei benötigt man allerdings Lambda-Ausdrücke (Verweis auf spätere VL):
@Test
void testTestDauerlaeufer() {
assertTimeout(ofMillis(2000), () -> {
while (true) { ; }
});
}
(Beispiel von oben mit Hilfe von JUnit 5 formuliert)
Test von Exceptions: Expected
Traditionelles Testen von Exceptions mit try und catch:
@Test
public void testExceptTradit() {
try {
int i = 0 / 0;
fail("keine ArithmeticException ausgeloest");
} catch (ArithmeticException aex) {
assertNotNull(aex.getMessage());
} catch (Exception e) {
fail("falsche Exception geworfen");
}
}
Der expected-Parameter für die @Test-Annotation in JUnit 4 macht
dies deutlich einfacher: @Test(expected = MyException.class)
=> Test scheitert, wenn diese Exception nicht geworfen wird
@Test(expected = java.lang.ArithmeticException.class)
public void testExceptAnnot() {
int i = 0 / 0;
}
In JUnit 5 hat die Annotation @Test keinen expected-Parameter mehr.
Als Alternative bietet sich der Einsatz von org.junit.jupiter.api.Assertions.assertThrows
an. Dabei benötigt man allerdings Lambda-Ausdrücke (Verweis auf spätere VL):
@Test
public void testExceptAnnot() {
assertThrows(java.lang.ArithmeticException.class, () -> {
int i = 0 / 0;
});
}
(Beispiel von oben mit Hilfe von JUnit 5 formuliert)
Parametrisierte Tests
Manchmal möchte man den selben Testfall mehrfach mit anderen Werten (Parametern)
durchführen.
class Sum {
public int sum(int i, int j) {
return i + j;
}
}
class SumTest {
@Test
public void testSum() {
Sum s = new Sum();
assertEquals(s.sum(1, 1), 2);
}
// und mit (2,2, 4), (2,2, 5), ...????
}
Prinzipiell könnte man dafür entweder in einem Testfall eine Schleife schreiben,
die über die verschiedenen Parameter iteriert. In der Schleife würde dann
jeweils der Aufruf der zu testenden Methode und das gewünschte Assert passieren.
Alternativ könnte man den Testfall entsprechend oft duplizieren mit jeweils den
gewünschten Werten.
Beide Vorgehensweisen haben Probleme: Im ersten Fall würde die Schleife bei
einem Fehler oder unerwarteten Ergebnis abbrechen, ohne dass die restlichen
Tests (Werte) noch durchgeführt würden. Im zweiten Fall bekommt man eine
unnötig große Anzahl an Testmethoden, die bis auf die jeweiligen Werte identisch
sind (Code-Duplizierung).
Parametrisierte Tests mit JUnit 4
JUnit 4 bietet für dieses Problem sogenannte "parametrisierte Tests" an. Dafür
muss eine Testklasse in JUnit 4 folgende Bedingungen erfüllen:
- Die Testklasse wird mit der Annotation
@RunWith(Parameterized.class)
ausgezeichnet.
- Es muss eine öffentliche statische Methode geben mit der Annotation
@Parameters. Diese Methode liefert eine Collection zurück, wobei jedes
Element dieser Collection ein Array mit den Parametern für einen
Durchlauf der Testmethoden ist.
- Die Parameter müssen gesetzt werden. Dafür gibt es zwei Varianten:
a) Für jeden Parameter gibt es ein öffentliches Attribut. Diese Attribute
müssen mit der Annotation
@Parameter markiert sein und können in den
Testmethoden normal genutzt werden. JUnit sorgt dafür, dass für jeden
Eintrag in der Collection aus der statischen @Parameters-Methode
diese Felder gesetzt werden und die Testmethoden aufgerufen werden.
b) Alternativ gibt es einen Konstruktor, der diese Werte setzt. Die Anzahl
der Parameter im Konstruktor muss dabei exakt der Anzahl (und
Reihenfolge) der Werte in jedem Array in der von der statischen
@Parameters-Methode gelieferten Collection entsprechen. Der
Konstruktor wird für jeden Parametersatz einmal aufgerufen und die
Testmethoden einmal durchgeführt.
Letztlich wird damit das Kreuzprodukt aus Testmethoden und Testdaten durchgeführt.
Parametrisierte Tests mit JUnit 5
In JUnit 5 werden parametrisierte Tests mit der Annotation @ParameterizedTest
gekennzeichnet (statt mit @Test).
Mit Hilfe von @ValueSource kann man ein einfaches Array von Werten (Strings
oder primitive Datentypen) angeben, mit denen der Test ausgeführt wird. Dazu
bekommt die Testmethode einen entsprechenden passenden Parameter:
@ParameterizedTest
@ValueSource(strings = {"wuppie", "fluppie", "foo"})
void testWuppie(String candidate) {
assertTrue(candidate.equals("wuppie"));
}
Alternativ lassen sich als Parameterquelle u.a. Aufzählungen (@EnumSource)
oder Methoden (@MethodSource) angeben.
Hinweis: Parametrisierte Tests werden in JUnit 5 derzeit noch als "experimentell"
angesehen!
Testsuiten: Tests gemeinsam ausführen (JUnit 4)
Eclipse: New > Other > Java > JUnit > JUnit Test Suite
import org.junit.runner.RunWith;
import org.junit.runners.Suite;
import org.junit.runners.Suite.SuiteClasses;
@RunWith(Suite.class)
@SuiteClasses({
// Hier kommen alle Testklassen rein
PersonTest.class,
StudiTest.class
})
public class MyTestSuite {
// bleibt leer!!!
}
Testsuiten mit JUnit 5
In JUnit 5 gibt es zwei Möglichkeiten, Testsuiten zu erstellen:
@SelectPackages: Angabe der Packages, die für die Testsuite zusammengefasst werden sollen@SelectClasses: Angabe der Klassen, die für die Testsuite zusammengefasst werden sollen
@RunWith(JUnitPlatform.class)
@SelectClasses({StudiTest5.class, WuppieTest5.class})
public class MyTestSuite5 {
// bleibt leer!!!
}
Zusätzlich kann man beispielsweise mit @IncludeTags oder @ExcludeTags Testmethoden mit bestimmten Tags
einbinden oder ausschließen. Beispiel: Schließe alle Tests mit Tag "develop" aus: @ExcludeTags("develop").
Dabei wird an den Testmethoden zusätzlich das Tag @Tag verwendet, etwas @Tag("develop").
Achtung: Laut der offiziellen Dokumentation
(Abschnitt "4.4.4. Test Suite")
gilt zumindest bei der Selection über @SelectPackages der Zwang zu einer Namenskonvention:
Es werden dabei nur Klassen gefunden, deren Name mit Test beginnt oder endet!
Weiterhin werden Testsuites mit der Annotation @RunWith(JUnitPlatform.class) nicht
auf der "JUnit 5"-Plattform ausgeführt, sondern mit der JUnit 4-Infrastuktur!
Wrap-Up
JUnit als Framework für (Unit-) Tests; hier JUnit 4 (mit Ausblick auf JUnit 5)
- Testmethoden mit Annotation
@Test
assert (Testergebnis) vs. assume (Testvorbedingung)- Aufbau der Testumgebung
@Before
- Abbau der Testumgebung
@After
- Steuern von Tests mit
@Ignore oder @Test(timout=XXX)
- Exceptions einfordern mit
@Test(expected=package.Exception.class)
- Tests zusammenfassen zu Testsuiten
Challenges
Schreiben Sie eine JUnit-Testklasse (JUnit 4.x oder 5.x) und testen Sie eine
ArrayList<String>. Prüfen Sie dabei, ob das Einfügen und Entfernen wie
erwartet funktioniert.
-
Initialisieren Sie in einer setUp()-Methode das Testobjekt und fügen
Sie zwei Elemente ein. Stellen Sie mit einer passenden assume*-Methode
sicher, dass die Liste genau diese beiden Elemente enthält.
Die setUp()-Methode soll vor jedem Testfall ausgeführt werden.
-
Setzen Sie in einer tearDown()-Methode das Testobjekt wieder auf null
und stellen Sie mit einer passenden assume*-Methode sicher, dass das
Testobjekt tatsächlich null ist.
Die tearDown()-Methode soll nach jedem Testfall ausgeführt werden.
-
Schreiben Sie eine Testmethode testAdd().
Fügen Sie ein weiteres Element zum Testobjekt hinzu und prüfen Sie mit
einer passenden assert*-Methode, ob die Liste nach dem Einfügen den
gewünschten Zustand hat: Die Länge der Liste muss 3 Elemente betragen
und alle Elemente müssen in der richtigen Reihenfolge in der Liste stehen.
-
Schreiben Sie eine Testmethode testRemoveObject().
Entfernen Sie ein vorhandenes Element (über die Referenz auf das Objekt)
aus dem Testobjekt und prüfen Sie mit einer passenden assert*-Methode,
ob die Liste nach dem Entfernen den gewünschten Zustand hat: Die Liste
darf nur noch das verbleibende Element enthalten.
-
Schreiben Sie eine Testmethode testRemoveIndex().
Entfernen Sie ein vorhandenes Element über dessen Index in der Liste
und prüfen Sie mit einer passenden assert*-Methode, ob die Liste nach
dem Entfernen den gewünschten Zustand hat: Die Liste darf nur noch das
verbleibende Element enthalten.
(Nutzen Sie zum Entfernen die remove(int)-Methode der Liste.)
-
Schreiben Sie zusätzlich einen parametrisierten JUnit-Test für die
folgende Klasse:
import java.util.ArrayList;
public class SpecialArrayList extends ArrayList<String> {
public void concatAddStrings(String a, String b) {
this.add(a + b);
}
}
Testen Sie, ob die Methode concatAddStrings der Klasse SpecialArrayList
die beiden übergebenen Strings korrekt konkateniert und das Ergebnis richtig
in die Liste einfügt. Testen Sie dabei mit mindestens den folgenden
Parameter-Tripeln:
| a |
b |
expected |
| "" |
"" |
"" |
| "" |
"a" |
"a" |
| "a" |
"" |
"a" |
| "abc" |
"123" |
"abc123" |
Quellen
- [fernunihagenJunit] Einführung in JUnit
Thies, A. und Noelke, C. und Ungerc, Fernuniversität in Hagen. - [junit4] JUnit 5
The JUnit Team, 2022. - [Kleuker2019] Qualitätssicherung durch Softwaretests
Kleuker, S., Springer Vieweg, 2019. ISBN 978-3-658-24886-4. DOI 10.1007/978-3-658-24886-4. - [Osherove2014] The Art of Unit Testing
Osherove, R., Manning, 2014. ISBN 978-1-6172-9089-3. - [Spillner2012] Basiswissen Softwaretest
Spillner, A. und Linz, T., dpunkt, 2012. ISBN 978-3-86490-024-2. - [vogellaJUnit] JUnit 5 tutorial - Learn how to write unit tests
vogella GmbH, 2021.
Testfallermittlung: Wie viel und was muss man testen?
TL;DR
Mit Hilfe der Äquivalenzklassenbildung kann man Testfälle bestimmen. Dabei wird der Eingabebereich
für jeden Parameter einer Methode in Bereiche mit gleichem Verhalten der Methode eingeteilt (die
sogenannten "Äquivalenzklassen"). Dabei können einige Äquivalenzklassen (ÄK) gültigen Eingabebereichen
entsprechen ("gültige ÄK"), also erlaubten/erwarteten Eingaben (die zum gewünschten Verhalten führen),
und die restlichen ÄK entsprechen dann ungültigen Eingabebereichen ("ungültige ÄK"), also nicht
erlaubten Eingaben, die von der Methode zurückgewiesen werden sollten. Jede dieser ÄK muss in mindestens
einem Testfall vorkommen, d.h. man bestimmt einen oder mehrere zufällige Werte in den ÄK. Dabei können
über mehrere Parameter hinweg verschiedene gültige ÄK in einem Testfall kombiniert werden. Bei den
ungültigen ÄK kann dagegen immer nur ein Parameter eine ungültige ÄK haben, für die restlichen Parameter
müssen gültige ÄK genutzt werden, und diese werden dabei als durch diesen Testfall "nicht getestet"
betrachtet.
Zusätzlich entstehen häufig Fehler bei den Grenzen der Bereiche, etwa in Schleifen. Deshalb führt
man zusätzlich noch eine Grenzwertanalyse durch und bestimmt für jede ÄK den unteren und den oberen
Grenzwert und erzeugt aus diesen Werten zusätzliche Testfälle.
Wenn in der getesteten Methode der Zustand des Objekts eine Rolle spielt, wird dieser wie ein weiterer
Eingabeparameter für die Methode betrachtet und entsprechend in die ÄK-Bildung bzw. GW-Analyse einbezogen.
Wenn ein Testfall sich aus den gültigen ÄK/GW speist, spricht man auch von einem "Positiv-Test"; wenn
ungültige ÄK/GW genutzt werden, spricht man auch von einem "Negativ-Test".
Videos (HSBI-Medienportal)
Lernziele
- (K2) Merkmale schlecht testbaren Codes erklären
- (K2) Merkmale guter Unit-Tests erklären
- (K3) Erstellen von Testfällen mittels Äquivalenzklassenbildung und Grenzwertanalyse
Hands-On (10 Minuten): Wieviel und was muss man testen?
public class Studi {
private int credits = 0;
public void addToCredits(int credits) {
if (credits < 0) {
throw new IllegalArgumentException("Negative Credits!");
}
if (this.credits + credits > 210) {
throw new IllegalArgumentException("Mehr als 210 Credits!");
}
this.credits += credits;
}
}
JEDE Methode mindestens testen mit/auf:
- Positive Tests: Gutfall (Normalfall) => "gültige ÄK/GW"
- Negativ-Tests (Fehlbedienung, ungültige Werte) => "ungültige ÄK/GW"
- Rand- bzw. Extremwerte => GW
- Exceptions
=> Anforderungen abgedeckt (Black-Box)?
=> Wichtige Pfade im Code abgedeckt (White-Box)?
Praxis
- Je kritischer eine Klasse/Methode/Artefakt ist, um so intensiver testen!
- Suche nach Kompromissen: Testkosten vs. Kosten von Folgefehlern;
beispielsweise kein Test generierter Methoden
=> "Erzeugen" der Testfälle über die Äquivalenzklassenbildung und
Grenzwertanalyse (siehe nächste Folien). Mehr dann später im Wahlfach "Softwarequalität" ...
Äquivalenzklassenbildung
Beispiel: Zu testende Methode mit Eingabewert x, der zw. 10 und 100 liegen soll

-
Zerlegung der Definitionsbereiche in Äquivalenzklassen (ÄK):
- Disjunkte Teilmengen, wobei
- Werte einer ÄK führen zu gleichartigem Verhalten
-
Annahme: Eingabeparameter sind untereinander unabhängig
-
Unterscheidung gültige und ungültige ÄK
Bemerkungen
Hintergrund: Da die Werte einer ÄK zu gleichartigem Verhalten führen, ist es
egal, welchen Wert man aus einer ÄK für den Test nimmt.
Formal hat man eine ungültige ÄK (d.h. die Menge aller ungültigen Werte). In
der Programmierpraxis macht es aber einen Unterschied, ob es sich um Werte
unterhalb oder oberhalb des erlaubten Wertebereichs handelt (Fallunterscheidung).
Beispiel: Eine Funktion soll Werte zwischen 10 und 100 verarbeiten. Dann sind
alle Werte kleiner 10 oder größer 100 mathematisch gesehen in der selben ÄK
"ungültig". Praktisch macht es aber Sinn, eine ungültige ÄK für "kleiner 10"
und eine weitere ungültige ÄK für "größer 100" zu betrachten ...
Traditionell betrachtet man nur die Eingabeparameter. Es kann aber Sinn machen,
auch die Ausgabeseite zu berücksichtigen (ist aber u.U. nur schwierig zu
realisieren).
Faustregeln bei der Bildung von ÄK
-
Falls eine Beschränkung einen Wertebereich spezifiziert:
Aufteilung in eine gültige und zwei ungültige ÄK
Beispiel: Eingabewert x soll zw. 10 und 100 liegen
- Gültige ÄK: $[10, 100]$
- Ungültige ÄKs: $x < 10$ und $100 < x$
-
Falls eine Beschränkung eine minimale und maximale Anzahl von Werten
spezifiziert:
Aufteilung in eine gültige und zwei ungültige ÄK
Beispiel: Jeder Studi muss pro Semester an mindestens einer LV teilnehmen,
maximal sind 5 LVs erlaubt.
- Gültige ÄK: $1 \le x \le 5$
- Ungültige ÄKs: $x = 0$ (keine Teilnahme) und $5 < x$ (mehr als 5 Kurse)
-
Falls eine Beschränkung eine Menge von Werten spezifiziert, die
möglicherweise unterschiedlich behandelt werden:
Für jeden Wert dieser Menge eine eigene gültige ÄK erstellen und zusätzlich
insgesamt eine ungültige ÄK
Beispiel: Das Hotel am Urlaubsort ermöglicht verschiedene Freizeitaktivitäten:
Segway-fahren, Tauchen, Tennis, Golf
- Gültige ÄKs:
- Segway-fahren
- Tauchen
- Tennis
- Golf
- Ungültige ÄK: "alles andere"
-
Falls eine Beschränkung eine Situation spezifiziert, die zwingend erfüllt sein muss:
Aufteilung in eine gültige und eine ungültige ÄK
Hinweis: Werden Werte einer ÄK vermutlich nicht gleichwertig behandelt, dann
erfolgt die Aufspaltung der ÄK in kleinere ÄKs. Das ist im Grunde die analoge
Überlegung zu mehreren ungültigen ÄKs.
ÄKs sollten für die weitere Arbeit einheitlich und eindeutig benannt werden.
Typisches Namensschema: "gÄKn" und "uÄKn" für gültige bzw. ungültige ÄKs mit
der laufenden Nummer $n$.
ÄK: Erstellung der Testfälle
Im Prinzip muss man zur Erstellung der Testfälle (TF) eine paarweise vollständige Kombination über
die ÄK bilden, d.h. jede ÄK kommt mit jeder anderen ÄK in einem TF zur Ausführung.
Erinnerung: Annahme: Eingabeparameter sind untereinander unabhängig! => Es reicht, wenn jede
gültige ÄK einmal in einem TF zur Ausführung kommt. => Kombination verschiedener gültiger ÄK
in einem TF.
Achtung: Dies gilt nur für die gültigen ÄK! Bei den ungültigen ÄKs dürfen diese nicht
miteinander in einem TF kombiniert werden! Bei gleichzeitiger Behandlung verschiedener ungültiger
ÄK bleiben u.U. Fehler unentdeckt, da sich die Wirkungen der ungültigen ÄK überlagern!
Für jeden Testfall (TF) wird aus den zu kombinierenden ÄK ein zufälliger Repräsentant ausgewählt.
ÄK: Beispiel: Eingabewert x soll zw. 10 und 100 liegen
Äquivalenzklassen
| Eingabe |
gültige ÄK |
ungültige ÄK |
| x |
gÄK1: $[10, 100]$ |
uÄK2: $x < 10$ |
|
|
uÄK3: $100 < x$ |
Tests
| Testnummer |
1 |
2 |
3 |
| geprüfte ÄK |
gÄK1 |
uÄK2 |
uÄK3 |
| x |
42 |
7 |
120 |
| Erwartetes Ergebnis |
OK |
Exception |
Exception |
Grenzwertanalyse

Beobachtung: Grenzen in Verzweigungen/Schleifen kritisch
- Grenzen der ÄK (kleinste und größte Werte) zusätzlich testen
- "gültige Grenzwerte" (gGW): Grenzwerte von gültigen ÄK
- "ungültige Grenzwerte" (uGW): Grenzwerte von ungültigen ÄK
Zusätzlich sinnvoll: Weitere grenznahe Werte, d.h. weitere Werte "rechts" und "links"
der Grenze nutzen.
Bildung der Testfälle:
- Jeder GW muss in mind. einem TF vorkommen
Pro TF darf ein GW (gültig oder ungültig) verwendet werden, die restlichen Parameter
werden (mit zufälligen Werten) aus gültigen ÄK aufgefüllt, um mögliche Grenzwertprobleme
nicht zu überlagern.
GW: Beispiel: Eingabewert x soll zw. 10 und 100 liegen
Äquivalenzklassen
| Eingabe |
gültige ÄK |
ungültige ÄK |
| x |
gÄK1: $[10, 100]$ |
uÄK2: $x < 10$ |
|
|
uÄK3: $100 < x$ |
Grenzwertanalyse
Zusätzliche Testdaten: 9 (uÄK2o) und 10 (gÄK1u) sowie 100 (gÄK1o) und 101 (uÄK3u)
Tests
| Testnummer |
4 |
5 |
6 |
7 |
| geprüfter GW |
gÄK1u |
gÄK1o |
uÄK2o |
uÄK3u |
| x |
10 |
100 |
9 |
101 |
| Erwartetes Ergebnis |
OK |
OK |
Exception |
Exception |
Hinweis: Die Ergebnisse der GW-Analyse werden zusätzlich zu den Werten aus der ÄK-Analyse
eingesetzt. Für das obige Beispiel würde man also folgende Tests aus der kombinierten ÄK- und
GW-Analyse erhalten:
| Testnummer |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| geprüfte(r) ÄK/GW |
gÄK1 |
uÄK2 |
uÄK3 |
gÄK1u |
gÄK1o |
uÄK2o |
uÄK3u |
| x |
42 |
7 |
120 |
10 |
100 |
9 |
101 |
| Erwartetes Ergebnis |
OK |
Exception |
Exception |
OK |
OK |
Exception |
Exception |
Anmerkung: Analyse abhängiger Parameter
Wenn das Ergebnis von der Kombination der Eingabewerte abhängt, dann
sollte man dies bei der Äquivalenzklassenbildung berücksichtigen: Die
ÄK sind in diesem Fall in Bezug auf die Kombinationen zu bilden!
Schauen Sie sich dazu das Beispiel im [Kleuker2019], Abschnitt
"4.3 Analyse abhängiger Parameter" an.
Die einfache ÄK-Bildung würde in diesem Fall versagen, da die Eingabewerte
nicht unabhängig sind. Leider ist die Betrachtung der möglichen Kombinationen
u.U. eine sehr komplexe Aufgabe ...
Analoge Überlegungen gelten auch für die ÄK-Bildung im Zusammenhang mit
objektorientierter Programmierung. Die Eingabewerte und der Objektzustand
müssen dann gemeinsam bei der ÄK-Bildung betrachtet werden!
Vergleiche [Kleuker2019], Abschnitt "4.4 Äquivalenzklassen und Objektorientierung".
Wrap-Up
- Gründliches Testen ist ebenso viel Aufwand wie Coden
- Äquivalenzklassenbildung und Grenzwertanalyse
Challenges
Der RSV Flotte Speiche hat in seiner Mitgliederverwaltung (MitgliederVerwaltung) die Methode
testBeitritt implementiert. Mit dieser Methode wird geprüft, ob neue Mitglieder in den Radsportverein
aufgenommen werden können.
public class MitgliederVerwaltung {
/**
* Testet, ob ein Mitglied in den Verein aufgenommen werden kann.
*
* @param alter Alter in Lebensjahren, Bereich [0, 99]
* @param motivation Motivation auf einer Scala von 0 bis 10
* @return <code>true</code>, wenn das Mitglied aufgenommen werden kann, sonst <code>false</code>
*/
public boolean testBeitritt(int alter, int motivation) {
if (alter < 0 || alter > 99 || motivation < 0 || motivation > 10) {
throw new IllegalArgumentException("Alter oder/und Motivation ungültig");
}
if (alter < 16) {
return false;
}
return motivation >= 4 && motivation <= 7;
}
}
-
Führen Sie eine Äquivalenzklassenbildung durch und geben Sie die gefundenen Äquivalenzklassen (ÄK)
an: laufende Nummer, Definition (Wertebereiche o.ä.), kurze Beschreibung (gültige/ungültige ÄK,
Bedeutung).
-
Führen Sie zusätzlich eine Grenzwertanalyse durch und geben Sie die jeweiligen Grenzwerte (GW) an.
-
Erstellen Sie aus den ÄK und GW wie in der Vorlesung diskutiert Testfälle. Geben Sie pro Testfall (TF)
an, welche ÄK und/oder GW abgedeckt sind, welche Eingaben Sie vorsehen und welche Ausgabe Sie erwarten.
Hinweis: Erstellen Sie separate (zusätzliche) TF für die GW, d.h. integrieren Sie diese nicht in die
ÄK-TF.
-
Implementieren Sie die Testfälle in JUnit (JUnit 4 oder 5). Fassen Sie die Testfälle der gültigen ÄK in
einem parametrisierten Test zusammen. Für die ungültigen ÄKs erstellen Sie jeweils eine eigene
JUnit-Testmethode. Beachten Sie, dass Sie auch die Exceptions testen müssen.
Quellen
- [fernunihagenJunit] Einführung in JUnit
Thies, A. und Noelke, C. und Ungerc, Fernuniversität in Hagen. - [junit4] JUnit 5
The JUnit Team, 2022. - [Kleuker2019] Qualitätssicherung durch Softwaretests
Kleuker, S., Springer Vieweg, 2019. ISBN 978-3-658-24886-4. DOI 10.1007/978-3-658-24886-4. - [Osherove2014] The Art of Unit Testing
Osherove, R., Manning, 2014. ISBN 978-1-6172-9089-3. - [Spillner2012] Basiswissen Softwaretest
Spillner, A. und Linz, T., dpunkt, 2012. ISBN 978-3-86490-024-2. - [vogellaJUnit] JUnit 5 tutorial - Learn how to write unit tests
vogella GmbH, 2021.
Mocking mit Mockito
TL;DR
Häufig hat man es in Softwaretests mit dem Problem zu tun, dass die zu testenden Klassen von
anderen, noch nicht implementierten Klassen oder von zufälligen oder langsamen Operationen
abhängen.
In solchen Situationen kann man auf "Platzhalter" für diese Abhängigkeiten zurückgreifen. Dies
können einfache Stubs sein, also Objekte, die einfach einen festen Wert bei einem Methodenaufruf
zurückliefern oder Mocks, wo man auf die Argumente eines Methodenaufrufs reagieren kann und
passende unterschiedliche Rückgabewerte zurückgeben kann.
Mockito ist eine Java-Bibliothek, die zusammen mit JUnit das Mocking von Klassen in Java
erlaubt. Man kann hier zusätzlich auch die Interaktion mit dem gemockten Objekt überprüfen und
testen, ob eine bestimmte Methode mit bestimmten Argumenten aufgerufen wurde und wie oft.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Begriffe: Mocking, Mock, Stub, Spy
- (K3) Erzeugen eines Mocks in Mockito
- (K3) Erzeugen eines Spies in Mockito
- (K3) Prüfen von Interaktion mit verify()
- (K3) Einsatz von ArgumentMatcher
Motivation: Entwicklung einer Studi-/Prüfungsverwaltung
Szenario
Zwei Teams entwickeln eine neue Studi-/Prüfungsverwaltung für die Hochschule. Ein Team modelliert dabei
die Studierenden, ein anderes Team modelliert die Prüfungsverwaltung LSF.
-
Team A:
public class Studi {
String name; LSF lsf;
public Studi(String name, LSF lsf) {
this.name = name; this.lsf = lsf;
}
public boolean anmelden(String modul) { return lsf.anmelden(name, modul); }
public boolean einsicht(String modul) { return lsf.ergebnis(name, modul) > 50; }
}
-
Team B:
public class LSF {
public boolean anmelden(String name, String modul) { throw new UnsupportedOperationException(); }
public int ergebnis(String name, String modul) { throw new UnsupportedOperationException(); }
}
Team B kommt nicht so recht vorwärts, Team A ist fertig und will schon testen.
Wie kann Team A seinen Code testen?
Optionen:
- Gar nicht testen?!
- Das LSF selbst implementieren? Wer pflegt das dann? => manuell implementierte Stubs
- Das LSF durch einen Mock ersetzen => Einsatz der Bibliothek "mockito"
Motivation Mocking und Mockito
Mockito ist ein Mocking-Framework für JUnit. Es
simuliert das Verhalten eines realen Objektes oder einer realen Methode.
Wofür brauchen wir denn jetzt so ein Mocking-Framework überhaupt?
Wir wollen die Funktionalität einer Klasse isoliert vom Rest testen können.
Dabei stören uns aber bisher so ein paar Dinge:
- Arbeiten mit den echten Objekten ist langsam (zum Beispiel aufgrund von
Datenbankenzugriffen)
- Objekte beinhalten oft komplexe Abhängigkeiten, die in Tests schwer abzudecken
sind
- Manchmal existiert der zu testende Teil einer Applikation auch noch gar nicht,
sondern es gibt nur die Interfaces.
- Oder es gibt unschöne Seiteneffekte beim Arbeiten mit den realen Objekten. Zum
Beispiel könnte es sein, das immer eine E-Mail versendet wird, wenn wir mit
einem Objekt interagieren.
In solchen Situationen wollen wir eine Möglichkeit haben, das Verhalten eines
realen Objektes bzw. der Methoden zu simulieren, ohne dabei die originalen
Methoden aufrufen zu müssen. (Manchmal möchte man das dennoch, aber dazu später
mehr...)
Und genau hier kommt Mockito ins Spiel. Mockito hilft uns dabei, uns von den
externen Abhängigkeiten zu lösen, indem es sogenannte Mocks, Stubs oder Spies
anbietet, mit denen sich das Verhalten der realen Objekte simulieren/überwachen
und testen lässt.
Aber was genau ist denn jetzt eigentlich Mocking?
Ein Mock-Objekt ("etwas vortäuschen") ist im Software-Test ein Objekt, das als Platzhalter
(Attrappe) für das echte Objekt verwendet wird.
Mocks sind in JUnit-Tests immer dann nützlich, wenn man externe Abhängigkeiten
hat, auf die der eigene Code zugreift. Das können zum Beispiel externe APIs sein
oder Datenbanken etc. ... Mocks helfen einem beim Testen nun dabei, sich von diesen
externen Abhängigkeiten zu lösen und seine Softwarefunktionalität dennoch
schnell und effizient testen zu können ohne evtl. auftretende Verbindungsfehler
oder andere mögliche Seiteneffekte der externen Abhängigkeiten auszulösen.
Dabei simulieren Mocks die Funktionalität der externen APIs oder Datenbankzugriffe.
Auf diese Weise ist es möglich Softwaretests zu schreiben, die scheinbar die gleichen
Methoden aufrufen, die sie auch im regulären Softwarebetrieb nutzen würden, allerdings
werden diese wie oben erwähnt allerdings für die Tests nur simuliert.
Mocking ist also eine Technik, die in Softwaretests verwendet wird, in denen die
gemockten Objekte anstatt der realen Objekte zu Testzwecken genutzt werden. Die
gemockten Objekte liefern dabei bei einem vom Programmierer bestimmten (Dummy-) Input,
einen dazu passenden gelieferten (Dummy-) Output, der durch seine vorhersagbare
Funktionalität dann in den eigentlichen Testobjekten gut für den Test nutzbar ist.
Dabei ist es von Vorteil die drei Grundbegriffe "Mock", "Stub" oder "Spy", auf die wir
in der Vorlesung noch häufiger treffen werden, voneinander abgrenzen und
unterscheiden zu können.
Dabei bezeichnet ein
- Stub: Ein Stub ist ein Objekt, dessen Methoden nur mit einer minimalen Logik
für den Test implementiert wurden. Häufig werden dabei einfach feste (konstante)
Werte zurückgeliefert, d.h. beim Aufruf einer Methode wird unabhängig von der konkreten
Eingabe immer die selbe Ausgabe zurückgeliefert.
- Mock: Ein Mock ist ein Objekt, welches im Gegensatz zum Stub bei vorher definierten
Funktionsaufrufen mit vorher definierten Argumente eine definierte Rückgabe liefert.
- Spy: Ein Spy ist ein Objekt, welches Aufrufe und übergebene Werte protokolliert und
abfragbar macht. Es ist also eine Art Wrapper um einen Stub oder einen Mock.
Mockito Setup
-
Gradle: build.gradle
dependencies {
implementation 'junit:junit:4.13.2'
implementation 'org.mockito:mockito-core:4.5.1'
}
-
Maven: pom.xml
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
</dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-core</artifactId>
<version>4.5.1</version>
</dependency>
</dependencies>
Manuell Stubs implementieren
Team A könnte manuell das LSF rudimentär implementieren (nur für die Tests, einfach mit
festen Rückgabewerten): Stubs
public class StudiStubTest {
Studi studi; LSF lsf;
@Before
public void setUp() { lsf = new LsfStub(); studi = new Studi("Harald", lsf); }
@Test
public void testAnmelden() { assertTrue(studi.anmelden("PM-Dungeon")); }
@Test
public void testEinsicht() { assertTrue(studi.einsicht("PM-Dungeon")); }
// Stub für das noch nicht fertige LSF
class LsfStub extends LSF {
public boolean anmelden(String name, String modul) { return true; }
public int ergebnis(String name, String modul) { return 80; }
}
}
Problem: Wartung der Tests (wenn das richtige LSF fertig ist) und Wartung der Stubs (wenn sich die Schnittstelle
des LSF ändert, muss auch der Stub nachgezogen werden).
Problem: Der Stub hat nur eine Art minimale Default-Logik (sonst könnte man ja das LSF gleich selbst implementieren).
Wenn man im Test andere Antworten braucht, müsste man einen weiteren Stub anlegen ...
Mockito: Mocking von ganzen Klassen
Lösung: Mocking der Klasse LSF mit Mockito für den Test von Studi: mock().
public class StudiMockTest {
Studi studi; LSF lsf;
@Before
public void setUp() { lsf = mock(LSF.class); studi = new Studi("Harald", lsf); }
@Test
public void testAnmelden() {
when(lsf.anmelden(anyString(), anyString())).thenReturn(true);
assertTrue(studi.anmelden("PM-Dungeon"));
}
@Test
public void testEinsichtI() {
when(lsf.ergebnis("Harald", "PM-Dungeon")).thenReturn(80);
assertTrue(studi.einsicht("PM-Dungeon"));
}
@Test
public void testEinsichtII() {
when(lsf.ergebnis("Harald", "PM-Dungeon")).thenReturn(40);
assertFalse(studi.einsicht("PM-Dungeon"));
}
}
Der Aufruf mock(LSF.class) erzeugt einen Mock der Klasse (oder des Interfaces) LSF. Dabei wird ein Objekt
vom Typ LSF erzeugt, mit dem man dann wie mit einem normalen Objekt weiter arbeiten kann. Die Methoden sind
allerdings nicht implementiert ...
Mit Hilfe von when().thenReturn() kann man definieren, was genau beim Aufruf einer bestimmten Methode auf dem
Mock passieren soll, d.h. welcher Rückgabewert entsprechend zurückgegeben werden soll. Hier kann man dann für
bestimmte Argumentwerte andere Rückgabewerte definieren. when(lsf.ergebnis("Harald", "PM-Dungeon")).thenReturn(80)
gibt also für den Aufruf von ergebnis mit den Argumenten "Harald" und "PM-Dungeon" auf dem Mock lsf
den Wert 80 zurück.
Dies kann man in weiten Grenzen flexibel anpassen.
Mit Hilfe der Argument-Matcher anyString() wird jedes String-Argument akzeptiert.
Mockito: Spy = Wrapper um ein Objekt
Team B hat das LSF nun implementiert und Team A kann es endlich für die Tests benutzen. Aber
das LSF hat eine Zufallskomponente (ergebnis()). Wie kann man nun die Reaktion des Studis
testen (einsicht())?
Lösung: Mockito-Spy als partieller Mock einer Klasse (Wrapper um ein Objekt): spy().
public class StudiSpyTest {
Studi studi; LSF lsf;
@Before
public void setUp() { lsf = spy(LSF.class); studi = new Studi("Harald", lsf); }
@Test
public void testAnmelden() { assertTrue(studi.anmelden("PM-Dungeon")); }
@Test
public void testEinsichtI() {
doReturn(80).when(lsf).ergebnis("Harald", "PM-Dungeon");
assertTrue(studi.einsicht("PM-Dungeon"));
}
@Test
public void testEinsichtII() {
doReturn(40).when(lsf).ergebnis("Harald", "PM-Dungeon");
assertFalse(studi.einsicht("PM-Dungeon"));
}
}
Der Aufruf spy(LSF.class) erzeugt einen Spy um ein Objekt der Klasse LSF. Dabei bleiben zunächst die Methoden
in LSF erhalten und können aufgerufen werden, sie können aber auch mit einem (partiellen) Mock überlagert werden.
Der Spy zeichnet wie der Mock die Interaktion mit dem Objekt auf.
Mit Hilfe von doReturn().when() kann man definieren, was genau beim Aufruf einer bestimmten Methode auf dem
Spy passieren soll, d.h. welcher Rückgabewert entsprechend zurückgegeben werden soll. Hier kann man analog zum Mock
für bestimmte Argumentwerte andere Rückgabewerte definieren. doReturn(40).when(lsf).ergebnis("Harald", "PM-Dungeon")
gibt also für den Aufruf von ergebnis mit den Argumenten "Harald" und "PM-Dungeon" auf dem Spy lsf den Wert
40 zurück.
Wenn man die Methoden nicht mit einem partiellen Mock überschreibt, dann wird einfach die originale Methode aufgerufen
(Beispiel: In studi.anmelden("PM-Dungeon") wird lsf.anmelden("Harald", "PM-Dungeon") aufgerufen.).
Auch hier können Argument-Matcher wie anyString() eingesetzt werden.
Wurde eine Methode aufgerufen?
public class VerifyTest {
@Test
public void testAnmelden() {
LSF lsf = mock(LSF.class); Studi studi = new Studi("Harald", lsf);
when(lsf.anmelden("Harald", "PM-Dungeon")).thenReturn(true);
assertTrue(studi.anmelden("PM-Dungeon"));
verify(lsf).anmelden("Harald", "PM-Dungeon");
verify(lsf, times(1)).anmelden("Harald", "PM-Dungeon");
verify(lsf, atLeast(1)).anmelden("Harald", "PM-Dungeon");
verify(lsf, atMost(1)).anmelden("Harald", "PM-Dungeon");
verify(lsf, never()).ergebnis("Harald", "PM-Dungeon");
verifyNoMoreInteractions(lsf);
}
}
Mit der Methode verify() kann auf einem Mock oder Spy überprüft werden, ob und wie oft und in welcher Reihenfolge
Methoden aufgerufen wurden und mit welchen Argumenten. Auch hier lassen sich wieder Argument-Matcher wie anyString()
einsetzen.
Ein einfaches verify(mock) prüft dabei, ob die entsprechende Methode exakt einmal vorher aufgerufen wurde. Dies
ist äquivalent zu verify(mock, times(1)). Analog kann man mit den Parametern atLeast() oder atMost bestimmte
Unter- oder Obergrenzen für die Aufrufe angeben und mit never() prüfen, ob es gar keinen Aufruf vorher gab.
verifyNoMoreInteractions(lsf) ist interessant: Es ist genau dann true, wenn es außer den vorher abgefragten
Interaktionen keinerlei sonstigen Interaktionen mit dem Mock oder Spy gab.
LSF lsf = mock(LSF.class);
Studi studi = new Studi("Harald", lsf);
when(lsf.anmelden("Harald", "PM-Dungeon")).thenReturn(true);
InOrder inOrder = inOrder(lsf);
assertTrue(studi.anmelden("PM-Dungeon"));
studi.anmelden("Wuppie");
inOrder.verify(lsf).anmelden("Harald", "Wuppie");
inOrder.verify(lsf).anmelden("Harald", "PM-Dungeon");
Mit InOrder lassen sich Aufrufe auf einem Mock/Spy oder auch auf verschiedenen Mocks/Spies in eine zeitliche
Reihenfolge bringen und so überprüfen.
Fangen von Argumenten
public class MatcherTest {
@Test
public void testAnmelden() {
LSF lsf = mock(LSF.class); Studi studi = new Studi("Harald", lsf);
when(lsf.anmelden(anyString(), anyString())).thenReturn(false);
when(lsf.anmelden("Harald", "PM-Dungeon")).thenReturn(true);
assertTrue(studi.anmelden("PM-Dungeon"));
assertFalse(studi.anmelden("Wuppie?"));
verify(lsf, times(1)).anmelden("Harald", "PM-Dungeon");
verify(lsf, times(1)).anmelden("Harald", "Wuppie?");
verify(lsf, times(2)).anmelden(anyString(), anyString());
verify(lsf, times(1)).anmelden(eq("Harald"), eq("Wuppie?"));
verify(lsf, times(2)).anmelden(argThat(new MyHaraldMatcher()), anyString());
}
class MyHaraldMatcher implements ArgumentMatcher<String> {
public boolean matches(String s) { return s.equals("Harald"); }
}
}
Sie können die konkreten Argumente angeben, für die der Aufruf gelten soll. Alternativ
können Sie mit vordefinierten ArgumentMatchers wie anyString() beispielsweise auf
beliebige Strings reagieren oder selbst einen eigenen ArgumentMatcher<T> für Ihren
Typ T erstellen und nutzen.
Wichtig: Wenn Sie für einen Parameter einen ArgumentMatcher einsetzen, müssen Sie
für die restlichen Parameter der Methode dies ebenfalls tun. Sie können keine konkreten
Argumente mit ArgumentMatcher mischen.
Sie finden viele weitere vordefinierte Matcher in der Klasse ArgumentMatchers.
Mit der Klasse ArgumentCaptor<T> finden Sie eine alternative Möglichkeit, auf
Argumente in gemockten Methoden zu reagieren. Schauen Sie sich dazu die Javadoc
von Mockito an.
Ausblick: PowerMock
Mockito sehr mächtig, aber unterstützt (u.a.) keine
- Konstruktoren
- private Methoden
- final Methoden
- static Methoden
(ab Version 3.4.0 scheint auch Mockito statische Methoden zu unterstützen)
=> Lösung: PowerMock
Ausführlicheres Beispiel: WuppiWarenlager
Credits: Der Dank für die Erstellung des nachfolgenden Beispiels und Textes geht an
@jedi101.
Bei dem gezeigten Beispiel unseres WuppiStores sieht man, dass dieser
normalerweise von einem fertigen Warenlager die Wuppis beziehen möchte. Da
dieses Lager aber noch nicht existiert, haben wir uns kurzerhand einfach einen
Stub von unserem IWuppiWarenlager-Interface erstellt, in dem wir zu
Testzwecken händisch ein Paar Wuppis ins Lager geräumt haben.
Das funktioniert in diesem Mini-Testbeispiel ganz gut aber, wenn unsere Stores
erst einmal so richtig Fahrt aufnehmen und wir irgendwann weltweit Wuppis
verkaufen, wird der Code des IWuppiWarenlagers wahrscheinlich sehr schnell viel
komplexer werden, was unweigerlich dann zu Maintenance-Problemen unserer
händisch angelegten Tests führt. Wenn wir zum Beispiel einmal eine Methode
hinzufügen wollen, die es uns ermöglicht, nicht immer alle Wuppis aus dem Lager
zu ordern oder vielleicht noch andere Methoden, die Fluppis orderbar machen,
hinzufügen, müssen wir immer dafür sorgen, dass wir die getätigten Änderungen
händisch in den Stub des Warenlagers einpflegen.
Das will eigentlich niemand...
Einsatz von Mockito
Aber es gibt da einen Ausweg. Wenn es komplexer wird, verwenden wir Mocks.
Bislang haben wir noch keinen Gebrauch von Mockito gemacht. Das ändern wir nun.
Wie in diesem Beispiel gezeigt, müssen wir nun keinen Stub mehr von Hand
erstellen, sondern überlassen dies Mockito.
IWuppiWarenlager lager = mock(IWuppiWarenlager.class);
Anschließend können wir, ohne die Methode getAllWuppis() implementiert zu haben,
dennoch so tun als, ob die Methode eine Funktionalität hätte.
// Erstellen eines imaginären Lagerbestands.
List<String> wuppisImLager = Arrays.asList("GruenerWuppi","RoterWuppi");
when(lager.getAlleWuppis()).thenReturn(wuppisImLager);
Wann immer nun die Methode getAlleWuppis() des gemockten Lagers aufgerufen
wird, wird dieser Aufruf von Mockito abgefangen und wie oben definiert
verändert. Das Ergebnis können wir abschließend einfach in unserem Test testen:
// Erzeugen des WuppiStores.
WuppiStore wuppiStore = new WuppiStore(lager);
// Bestelle alle Wuppis aus dem gemockten Lager List<String>
bestellteWuppis = wuppiStore.bestelleAlleWuppis(lager);
// Hat die Bestellung geklappt?
assertEquals(2,bestellteWuppis.size());
Mockito Spies
Manchmal möchten wir allerdings nicht immer gleich ein ganzes Objekt mocken,
aber dennoch Einfluss auf die aufgerufenen Methoden eines Objekts haben, um
diese testen zu können. Vielleicht gibt es dabei ja sogar eine Möglichkeit unsere
JUnit-Tests, mit denen wir normalerweise nur Rückgabewerte von Methoden testen
können, zusätzlich auch das Verhalten also die Interaktionen mit einem Objekt
beobachtbar zu machen. Somit wären diese Interaktionen auch testbar.
Und genau dafür bietet Mockito eine Funktion: der sogenannte "Spy".
Dieser Spion erlaubt es uns nun zusätzlich das Verhalten zu testen. Das geht in
die Richtung von BDD - Behavior Driven Development.
// Spion erstellen, der unser wuppiWarenlager überwacht.
this.wuppiWarenlager = spy(WuppiWarenlager.class);
Hier hatten wir uns einen Spion erzeugt, mit dem sich anschließend das Verhalten
verändern lässt:
when(wuppiWarenlager.getAlleWuppis()).thenReturn(Arrays.asList(new Wuppi("Wuppi007")));
Aber auch der Zugriff lässt sich kontrollieren/testen:
verify(wuppiWarenlager).addWuppi(normalerWuppi);
verifyNoMoreInteractions(wuppiWarenlager);
Die normalen Testmöglichkeiten von JUnit runden unseren Test zudem ab.
assertEquals(1,wuppiWarenlager.lager.size());
Mockito und Annotationen
In Mockito können Sie wie oben gezeigt mit mock() und spy() neue
Mocks bzw. Spies erzeugen und mit verify() die Interaktion überprüfen
und mit ArgumentMatcher<T> bzw. den vordefinierten ArgumentMatchers
auf Argumente zuzugreifen bzw. darauf zu reagieren.
Zusätzlich/alternativ gibt es in Mockito zahlreiche Annotationen, die
ersatzweise statt der genannten Methoden genutzt werden können. Hier
ein kleiner Überblick über die wichtigsten in Mockito verwendeten Annotation:
-
@Mock wird zum Markieren des zu mockenden Objekts verwendet.
@Mock
WuppiWarenlager lager;
-
@RunWith(MockitoJUnitRunner.class) ist der entsprechende JUnit-Runner,
wenn Sie Mocks mit @Mock anlegen.
@RunWith(MockitoJUnitRunner.class)
public class ToDoBusinessMock {...}
-
@Spy erlaubt das Erstellen von partiell gemockten Objekten. Dabei wird eine
Art Wrapper um das zu mockende Objekt gewickelt, der dafür sorgt, dass alle
Methodenaufrufe des Objekts an den Spy delegiert werden. Diese können über den
Spion dann abgefangen/verändert oder ausgewertet werden.
@Spy
ArrayList<Wuppi> arrayListenSpion;
-
@InjectMocks erlaubt es, Parameter zu markieren, in denen Mocks und/oder
Spies injiziert werden. Mockito versucht dann (in dieser Reihenfolge) per
Konstruktorinjektion, Setterinjektion oder Propertyinjektion die Mocks zu
injizieren. Weitere Informationen darüber findet man hier:
Mockito Dokumentation
Anmerkung: Es ist aber nicht ratsam "Field- oder Setterinjection" zu nutzen,
da man nur bei der Verwendung von "Constructorinjection" sicherstellen kann, das
eine Klasse nicht ohne die eigentlich notwendigen Parameter instanziiert wurde.
@InjectMocks
Wuppi fluppi;
-
@Captor erlaubt es, die Argumente einer Methode abzufangen/auszuwerten. Im
Zusammenspiel mit Mockitos verify()-Methode kann man somit auch die einer
Methode übergebenen Argumente verifizieren.
@Captor
ArgumentCaptor<String> argumentCaptor;
-
@ExtendWith(MockitoExtension.class) wird in JUnit5 verwendet, um die
Initialisierung von Mocks zu vereinfachen. Damit entfällt zum Beispiel die
noch unter JUnit4 nötige Initialisierung der Mocks durch einen Aufruf der
Methode MockitoAnnotations.openMocks() im Setup des Tests (@Before bzw.
@BeforeEach).
Prüfen der Interaktion mit verify()
Mit Hilfe der umfangreichen verify()-Methoden, die uns Mockito mitliefert, können
wir unseren Code unter anderem auf unerwünschte Seiteneffekte testen. So ist es mit
verify zum Beispiel möglich abzufragen, ob mit einem gemockten Objekt interagiert
wurde, wie damit interagiert wurde, welche Argumente dabei übergeben worden sind und
in welcher Reihenfolge die Interaktionen damit erfolgt sind.
Hier nur eine kurze Übersicht über das Testen des Codes mit Hilfe von Mockitos
verify()-Methoden.
@Test
public void testVerify_DasKeineInteraktionMitDerListeStattgefundenHat() {
// Testet, ob die spezifizierte Interaktion mit der Liste nie stattgefunden hat.
verify(fluppisListe, never()).clear();
}
@Test
public void testVerify_ReihenfolgeDerInteraktionenMitDerFluppisListe() {
// Testet, ob die Reihenfolge der spezifizierten Interaktionen mit der Liste eingehalten wurde.
fluppisListe.clear();
InOrder reihenfolge = inOrder(fluppisListe);
reihenfolge.verify(fluppisListe).add("Fluppi001");
reihenfolge.verify(fluppisListe).clear();
}
@Test
public void testVerify_FlexibleArgumenteBeimZugriffAufFluppisListe() {
// Testet, ob schon jemals etwas zu der Liste hinzugefügt wurde.
// Dabei ist es egal welcher String eingegeben wurde.
verify(fluppisListe).add(anyString());
}
@Test
public void testVerify_InteraktionenMitHilfeDesArgumentCaptor() {
// Testet, welches Argument beim Methodenaufruf übergeben wurde.
fluppisListe.addAll(Arrays.asList("BobDerBaumeister"));
ArgumentCaptor<List> argumentMagnet = ArgumentCaptor.forClass(FluppisListe.class);
verify(fluppisListe).addAll(argumentMagnet.capture());
List<String> argumente = argumentMagnet.getValue();
assertEquals("BobDerBaumeister", argumente.get(0));
}
Wrap-Up
Challenges
Betrachten Sie die drei Klassen Utility.java, Evil.java
und UtilityTest.java:
public class Utility {
private int intResult = 0;
private Evil evilClass;
public Utility(Evil evilClass) {
this.evilClass = evilClass;
}
public void evilMethod() {
int i = 2 / 0;
}
public int nonEvilAdd(int a, int b) {
return a + b;
}
public int evilAdd(int a, int b) {
evilClass.evilMethod();
return a + b;
}
public void veryEvilAdd(int a, int b) {
evilMethod();
evilClass.evilMethod();
intResult = a + b;
}
public int getIntResult() {
return intResult;
}
}
public class Evil {
public void evilMethod() {
int i = 3 / 0;
}
}
public class UtilityTest {
private Utility utilityClass;
// Initialisieren Sie die Attribute entsprechend vor jedem Test.
@Test
void test_nonEvilAdd() {
Assertions.assertEquals(10, utilityClass.nonEvilAdd(9, 1));
}
@Test
void test_evilAdd() {
Assertions.assertEquals(10, utilityClass.evilAdd(9, 1));
}
@Test
void test_veryEvilAdd() {
utilityClass.veryEvilAdd(9, 1);
Assertions.assertEquals(10, utilityClass.getIntResult());
}
}
Testen Sie die Methoden nonEvilAdd, evilAdd und veryEvilAdd der
Klasse Utility.java mit dem JUnit- und dem
Mockito-Framework.
Vervollständigen Sie dazu die Klasse UtilityTest.java und nutzen Sie
Mocking mit Mockito, um die Tests
zum Laufen zu bringen. Die Tests dürfen Sie entsprechend verändern, aber
die Aufrufe aus der Vorgabe müssen erhalten bleiben. Die Klassen Evil.java
und Utility.java dürfen Sie nicht ändern.
Hinweis: Die Klasse Evil.java und die Methode evilMethod() aus
Utility.java lösen eine ungewollte bzw. "zufällige" Exception aus,
auf deren Auftreten jedoch nicht getestet werden soll. Stattdessen
sollen diese Klassen bzw. Methoden mit Mockito "weggemockt" werden, so
dass die vorgegebenen Testmethoden (wieder) funktionieren.
Quellen
- [Mockito] Mockito
S. Faber and B. Dutheil and R. Winterhalter and T.v.d. Lippe, 2022.
Subsections of Fortgeschrittene Java-Themen und Umgang mit JVM
Serialisierung von Objekten und Zuständen
TL;DR
Objekte lassen sich mit der Methode void writeObject(Object) in ObjectOutputStream
einfach in einen Datenstrom schreiben. Dies kann beispielsweise eine Datei o.ä. sein.
Mit Hilfe von Object readObject() in ObjectInputStream lassen sich Objekte aus dem
Datenstrom auch wieder herstellen. Dies nennt man Serialisierung und De-Serialisierung.
Um Objekte einer Klasse serialisieren zu können, muss diese das leere Interface
Serializable implementieren ("Marker-Interface"). Damit wird quasi die Unterstützung
in Object*Stream freigeschaltet.
Wenn ein Objekt serialisiert wird, werden alle Attribute in den Datenstrom geschrieben,
d.h. die Typen der Attribute müssen ihrerseits serialisierbar sein. Dies gilt für alle
primitiven Typen und die meisten eingebauten Typen. Die Serialisierung erfolgt ggf.
rekursiv, Zirkelreferenzen werden erkannt und aufgebrochen.
static und transient Attribute werden nicht serialisiert.
Beim De-Serialisieren wird das neue Objekt von der Laufzeitumgebung aus dem Datenstrom
rekonstruiert. Dies geschieht direkt, es wird kein Konstruktor involviert.
Beim Serialisieren wird für die Klasse des zu schreibenden Objekts eine serialVersionUID
berechnet und mit gespeichert. Beim Einlesen wird dann geprüft, ob die serialisierten
Daten zur aktuellen Version der Klasse passen. Da dies relativ empfindlich gegenüber
Änderungen an einer Klasse ist, wird empfohlen, selbst eine serialVersionUID pro
Klasse zu definieren.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Was ist ein Marker-Interface und warum ist dies eine der großen Design-Sünden in Java?
- (K2) Erklären Sie den Prozess der Serialisierung und De-Serialisierung. Worauf müssen Sie achten?
- (K3) Serialisierung von Objekten und Programmzuständen
- (K3) Serialisierung eigener Klassen und Typen
Motivation: Persistierung von Objekten und Spielzuständen
public class Studi {
private final int credits = 42;
private String name = "Hilde";
...
}
Wie kann ich Objekte speichern und wieder laden?
Ich möchte ein Spiel (einen Lauf) im Dungeon abspeichern, um es später fortsetzen
zu können. Wie kann ich den aktuellen Zustand (also Level, Monster, Held, Inventar,
XP/Health/...) so speichern, dass ich später das Spiel nach einem Neustart einfach
fortsetzen kann?
Serialisierung von Objekten
-
Klassen müssen Marker-Interface Serializable implementieren
"Marker-Interface": Interface ohne Methoden. Ändert das Verhalten
des Compilers, wenn eine Klasse dieses Interface implementiert:
Weitere Funktionen werden "freigeschaltet", beispielsweise die
Fähigkeit, Klone zu erstellen (Cloneable) oder bei Serializable
Objekte serialisierbar zu machen.
Das ist in meinen Augen eine "Design-Sünde" in Java (neben der
Einführung von null): Normalerweise definieren Interfaces eine
Schnittstelle, die eine das Interface implementierende Klasse
dann erfüllen muss. Damit agiert das Interface wie ein Typ. Hier
ist das Interface aber leer, es wird also keine Schnittstelle
definiert. Aber es werden damit stattdessen Tooling-Optionen
aktiviert, was Interfaces vom Konzept her eigentlich nicht machen
sollten/dürften - dazu gibt es Annotationen!
-
Schreiben von Objekten (samt Zustand) in Streams
ObjectOutputStream: void writeObject(Object)
Die Serialisierung erfolgt dabei für alle Attribute
(außer static und transient, s.u.) rekursiv.
Dabei werden auch Zirkelreferenzen automatisch
aufgelöst/unterbrochen.
-
Lesen und "Wiedererwecken" der Objekte aus Streams
ObjectInputStream: Object readObject()
Dabei erfolgt KEIN Konstruktor-Aufruf!
Einfaches Beispiel
public class Studi implements Serializable {
private final int credits = 42;
private String name = "Hilde";
public static void writeObject(Studi studi, String filename) {
try (FileOutputStream fos = new FileOutputStream(filename);
ObjectOutputStream oos = new ObjectOutputStream(fos)) {
oos.writeObject(studi); oos.close();
} catch (IOException ex) {}
}
public static Studi readObject(String filename) {
Studi studi = null;
try (FileInputStream fis = new FileInputStream(filename);
ObjectInputStream ois = new ObjectInputStream(fis)) {
studi = (Studi) ois.readObject(); ois.close();
} catch (IOException | ClassNotFoundException ex) {}
return studi;
}
}
Bedingungen für Objekt-Serialisierung
- Klassen implementieren Marker-Interface
Serializable
- Alle Attribute müssen ebenfalls serialisierbar sein (oder Deklaration "
transient")
- Alle primitiven Typen sind per Default serialisierbar
- Es wird automatisch rekursiv serialisiert, aber jedes Objekt
nur einmal (bei Mehrfachreferenzierung)
- Serialisierbarkeit vererbt sich
Ausnahmen
- Als
static deklarierte Attribute werden nicht serialisiert
- Als
transient deklarierte Attribute werden nicht serialisiert
- Nicht serialisierbare Attribut-Typen führen zu
NotSerializableException
Version-UID
static final long serialVersionUID = 42L;
- Dient zum Vergleich der serialisierten Version und der aktuellen Klasse
- Über IDE generieren oder manuell vergeben
- Wenn das Attribut fehlt, wird eine Art Checksumme von der Runtime-Umgebung
berechnet (basierend auf diversen Eigenschaften der Klasse)
Dieser Wert wird beim Einlesen verglichen: Das Objekt wird nur dann wieder de-serialisiert,
wenn die serialVersionUID mit der einzulesenden Klasse übereinstimmt!
Bei automatischer Berechnung der serialVersionUID durch die JVM kann jede kleine Änderung an
der Klasse (beispielsweise Refactoring: Änderung der Methodennamen) eine neue serialVersionUID
zur Folge haben. Das würde bedeuten, dass bereits serialisierte Objekte nicht mehr eingelesen
werden können, auch wenn sich nur Methoden o.ä. verändert haben und die Attribute noch so vorhanden
sind. Deshalb bietet es sich an, hier selbst eine serialVersionUID zu definieren - dann muss
man aber auch selbst darauf achten, diese zu verändern, wenn sich wesentliche strukturelle
Änderungen an der Klasse ergeben!
Bemerkungen
Es existieren diverse weitere Fallstricke und Probleme, siehe [Bloch2018] Kapitel 11 "Serialization".
Man kann in den ObjectOutputStream nicht nur ein Objekt schreiben, sondern mehrere Objekte und
Variablen schreiben lassen. In dieser Reihenfolge muss man diese dann aber auch wieder aus dem
Stream herauslesen (vgl. Object Streams).
Man kann die zu serialisierenden Attribute mit der Annotation @Serial markieren. Dies ist in
der Wirkung ähnlich zu @Override: Der Compiler prüft dann, ob die markierten Attribute wirklich
serialisierbar sind und würde sonst zur Compile-Zeit einen Fehler werfen.
Weitere Links:
Wrap-Up
-
Markerinterface Serializable schaltet Serialisierbarkeit frei
-
Objekte schreiben: ObjectOutputStream: void writeObject(Object)
-
Objekte lesen: ObjectInputStream: Object readObject()
-
Wichtigste Eigenschaften:
- Attribute müssen serialisierbar sein
transient und static Attribute werden nicht serialisiert- De-Serialisierung: KEIN Konstruktor-Aufruf!
- Serialisierbarkeit vererbt sich
- Objekt-Referenz-Graph wird automatisch beachtet
Challenges
Implementieren Sie die beiden Klassen entsprechend dem UML-Diagram:

Objekte vom Typ Person sowie Address sollen serialisierbar sein (vgl. Vorlesung).
Dabei soll das Passwort nicht serialisiert bzw. gespeichert werden, alle anderen
Eigenschaften von Person sollen serialisierbar sein.
Hinweis: Verwenden Sie zur Umsetzung java.io.Serializable.
Erstellen Sie in Ihrem main() einige Instanzen von Person und speichern Sie diese in
serialisierter Form und laden (deserialisieren) Sie diese anschließend in neue Variablen.
Betrachten Sie die ursprünglichen und die wieder deserialisierten Objekte mit Hilfe des
Debuggers. Alternativ können Sie die Objekte auch in übersichtlicher Form über den Logger
ausgeben.
Quellen
- [Bloch2018] Effective Java
Bloch, J., Addison-Wesley, 2018. ISBN 978-0-13-468599-1. - [Java-SE-Tutorial] The Java Tutorials
Oracle Corporation, 2022.
Essential Java Classes \> Basic I/O \> Object Streams
Java Collections Framework
TL;DR
Die Collection-API bietet verschiedene Sammlungen an, mit denen man Objekte speichern kann: Listen, Queues, Mengen, ...
Für diese Typen gibt es jeweils verschiedene Implementierungen mit einem spezifischen Verhalten. Zusätzlich gibt es noch
Maps für das Speichern von Key/Value-Paaren, dabei wird für die Keys eine Hash-Tabelle eingesetzt.
Die Hilfs-Klasse Collections bietet statische Hilfs-Methoden, die auf Collection<T>s anwendbar sind.
Wenn man eigene Klassen in der Collection-API oder in Map benutzen möchte, sollte man den "equals-hashCode-Contract"
berücksichtigen.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Was ist der Unterschied zwischen
Collection<T> und List<T>? - (K2) Was ist der Unterschied zwischen einer
List<T>, einer Queue<T> und einer Set<T>? - (K2) Nennen Sie charakteristische Merkmale von
ArrayList<T>, LinkedList<T> und Vector<T>. - (K2) Was ist der Unterschied zwischen einer
Queue<T> und einem Stack<T>? - (K2) Was ist eine
Map<K,V>? Welche Vertreter kennen Sie? - (K3) Erklären Sie die 'Spielregeln' für die eigene Implementierung von
equals(). - (K3) Erklären Sie die 'Spielregeln' für die eigene Implementierung von
hashCode(). - (K3) Erklären Sie die 'Spielregeln' für die eigene Implementierung von
compareTo(). - (K3) Wie müssen und wie sollten
equals(), hashCode() und compareTo() miteinander arbeiten?
Motivation: Snippet aus einer Klasse im PM-Dungeon
private List<Entity> entities = new ArrayList<>();
public void add(Entity e){
if (!entities.contains(e)) entities.add(e);
}
Die war ein reales Beispiel aus der Entwicklung des PM-Dungeon.
Es wurde eine ArrayList<T> zum Verwalten der Entitäten genutzt. Allerdings sollte
jedes Element nur einmal in der Liste vorkommen, deshalb wurde beim Einfügen einer
Entität geprüft, ob diese bereits in der Liste ist.
Hier wird die falsche Datenstruktur genutzt!
Eine Liste kann ein Objekt mehrfach enthalten, eine Menge (Set) hingegen kann ein
Objekt nur einmal enthalten.
Collection-API in Java

Hinweis: Die abstrakten (Zwischen-) Klassen wurden im obigen UML aus Gründen der
Übersichtlichkeit nicht aufgeführt. Aus den selben Gründen sind auch nur ausgewählte
Methoden aufgenommen worden.
Hinweis: Blau = Interface, Grün = Klasse.
Collection<T> ist ein zentrales Interface im JDK und stellt die gemeinsame API der
Collection-Klassen dar. Klassen, die Collection<T> implementieren, speichern und
verwalten eine Menge an Objekten.
Unter anderem gibt es die aus dem Modul "ADS" bekannten Datentypen wie Listen, Sets,
Queues etc.
Man unterscheidet zwischen "sorted" (geordnete) Collections, welche eine bestimmte
Reihenfolge der Elemente halten (Reihenfolge des Einfügens, aufsteigende Werte etc.)
und "unsorted" (ungeordnete) Collections, welche keine bestimmte Reihenfolge halten.
Eine Übersicht, welche Collection welche Datenstruktur implementiert, kann unter
"Collection Implementations"
eingesehen werden.
List<T>-Collections sind eine geordnete Liste an Objekten. Per Index-Zugriff können
Objekte an jeder Stelle der Liste zugegriffen (oder hinzugefügt) werden.Queue<T>-Collections sind eine geordnete Sammlung von Objekten. Objekte können nur
am Ende der Queue hinzugefügt werden und nur am Anfang der Queue (der Head) gelesen
oder entnommen werden ("first in first out").Set<T>-Collections sind eine (i.d.R.!) ungeordnete Menge an Objekten, die stets nur
einmal in der Set enthalten sein können. In einem Set kann nicht direkt auf ein Objekt
zugegriffen werden. Es kann aber geprüft werden, ob ein spezifisches Objekt in einer
Set gespeichert ist.
Wichtig: List<T>, Set<T>, Queue<T> und Map<K,V> sind Interfaces, definieren
also bestimmte Schnittstellen, die sich so wie aus ADS her bekannt verhalten. Diese können
jeweils mit sehr unterschiedlichen Datenstrukturen implementiert werden und können dadurch
auch intern ein anderes Verhalten haben (sortiert vs. nicht sortiert, Zugriffszeiten, ...).
Siehe auch Interface Collection.
Listen: ArrayList
private List<Entity> entities = new ArrayList<>();

Link zu einer netten Animation
Eine ArrayList<T> ist von außen betrachtet ein sich dynamisch vergrößerndes Array.
Intern wird allerdings ein statisches(!) Array benutzt. Wenn dieses Array voll ist,
wird es um 50% vergrößert und alle Inhalte in das neue Array kopiert. Davon merkt
man als Nutzer aber nichts.
Dank es Arrays kann auf ein Element per Index mit O(1) zugegriffen werden.
Wird ein Element aus der Liste gelöscht, rücken alle Nachfolgenden Einträge in der
Liste einen Index auf (interner Kopiervorgang).
Deshalb ist eine ArrayList<T> effizient in der Abfrage und Manipulation von Einträgen,
aber deutlich weniger effizient beim Hinzufügen und Löschen von Einträgen.
Per Default wird eine ArrayList<T> mit einem Array der Länge 10 angelegt, sobald das
erste Element eingefügt wird. Man kann die Startgröße auch im Konstruktoraufruf der
ArrayList<T> bestimmen: beispielsweise new ArrayList<>(20).
Die Methoden einer ArrayList<T> sind nicht synchronized.
Listen: LinkedList

Link zu einer netten Animation
Eine LinkedList<T> ist eine Implementierung einer doppelt verketteten Liste (diese
kennen Sie bereits aus ADS) in Java.
Jeder Eintrag wird als Knoten repräsentiert, der den eigentlichen Wert speichert und
zusätzlich je einen Verweis auf den Vorgänger- und Nachfolger-Knoten hat.
Der Head der LinkedList<T> zeigt auf den Anfang der Liste, der Nachfolger des letzten
Eintrag ist immer null.
Für den Zugriff auf ein Element muß man die LinkedList<T> traversieren und beginnt
dabei am Anfang der Liste, deshalb ist ein Zugriff O(n).
Neue Elemente können effizient an das Ende der Liste eingefügt werden, indem der letzte
Eintrag einen Verweis auf den neuen Knoten bekommt: O(1) (sofern man sich nicht nur den
Start der Liste merkt, sondern auch das aktuelle Ende).
Wenn ein Element aus der Liste gelöscht wird, muss dieses zunächst gefundenen werden und
die Liste danach neu verkettete werden: O(n).
Die Methoden einer LinkedList<T> sind nicht synchronized.
Vector und Stack
-
Vector<T>:
- Ein
Vector<T> ähnelt einer ArrayList<T>
- Das Array eines Vector wird jedoch verdoppelt, wenn es vergrößert wird
- Die Methoden von
Vector<T> sind synchronized
-
Stack<T>:
- Schnittstelle: "last in first out"-Prinzip
push(T): Pushe Element oben auf den Stackpop(): T: Hole oberstes Element vom Stack
- Tatsächlich aber:
class Stack<E> extends Vector<E>
Iterierbarkeit: Iterable und Iterator
private List <Entity> entities = new ArrayList<>();
for (Entity e : entities) { ... }
entities.forEach(x -> ...);

Die Klassen aus der Collection-API implementieren das Interface Iterable<T> und sind damit
iterierbar. Man kann sie darüber in einer klassischen for-Schleife nutzen, oder mit der
Methode forEach() direkt über die Sammlung laufen.
Intern wird dabei ein passender Iterator<T> erzeugt, der die Elemente der Sammlung schrittweise
mit der Methode next() zurückgibt. Mithilfe eines Cursor merkt sich der Iterator, bei welchem
Eintrag der Datenstruktur er aktuell ist. Mit der Methode hasNext()kann geprüft werden, ob noch
ein weiteres Element über den Iterator aus der Datenstruktur verfügbar ist.
Mit remove()kann das letzte zurückgegebene Element aus der Datenstruktur entfernt werden. Diese
Methode ist im Interface als Default-Methode implementiert.
Damit kann man die Datenstrukturen auf eine von der Datenstruktur vorgegebene Weise ablaufen,
beispielsweise einen Binärbaum.
Link zu einer netten Animation
Man kann auch selbst für eigene Klassen einen passenden Iterator<T> implementieren, der zum Ablaufen
der Elemente der eigenen Klasse genutzt werden kann. Damit die eigene Klasse auch in einer for-Schleife
genutzt werden kann, muss sie aber auch noch Iterable<T> implementieren.
Hilfsklasse Collections

Collections ist eine Utility-Klasse mit statischen Methoden, die auf Collection<T>s ausgeführt werden.
Diese Methoden nutzen das Collection<T>-Interface und/oder die Iterable<T>-Schnittstelle.
Siehe auch Class Collections.
Der Hintergrund für diese in Java nicht unübliche Aufsplittung in ein Interface und eine Utility-Klasse
ist, dass bis vor kurzem Interface nur Schnittstellen definieren konnten. Erst seit einigen Java-Versionen
kann in Interfaces auch Verhalten definiert werden (Default-Methoden). Aus heutiger Sicht würde man also
vermutlich die statischen Methoden in der Klasse Collections eher direkt als Default-Methoden im Interface
Collection<T> implementieren und bereitstellen, statt eine separate Utility-Klasse zu definieren.
Map

Hinweis: Die abstrakten (Zwischen-) Klassen wurden im obigen UML aus Gründen der
Übersichtlichkeit nicht aufgeführt. Aus den selben Gründen sind auch nur ausgewählte
Methoden aufgenommen worden.
Hinweis: Blau = Interface, Grün = Klasse.
Hinweis: Tatsächlich ist der Typ des Keys in den Methoden get() und remove() mit Object
spezifiziert und nicht mit dem Typ-Parameter K. Das ist aus meiner Sicht eine Inkonsistenz in
der API.
Eine Map<K,V> speichert Objekte als Key/Value-Paar mit den Typen K (Key) und V (Value).
Dabei sind die Keys in einer Map einzigartig und werden verwendet, um auf das jeweilige Value
zuzugreifen. Ein Value kann entsprechend (mit unterschiedlichen Keys) mehrfach im einer Map
enthalten sein.
Es gibt eine Reihe verschiedener Implementierungen, die unterschiedliche Datenstrukturen
einsetzen, beispielsweise:
HashMap<K,V> hält keine Ordnung in den Einträgen. Verwendet den Hashwert, um Objekte zu
speichern. Zugriff auf Einträge in einer HashMap ist O(1).LinkedHashMap<K,V> hält die Einträge in der Reihenfolge, in der sie eingefügt wurden.TreeMap<K,V> hält die Einträge in aufsteigender Reihenfolge.
Siehe auch Interface Map.
HashMap

Eine HashMap<K,V> speichert die Elemente in mehreren einfach verketteten Listen. Dafür
verwendet sie die innere Klasse Node<K,V>.
Die Heads, die auf den Anfang einer Liste zeigen, werden in "Buckets" gespeichert. Initial
besitzt eine HashMap 12 Buckets, diese werden bei Bedarf erweitert.
Um einen Eintrag hinzufügen, wird zunächst aus dem hashCode() des Key-Objektes mithilfe der
Hash-Funktion der Index des Buckets berechnet. Ist der Bucket gefunden, wird geprüft, ob das
Objekt dort schon vorkommt: Mit dem hashCode() des Key-Objektes werden alle Objekte in der
Liste des Buckets verglichen. Wenn es Einträge mit dem selben hashCode() in der Liste gibt,
wird mit equals geprüft, ob die Key-Objekte identisch sind. Ist dies der Fall, wird der
existierende Eintrag überschrieben, anderenfalls wird der neue Eintrag an das Ende der Liste
hinzugefügt.
Implementierungsdetail: Wenn die Listen zu groß werden, wird die Hashtabelle neu angelegt mit
ungefähr der doppelten Anzahl der Einträge (Buckets) und die alten Einträge per Re-Hash neu
verteilt (vgl. Class HashMap).
HashMap<K,V> Methoden sind nicht synchronized.
HashMap<K,V> unterstützt einen null-Key. Es darf beliebig viele null-Values geben.
Die Unterklasse LinkedHashMap<K,V> kann Ordnung zwischen den Elementen halten. Dafür wird
eine doppelt verkettete Liste verwendet.
Hashtable
- Nicht zu verwechseln mit der Datenstruktur: Hash-Tabellen (!)
Hashtable<K,V> ist vergleichbar mit einer HashMap<K,V>Hashtable<K,V>-Methoden sind synchronized- Kein Key oder Value darf
null sein
Spielregeln für equals(), hashCode() und compareTo()
equals()
boolean equals(Object o) ist eine Methode Klasse Object und wird genutzt, um Objekte auf Gleichheit zu
prüfen. Die Default-Implementierung von equals() in Object vergleicht die beiden Objekte mit ==, gibt
also nur dann true zurück, wenn die beiden zu vergleichenden Objekte die selbe Objekt-ID haben.
In der Praxis kann es sich anbieten, diese Methode zu überschreiben und eigene Kriterien für Gleichheit
aufzustellen.
Dabei sind Spielregeln zu beachten (für nicht-null Objekte x, y und z):
- Reflexivität:
x.equals(x) == true
- Symmetrie:
x.equals(y) == y.equals(x)
- Transitivität: Wenn
x.equals(y) == true und y.equals(z) == true, dann auch x.equals(z) == true
- Konsistenz: Mehrfache Aufrufe von
equals() mit den selben Werten müssen immer das selbe Ergebnis liefern
x.equals(null) == false
hashCode()
Die Methode int hashCode() gibt den Hash-Wert eines Objektes zurück. Der Hash-Wert eins Objektes wird genutzt,
um dieses in einen Hash-basierten Container abzulegen bzw. zu finden.
Der Rückgabewert der Methode hashCode() für ein Objekt bleibt über die Laufzeit einer Anwendung immer identisch,
solange sich die zur Prüfung der Gleichheit genutzten Attribute nicht ändern.
compareTo()
Die Methode int compareTo() (Interface Comparable<T>) vergleicht Objekte und definiert damit eine Ordnung
auf den Objekten. Während equals() für die Prüfung auf Gleichheit eingesetzt wird, wird compareTo() für die
Sortierung von Objekten untereinander verwendet.
Spielregeln:
x.compareTo(y) < 0 wenn x "kleiner" als y istx.compareTo(y) > 0 wenn x "größer" als y istx.compareTo(y) = 0 wenn x "gleich" als y ist- Symmetrie:
signum(x.compareTo(y)) == -signum(y.compareTo(x))
- Transitivität: Wenn
x.compareTo(y) > 0 und y.compareTo(z) > 0, dann auch x.compareTo(z) > 0
- Wenn
x.compareTo(y) == 0, dann auch signum(x.compareTo(z)) == signum(y.compareTo(z))
Der equals()-hashCode()-compareTo()-Vertrag
Wird equals() überschrieben, sollte auch hashCode() (passend) überschrieben werden.
-
Wenn x.equals(y) == true, dann muss auch x.hashCode() == y.hashCode()
-
Wenn x.equals(y) == false, sollte x.hashCode() != y.hashCode() sein
(Unterschiedliche hashCode()-Werte für unterschiedliche Objekte verbessern allerdings die Leistung
von Hash-Berechnungen, etwa in einer HashMap<K,V>!)
-
Es wird sehr empfohlen, dass equals() und compareTo() konsistente Ergebnisse liefern:
x.compareTo(y) == 0 gdw. x.equals(y) == true
(Dies muss aber nicht zwingend eingehalten werden, sorgt dann aber u.U. für unerwartete Nebeneffekte
beim Umgang mit Collection<T> und Map<K,V>!)
Überblick

Komplexitätswerte beziehen sich auf den Regelfall. Sonderfälle wie das Vergrößern des Array einer
ArrayList<T> können für temporär erhöhte Komplexität sorgen (das ist dem O-Kalkül aber egal).
Wrap-Up
- Interface
Collection<T>: Schnittstelle für Datenstrukturen/Sammlungen
zur Verwaltung einer Menge von Objekten
- Klasse
Collections: Statische Hilfs-Methoden (anwendbar auf Collection<T>s)
Iterable<T> liefert einen Iterator<T> zur Iteration über eine Collection<T>- Interface
Map<K,V>: Speichern von Key/Value-Paaren
equals()-hashCode()-compareTo()-Vertrag beachten
Quellen
- [LernJava] Learn Java
Oracle Corporation, 2022.
Tutorials \> Mastering the API \> The Collections Framework
Reguläre Ausdrücke
TL;DR
Mit Hilfe von regulären Ausdrücken kann man den Aufbau von Zeichenketten formal
beschreiben. Dabei lassen sich direkt die gewünschten Zeichen einsetzen, oder
man nutzt Zeichenklassen oder vordefinierte Ausdrücke. Teilausdrücke lassen sich
gruppieren und über Quantifier kann definiert werden, wie oft ein Teilausdruck
vorkommen soll. Die Quantifier sind per Default greedy und versuchen so viel
wie möglich zu matchen.
Auf der Java-Seite stellt man reguläre Ausdrücke zunächst als String dar. Dabei
muss darauf geachtet werden, dass ein Backslash im regulären Ausdruck im Java-String
geschützt (escaped) werden muss, indem jeweils ein weiterer Backslash voran gestellt
wird. Mit Hilfe der Klasse java.util.regex.Pattern lässt sich daraus ein Objekt
mit dem kompilierten regulären Ausdruck erzeugen, was insbesondere bei mehrfacher
Verwendung günstiger in der Laufzeit ist. Dem Pattern-Objekt kann man dann den
Suchstring übergeben und bekommt ein Objekt der Klasse java.util.regex.Matcher
(dort sind regulärer Ausdruck/Pattern und der Suchstring kombiniert). Mit den
Methoden Matcher#find und Matcher#matches kann dann geprüft werden, ob das Pattern
auf den Suchstring passt: find sucht dabei nach dem ersten Vorkommen des Patterns
im Suchstring, match prüft, ob der gesamte String zum Pattern passt.
Videos (HSBI-Medienportal)
Lernziele
- (K1) Wichtigste Methoden von
java.util.regex.Pattern und java.util.regex.Matcher - (K2) Unterschied zwischen
Matcher#find und Matcher#matches - (K2) Unterscheidung zwischen greedy und non-greedy Verhalten
- (K3) Bildung einfacher regulärer Ausdrücke
- (K3) Nutzung von Zeichenklassen und deren Negation
- (K3) Nutzung der vordefinierten regulären Ausdrücke
- (K3) Nutzung von Quantifizierern
- (K3) Zusammenbauen von komplexen Ausdrücken (u.a. mit Gruppen)
Suchen in Strings
Gesucht ist ein Programm zum Extrahieren von Telefonnummern aus E-Mails.
=> Wie geht das?
Leider gibt es unzählig viele Varianten, wie man eine Telefonnummer (samt
Vorwahl und ggf. Ländervorwahl) aufschreiben kann:
030 - 123 456 789, 030-123456789, 030/123456789,
+49(30)123456-789, +49 (30) 123 456 - 789, ...
Definition Regulärer Ausdruck
Ein regulärer Ausdruck ist eine Zeichenkette, die zur Beschreibung von
Zeichenketten dient.
Anwendungen
- Finden von Bestandteilen in Zeichenketten
- Aufteilen von Strings in Tokens
- Validierung von textuellen Eingaben
=> "Eine Postleitzahl besteht aus 5 Ziffern"
- Compilerbau: Erkennen von Schlüsselwörtern und Strukturen und Syntaxfehlern
Einfachste reguläre Ausdrücke
| Zeichenkette |
Beschreibt |
x |
"x" |
. |
ein beliebiges Zeichen |
\t |
Tabulator |
\n |
Newline |
\r |
Carriage-return |
\\ |
Backslash |
Beispiel
abc => "abc"A.B => "AAB" oder "A2B" oder ...a\\bc => "a\bc"
Anmerkung
In Java-Strings leitet der Backslash eine zu interpretierende Befehlssequenz ein.
Deshalb muss der Backslash i.d.R. geschützt ("escaped") werden.
=> Statt "\n" müssen Sie im Java-Code "\\n" schreiben!
Zeichenklassen
| Zeichenkette |
Beschreibt |
[abc] |
"a" oder "b" oder "c" |
[^abc] |
alles außer "a", "b" oder "c" (Negation) |
[a-zA-Z] |
alle Zeichen von "a" bis "z" und "A" bis "Z" (Range) |
[a-z&&[def]] |
"d","e" oder "f" (Schnitt) |
[a-z&&[^bc]] |
"a" bis "z", außer "b" und "c": [ad-z] (Subtraktion) |
[a-z&&[^m-p]] |
"a" bis "z", außer "m" bis "p": [a-lq-z] (Subtraktion) |
Beispiel
[abc] => "a" oder "b" oder "c"[a-c] => "a" oder "b" oder "c"[a-c][a-c] => "aa", "ab", "ac", "ba", "bb", "bc", "ca", "cb" oder "cc"A[a-c] => "Aa", "Ab" oder "Ac"
Vordefinierte Ausdrücke
| Zeichenkette |
Beschreibt |
^ |
Zeilenanfang |
$ |
Zeilenende |
\d |
eine Ziffer: [0-9] |
\w |
beliebiges Wortzeichen: [a-zA-Z_0-9] |
\s |
Whitespace (Leerzeichen, Tabulator, Newline) |
\D |
jedes Zeichen außer Ziffern: [^0-9] |
\W |
jedes Zeichen außer Wortzeichen: [^\w] |
\S |
jedes Zeichen außer Whitespaces: [^\s] |
Beispiel
\d\d\d\d\d => "12345"\w\wA => "aaA", "a0A", "a_A", ...
Nutzung in Java
-
java.lang.String:
public String[] split(String regex)
public boolean matches(String regex)
-
java.util.regex.Pattern:
public static Pattern compile(String regex)
public Matcher matcher(CharSequence input)
- Schritt 1: Ein Pattern compilieren (erzeugen) mit
Pattern#compile
=> liefert ein Pattern-Objekt für den regulären Ausdruck zurück
- Schritt 2: Dem Pattern-Objekt den zu untersuchenden Zeichenstrom
übergeben mit
Pattern#matcher => liefert ein Matcher-Objekt
zurück, darin gebunden: Pattern (regulärer Ausdruck) und die zu
untersuchende Zeichenkette
-
java.util.regex.Matcher:
public boolean find()
public boolean matches()
public int groupCount()
public String group(int group)
-
Schritt 3: Mit dem Matcher-Objekt kann man die Ergebnisse der
Anwendung des regulären Ausdrucks auf eine Zeichenkette auswerten
Bedeutung der unterschiedlichen Methoden siehe folgende Folien
Matcher#group: Liefert die Sub-Sequenz des Suchstrings zurück, die
erfolgreich gematcht wurde (siehe unten "Fangende Gruppierungen")
Hinweis:
In Java-Strings leitet der Backslash eine zu interpretierende Befehlssequenz ein.
Deshalb muss der Backslash i.d.R. extra geschützt ("escaped") werden.
=> Statt "\n" (regulärer Ausdruck) müssen Sie im Java-String "\\n" schreiben!
=> Statt "a\\bc" (regulärer Ausdruck, passt auf die Zeichenkette "a\bc") müssen
Sie im Java-String "a\\\\bc" schreiben!
Unterschied zw. Finden und Matchen
Beispiel
- Regulärer Ausdruck:
abc, Suchstring: "blah blah abc blub"
Matcher#find: erfolgreichMatcher#matches: kein Match - Suchstring entspricht nicht dem Muster
Quantifizierung
| Zeichenkette |
Beschreibt |
X? |
ein oder kein "X" |
X* |
beliebig viele "X" (inkl. kein "X") |
X+ |
mindestens ein "X", ansonsten beliebig viele "X" |
X{n} |
exakt $n$ Vorkommen von "X" |
X{n,} |
mindestens $n$ Vorkommen von "X" |
X{n,m} |
zwischen $n$ und $m$ Vorkommen von "X" |
Beispiel
\d{5} => "12345"-?\d+\.\d* => ???
Interessante Effekte
Pattern p = Pattern.compile("A.*A");
Matcher m = p.matcher("A 12 A 45 A");
if (m.matches())
String result = m.group(); // ???
Matcher#group liefert die Inputsequenz, auf die der Matcher angesprochen hat.
Mit Matcher#start und Matcher#end kann man sich die Indizes des ersten und
letzten Zeichens des Matches im Eingabezeichenstrom geben lassen. D.h. für einen
Matcher m und eine Eingabezeichenkette s ist m.group() und
s.substring(m.start(), m.end()) äquivalent.
Da bei Matcher#matches das Pattern immer auf den gesamten Suchstring passen
muss, verwundert das Ergebnis für Matcher#group nicht. Bei Matcher#find
wird im Beispiel allerdings ebenfalls der gesamte Suchstring "gefunden" ...
Dies liegt am "greedy" Verhalten der Quantifizierer.
Nicht gierige Quantifizierung mit "?"
| Zeichenkette |
Beschreibt |
X*? |
non-greedy Variante von X* |
X+? |
non-greedy Variante von X+ |
Beispiel
- Suchstring "A 12 A 45 A":
(Fangende) Gruppierungen
Studi{2} passt nicht auf "StudiStudi" (!)
Quantifizierung bezieht sich auf das direkt davor stehende Zeichen. Ggf.
Gruppierungen durch Klammern verwenden!
| Zeichenkette |
Beschreibt |
X|Y |
X oder Y |
(C) |
Gruppierung |
Beispiel
(A)(B(C))
- Gruppe 0:
ABC
- Gruppe 1:
A
- Gruppe 2:
BC
- Gruppe 3:
C
Die Gruppen heißen auch "fangende" Gruppen (engl.: "capturing groups").
Damit erreicht man eine Segmentierung des gesamten regulären Ausdrucks, der
in seiner Wirkung aber nicht durch die Gruppierungen geändert wird. Durch die
Gruppierungen von Teilen des regulären Ausdrucks erhält man die Möglichkeit,
auf die entsprechenden Teil-Matches (der Unterausdrücke der einzelnen Gruppen)
zuzugreifen:
-
Matcher#groupCount: Anzahl der "fangenden" Gruppen im regulären Ausdruck
-
Matcher#group(i): Liefert die Subsequenz der Eingabezeichenkette zurück,
auf die die jeweilige Gruppe gepasst hat. Dabei wird von links nach rechts
durchgezählt, beginnend bei 1(!).
Konvention: Gruppe 0 ist das gesamte Pattern, d.h. m.group(0) == m.group(); ...
Hinweis: Damit der Zugriff auf die Gruppen klappt, muss auch erst ein Match gemacht
werden, d.h. das Erzeugen des Matcher-Objekts reicht noch nicht, sondern es muss auch
noch ein matcher.find() oder matcher.matches() ausgeführt werden. Danach kann man
bei Vorliegen eines Matches auf die Gruppen zugreifen.
(Studi){2} => "StudiStudi"
Gruppen und Backreferences
Matche zwei Ziffern, gefolgt von den selben zwei Ziffern
-
Verweis auf bereits gematchte Gruppen: \num
num Nummer der Gruppe (1 ... 9)
=> Verweist nicht auf regulären Ausdruck, sondern auf jeweiligen Match!
Anmerkung: Laut Literatur/Doku nur 1 ... 9, in Praxis geht auch mehr per Backreference ...
-
Benennung der Gruppe: (?<name>X)
X ist regulärer Ausdruck für Gruppe, spitze Klammern wichtig
=> Backreference: \k<name>
Beispiel Gruppen und Backreferences
Regulärer Ausdruck: Namen einer Person matchen, wenn Vor- und Nachname identisch sind.
Lösung: ([A-Z][a-zA-Z]*)\s\1
Umlaute und reguläre Ausdrücke
-
Keine vordefinierte Abkürzung für Umlaute (wie etwa \d)
-
Umlaute nicht in [a-z] enthalten, aber in [a-ü]
"helloüA".matches(".*?[ü]A");
"azäöüß".matches("[a-ä]");
"azäöüß".matches("[a-ö]");
"azäöüß".matches("[a-ü]");
"azäöüß".matches("[a-ß]");
-
Strings sind Unicode-Zeichenketten
=> Nutzung der passenden Unicode Escape Sequence \uFFFF
System.out.println("\u0041 :: A");
System.out.println("helloüA".matches(".*?A"));
System.out.println("helloüA".matches(".*?\u0041"));
System.out.println("helloü\u0041".matches(".*?A"));
-
RegExp vordefinieren und mit Variablen zusammenbauen ala Perl
nicht möglich => Umweg String-Repräsentation
Wrap-Up
- RegExp: Zeichenketten, die andere Zeichenketten beschreiben
java.util.regex.Pattern und java.util.regex.Matcher- Unterschied zwischen
Matcher#find und Matcher#matches!
- Quantifizierung ist möglich, aber greedy (Default)
Challenges
In den Vorgaben
finden Sie in der Klasse Lexer eine einfache Implementierung
eines Lexers, worin ein einfaches
Syntax-Highlighting für Java-Code realisiert ist.
Dazu arbeitet der Lexer mit sogenannten "Token" (Instanzen der Klasse Token).
Diese haben einen regulären Ausdruck, um bestimmte Teile im Code zu erkennen,
beispielsweise Keywords oder Kommentare und anderes. Der Lexer wendet alle Token
auf den aktuellen Eingabezeichenstrom an (Methode Token#test()), und die Token
prüfen mit "ihrem" regulären Ausdruck, ob die jeweils passende Eingabesequenz
vorliegt. Die regulären Ausdrücke übergeben Sie dem Token-Konstruktor als
entsprechendes Pattern-Objekt.
Neben dem jeweiligen Pattern kennt jedes Token noch eine matchingGroup: Dies
ist ein Integer, der die relevante Matching-Group im regulären Ausdruck bezeichnet.
Wenn Sie keine eigenen Gruppen in einem regulären Ausdruck eingebaut haben, nutzen
Sie hier einfach den Wert 0.
Zusätzlich kennt jedes Token noch die Farbe für das Syntax-Highlighting in der
von uns als Vorgabe realisierten Swing-GUI (Instanz von Color).
Erstellen Sie passende Token-Instanzen mit entsprechenden Pattern für die
folgenden Token:
- Einzeiliger Kommentar: beginnend mit
// bis zum Zeilenende
- Mehrzeiliger Kommentar: alles zwischen
/* und dem nächsten */
- Javadoc-Kommentar: alles zwischen
/** und dem nächsten */
- Strings: alles zwischen
" und dem nächsten "
- Character: genau ein Zeichen zwischen
' und '
- Keywords:
package, import, class, public, private, final,
return, null, new (jeweils freistehend, also nicht "newx" o.ä.)
- Annotation: beginnt mit
@, enthält Buchstaben oder Minuszeichen
Die Token-Objekte fügen Sie im Konstruktor der Klasse Lexer durch den
Aufruf der Methode tokenizer.add(mytoken) hinzu. Sie können Sich an den
Kommentaren im Lexer-Konstruktor orientieren.
Sollten Token ineinander geschachtelt sein, erkennt der Lexer dies automatisch.
Sie brauchen sich keine Gedanken dazu machen, in welcher Reihenfolge die Token
eingefügt und abgearbeitet werden. Beispiel: Im regulären Ausdruck für den
einzeiligen Kommentar brauchen Sie keine Keywords, Annotationen, Strings usw.
erkennen.
Quellen
- [Java-SE-Tutorial] The Java Tutorials
Oracle Corporation, 2022.
Essential Java Classes \> Regular Expressions
Annotationen
TL;DR
Annotationen sind Metadaten zum Programm: Sie haben keinen (direkten) Einfluss auf die
Ausführung des annotierten Codes, sondern enthalten Zusatzinformationen über ein Programm,
die selbst nicht Teil des Programms sind. Verschiedene Tools werten Annotationen aus,
beispielsweise der Compiler, Javadoc, JUnit, ...
Annotationen können auf Deklarationen (Klassen, Felder, Methoden) angewendet werden und
werden meist auf eine eigene Zeile geschrieben (Konvention).
Annotationen können relativ einfach selbst erstellt werden: Die Definition ist fast wie
bei einem Interface. Zusätzlich kann man noch über Meta-Annotationen die Sichtbarkeit,
Verwendbarkeit und Dokumentation einschränken. Annotationen können zur Übersetzungszeit
mit einem Annotation-Processor verarbeitet werden oder zur Laufzeit über Reflection
ausgewertet werden.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Begriff der Annotation erklären können am Beispiel
- (K3) Anwendung von
@Override sowie der Javadoc-Annotationen - (K3) Erstellen eigener Annotationen sowie Einstellen der Sichtbarkeit und Verwendbarkeit
- (K3) Erstellen eigener einfacher Annotation-Processors
Was passiert hier?
public class A {
public String getInfo() { return "Klasse A"; }
}
public class B extends A {
public String getInfo(String s) { return s + "Klasse B"; }
public static void main(String[] args) {
B s = new B();
System.out.println(s.getInfo("Info: "));
}
}
Hilft @Override?
Tja, da sollte wohl die Methode B#getInfo die geerbte Methode A#getInfo
überschreiben. Dummerweise wird hier die Methode aber nur überladen
(mit entsprechenden Folgen beim Aufruf)!
Ein leider relativ häufiges Versehen, welches u.U. schwer zu finden ist.
Annotationen (hier @Override) können dagegen helfen - der Compiler "weiß"
dann, dass wir überschreiben wollen und meckert, wenn wir das nicht tun.
IDEs wie Eclipse können diese Annotation bereits beim Erstellen einer Klasse
generieren: Preferences > Java > Code Style > Add @Override annotation ....
-
Zusatzinformationen für Tools, Bibliotheken, ...
-
Kein direkter Einfluss auf die Ausführung des annotierten Codes
-
Beispiele:
- Compiler (JDK):
@Override, @Deprecated, ...
- Javadoc:
@author, @version, @see, @param, @return, ...
- JUnit:
@Test, @Before, @BeforeClass, @After, @AfterClass
- IntelliJ:
@NotNull, @Nullable
- Checker Framework:
@NonNull, @Nullable, ...
- Project Lombok:
@Getter, @Setter, @NonNull, ...
- Webservices:
@WebService, @WebMethod
- ...
Jetzt schauen wir uns erst einmal die Auswirkungen von @Override und @Deprecated
auf den Compiler (via Eclipse) an.
Anschließend lernen Sie die Dokumentation mittels Javadoc-Annotationen kennen.
Das Thema JUnit ist in einer anderen VL dran. Webservices ereilen Sie dann in
späteren Semestern :-)
@Override
Die mit @Override annotierte Methode überschreibt eine Methode aus der Oberklasse oder implementiert eine
Methode einer Schnittstelle. Dies wird durch den Compiler geprüft und ggf. mit einer Fehlermeldung quittiert.
@Override ist eine im JDK im Paket java.lang enthaltene Annotation.
@Deprecated
Das mit @Deprecated markierte Element ist veraltet ("deprecated") und sollte nicht mehr benutzt werden.
Typischerweise werden so markierte Elemente in zukünftigen Releases aus der API entfernt ...
Die Annotation @Deprecated wird direkt im Code verwendet und entspricht der Annotation @deprecated
im Javadoc. Allerdings kann letzteres nur von Javadoc ausgewertet werden.
@Deprecated ist eine im JDK im Paket java.lang enthaltene Annotation.
Weitere Annotationen aus java.lang
Im Paket java.lang finden sich weitere Annotationen. Mit Hilfe von @SuppressWarnings lassen sich bestimmte
Compilerwarnungen unterdrücken (so etwas sollte man NIE tun!), und mit @FunctionalInterface
lassen sich Schnittstellen auszeichnen, die genau eine (abstrakte) Methode besitzen (Verweis auf spätere Vorlesung).
Weitere Annotationen aus dem JDK finden sich in den Paketen java.lang.annotation und javax.annotation.
Dokumentation mit Javadoc
/**
* Beschreibung Beschreibung Beschreibung
*
* @param date Tag, Wert zw. 1 .. 31
* @return true, falls Datum gesetzt wurde; false sonst
* @see java.util.Calendar
* @deprecated As of JDK version 1.1
*/
public boolean setDate(int date) {
setField(Calendar.DATE, date);
}
Die Dokumentation mit Javadoc hatten wir uns bereits in der Einheit
“Javadoc” angesehen.
Hier noch einmal exemplarisch die wichtigsten Elemente, die an
"public" sichtbaren Methoden verwendet werden.
@NotNull mit IntelliJ
IntelliJ bietet im Paket
org.jetbrains.annotations u.a. die Annotation @NotNull an.
Damit lassen sich Rückgabewerte von Methoden sowie Variablen (Attribute, lokale Variablen, Parameter) markieren:
Diese dürfen nicht null werden.
IntelliJ prüft beim Compilieren, dass diese Elemente nicht null werden und warnt gegebenenfalls (zur Compilezeit).
Zusätzlich baut IntelliJ entsprechende Assertions in den Code ein, die zur Laufzeit einen null-Wert abfangen
und dann das Programm abbrechen.
Dadurch können entsprechende Dokumentationen im Javadoc und/oder manuelle Überprüfungen im Code entfallen.
Außerdem hat man durch die Annotation gewissermaßen einen sichtbaren Vertrag (Contract) mit den Nutzern
der Methode. Bei einem Aufruf mit null würde dieser Contract verletzt und eine entsprechende Exception
geworfen (automatisch) statt einfach das Programm und die JVM "abzuschießen".
Nachteil: Die entsprechende Bibliothek muss bei allen Entwicklern vorhanden und in das Projekt eingebunden
sein.
/* o should not be null */
public void bar(Object o) {
int i;
if (o != null) {
i = o.hashCode();
}
}
/* o must not be null */
public void foo(@NotNull Object o) {
// assert(o != null); // Wirkung (von IntelliJ eingefügt)
int i = o.hashCode();
}
IntelliJ inferiert mit @NotNull mögliche null-Werte

IntelliJ baut bei @NotNull passende Assertions ein

Eigene Annotationen erstellen
public @interface MyFirstAnnotation {}
public @interface MyThirdAnnotation {
String author();
int vl() default 1;
}
@MyFirstAnnotation
@MyThirdAnnotation(author = "Carsten Gips", vl = 3)
public class C {}
Definition einer Annotation
Definition einer Annotation wie Interface, aber mit "@"-Zeichen vor dem interface-Schlüsselwort
Parameter für Annotation
Parameter für Annotation werden über entsprechende Methoden-Deklaration realisiert
-
"Rückgabetyp" der deklarierten "Methode" ist der erlaubte Typ der später
verwendeten Parameter
-
Name der "Methoden" wird bei der Belegung der Parameter verwendet,
beispielsweise author = ...
-
Vereinfachung: "Methodenname" value erlaubt das Weglassen des
Schlüsselworts bei der Verwendung:
public @interface MySecondAnnotation {
String value();
}
@MySecondAnnotation("wuppie")
public class D {}
@MySecondAnnotation(value = "wuppie")
public class E {}
-
Defaultwerte mit dem nachgestellten Schlüsselwort default sowie dem
Defaultwert selbst
Javadoc
Soll die Annotation in der Javadoc-Doku dargestellt werden, muss sie mit
der Meta-Annotation @Documented ausgezeichnet werden (aus
java.lang.annotation.Documented)
Hinweis: Die Annotation wird lediglich in die Doku aufgenommen, d.h. es
erfolgt keine weitere Verarbeitung oder Hervorhebung o.ä.
Wann ist eine Annotation sichtbar (Beschränkung der Sichtbarkeit)
Annotationen werden vom Compiler und/oder anderen Tools ausgewertet. Man
kann entsprechend die Sichtbarkeit einer Annotation beschränken: Sie kann
ausschließlich im Source-Code verfügbar sein, sie kann in der generierten
Class-Datei eingebettet sein oder sie kann sogar zur Laufzeit (mittels
Reflection, vgl. spätere Vorlesung) ausgelesen werden.
Beschränkung der Sichtbarkeit: Meta-Annotation @Retention aus
java.lang.annotation.Retention
RetentionPolicy.SOURCE: Nur Bestandteil der Source-Dateien, wird nicht
in kompilierten Code eingebettetRetentionPolicy.CLASS: Wird vom Compiler in die Class-Datei eingebettet,
steht aber zur Laufzeit nicht zur Verfügung (Standardwert, wenn nichts
angegeben)RetentionPolicy.RUNTIME: Wird vom Compiler in die Class-Datei
eingebettet und steht zur Laufzeit zur Verfügung und kann via
Reflection ausgelesen
werden
Ohne explizite Angabe gilt für die selbst definierte Annotation die
Einstellung RetentionPolicy.CLASS.
Wo darf eine Annotation verwendet werden
Anwendungsmöglichkeiten von Annotationen im Code
@ClassAnnotation
public class Wuppie {
@InstanceFieldAnnotation
private String foo;
@ConstructorAnnotation
public Wuppie() {}
@MethodAnnotation1
@MethodAnnotation2
@MethodAnnotation3
public void fluppie(@ParameterAnnotation final Object arg1) {
@VariableAnnotation
final String bar = (@TypeAnnotation String) arg1;
}
}
Einschränkung des Einsatzes eines Annotation
Für jede Annotation kann eingeschränkt werden, wo (an welchen Java-Elementen)
sie verwendet werden darf.
Beschränkung der Verwendung: Meta-Annotation @Target aus
java.lang.annotation.Target
ElementType.TYPE: alle Typdeklarationen: Klassen, Interfaces, Enumerations, ...ElementType.CONSTRUCTOR: nur KonstruktorenElementType.METHOD: nur MethodenElementType.FIELD: nur statische Variablen und ObjektvariablenElementType.PARAMETER: nur ParametervariablenElementType.PACKAGE: nur an Package-Deklarationen
Ohne explizite Angabe ist die selbst definierte Annotation für alle
Elemente verwendbar.
Annotationen bei Compilieren bearbeiten: Java Annotation-Prozessoren
Der dem javac-Compiler vorgelegte Source-Code wird eingelesen und in einen
entsprechenden Syntax-Tree (AST) transformiert (dazu mehr im Master im Modul
"Compilerbau" :)
Anschließend können sogenannte "Annotation Processors" über den AST laufen und
ihre Analysen machen und/oder den AST modifizieren. (Danach kommen die üblichen
weiteren Analysen und die Code-Generierung.)
(Vgl. OpenJDK: Compilation Overview.)
An dieser Stelle kann man sich einklinken und einen eigenen Annotation-Prozessor
ausführen lassen. Zur Abgrenzung: Diese Auswertung der Annotationen findet zur
Compile-Zeit statt! In einer späteren Vorlesung werden wir noch über die
Auswertung zur Laufzeit sprechen: Reflection.
Im Prinzip muss man lediglich das Interface javax.annotation.processing.Processor
implementieren oder die abstrakte Klasse javax.annotation.processing.AbstractProcessor
erweitern. Für die Registrierung im javac muss im Projekt (oder Jar-File) die
Datei META-INF/services/javax.annotation.processing.Processor angelegt werden,
die den vollständigen Namen des Annotation-Prozessors enthält. Dieser Annotation-Prozessor
wird dann vom javac aufgerufen und läuft in einer eigenen JVM. Er kann die
Annotationen, für die er registriert ist, auslesen und verarbeiten und neue Java-Dateien
schreiben, die wiederum eingelesen und compiliert werden.
Im nachfolgenden Beispiel beschränke ich mich auf das Definieren und Registrieren
eines einfachen Annotation-Prozessors, der lediglich die Annotationen liest.
@SupportedAnnotationTypes("annotations.MySecondAnnotation")
@SupportedSourceVersion(SourceVersion.RELEASE_17)
public class Foo extends AbstractProcessor {
@Override
public boolean process(Set<? extends TypeElement> as, RoundEnvironment re) {
for (TypeElement annot : as) {
for (Element el : re.getElementsAnnotatedWith(annot)) {
processingEnv.getMessager().printMessage(Diagnostic.Kind.NOTE,
"found @MySecondAnnotation at " + el);
}
}
return true;
}
}
- Der Annotation-Processor sollte von
AbstractProcessor ableiten
- Über
@SupportedAnnotationTypes teilt man mit, für welche Annotationen sich der Prozessor interessiert
(d.h. für welche er aufgerufen wird); "*" oder eine Liste mit String ist auch möglich
- Mit
@SupportedSourceVersion wird die (höchste) unterstützte Java-Version angegeben
(neuere Versionen führen zu einer Warnung)
- Die Methode
process erledigt die Arbeit:
- Der erste Parameter enthält alle gefundenen Annotationen, für die der Processor registriert ist
- Der zweite Parameter enthält die damit annotierten Elemente
- Iteration: Die äußere Schleife läuft über alle gefundenen Annotationen, die innere über die
mit der jeweiligen Annotation versehenen Elemente
- Jetzt könnte man mit den Elementen etwas sinnvolles anfangen, beispielsweise alle Attribute
sammeln, die mit
@Getter markiert sind und für diese neuen Code generieren
- Im Beispiel wird lediglich der eigene Logger (
processingEnv.getMessager()) aufgerufen,
um beim Compiliervorgang eine Konsolenmeldung zu erzeugen ...
- Der Annotation-Processor darf keine Exception werfen, da sonst der Compiliervorgang abgebrochen
würde. Zudem wäre der Stack-Trace der des Annotation-Processors und nicht der des compilierten
Programms ... Stattdessen wird ein Boolean zurückgeliefert, um anzudeuten, ob die Verarbeitung
geklappt hat.
Für ein umfangreicheres Beispiel mit Code-Erzeugung vergleiche beispielsweise die Artikelserie unter
cloudogu.com/en/blog/Java-Annotation-Processors_1-Intro.
Siehe auch OpenJDK: Compilation Overview.
Im Projekt muss jetzt noch der Ordner META-INF/services/ angelegt werden mit der Datei
javax.annotation.processing.Processor. Deren Inhalt ist für das obige Beispiel die Zeile
annotations.Foo. Damit ist der Annotation-Processor annotations.Foo für das Übersetzen im eigenen
Projekt registriert.
Zum Compilieren des Annotation-Processors selbst ruft man beispielsweise folgenden Befehl auf:
javac -cp . -proc:none annotations/Foo.java
Die Option -proc:none sorgt für das Beispiel dafür, dass beim Compilieren des Annotation-Processors
dieser nicht bereits aufgerufen wird (was sonst wg. der Registrierung über
META-INF/services/javax.annotation.processing.Processor passieren würde).
Zum Compilieren der Klasse C kann man wie sonst auch den Befehl nutzen:
javac -cp . annotations/C.java
Dabei läuft dann der Annotation-Processor annotations.Foo und erzeugt beim Verarbeiten von annotations.C
die folgende Ausgabe:
Note: found @MySecondAnnotation at main(java.lang.String[])
Wrap-Up
-
Annotationen: Metadaten zum Programm
- Zusatzinformationen über ein Programm, aber nicht selbst Teil des Programms
- Kein (direkter) Einfluss auf die Ausführung des annotierten Codes
-
Typische Anwendungen: Compiler-Hinweise, Javadoc, Tests
- Compiler: Erkennen von logischen Fehlern, Unterdrücken von
Warnungen =>
java.lang: @Override,
@Deprecated, @SuppressWarnings
- Javadoc: Erkennen von Schlüsselwörtern (
@author, @return, @param, ...)
- JUnit: Erkennen von Tests-Methoden (
@Test)
- ...
-
Annotationen können auf Deklarationen (Klassen, Felder, Methoden) angewendet werden
-
Annotationen können relativ einfach selbst erstellt werden
- Definition fast wie ein Interface
- Einstellung der Sichtbarkeit und Verwendbarkeit und Dokumentation
über Meta-Annotationen
-
Verarbeitung von Annotationen zur Compilier-Zeit mit Annotation-Processor
-
Verarbeitung von Annotationen zur Laufzeit mit Reflection (siehe spätere VL)
Challenges
Schreiben Sie drei eigene Annotationen:
@MeineKlasse darf nur an Klassendefinitionen stehen und speichert den Namen des Autoren ab.@MeineMethode darf nur an Methoden stehen.@TODO darf an Methoden und Klassen stehen, ist aber nur in den Source-Dateien sichtbar.
Implementieren Sie einen Annotation-Prozessor, welcher Ihren Quellcode nach der @MeineKlasse-Annotation
durchsucht und dann den Namen der Klasse und den Namen des Autors ausgibt.
Zeigen Sie die Funktionen anhand einer Demo.
Reflection
TL;DR
Mit Hilfe der Reflection-API kann man Programme zur Laufzeit inspizieren
und Eigenschaften von Elementen wie Klassen oder Methoden abfragen, aber auch
Klassen instantiieren und Methoden aufrufen, die eigentlich auf private
gesetzt sind oder die beispielsweise mit einer bestimmten Annotation markiert
sind.
Die Laufzeitumgebung erzeugt zu jedem Typ ein Objekt der Klasse
java.lang.Class. Über dieses Class-Objekt einer Klasse können dann Informationen
über diese Klasse abgerufen werden, beispielsweise welche Konstruktoren,
Methoden und Attribute es gibt.
Man kann über auch Klassen zur Laufzeit nachladen, die zur Compile-Zeit nicht
bekannt waren. Dies bietet sich beispielsweise für User-definierte Plugins an.
Reflection ist ein mächtiges Werkzeug. Durch das Arbeiten mit Strings und die
Interaktion/Inspektion zur Laufzeit verliert man aber viele Prüfungen, die
der Compiler normalerweise zur Compile-Zeit vornimmt. Auch das Refactoring wird
dadurch eher schwierig.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Probleme beim Einsatz von Reflection
- (K2) Bedeutung der verschiedenen Exceptions beim Aufruf von Methoden per Reflection
- (K3) Inspection von Klassen zur Laufzeit mit Reflection
- (K3) Einbindung von zur Compilezeit unbekannten Klassen, Aufruf von Konstruktoren und Methoden (mit und ohne Parameter/Rückgabewerte)
Ausgaben und Einblicke zur Laufzeit
public class FactoryBeispielTest {
@Test
public void testGetTicket() {
fail("not implemented");
}
}
@Target(value = ElementType.METHOD)
@Retention(value = RetentionPolicy.RUNTIME)
public @interface Wuppie {}
Reflection wird allgemein genutzt, um zur Laufzeit von Programmen
Informationen über Klassen/Methoden/... zu bestimmen. Man könnte
damit auch das Verhalten der laufenden Programme ändern oder Typen
instantiieren und/oder Methoden aufrufen ...
Wenn Sie nicht (mehr) wissen, wie man eigene Annotationen definiert,
schauen Sie doch bitte einfach kurz im Handout zu Annotationen nach :-)
java.lang.Class: Metadaten über Klassen
// usual way of life
Studi heiner = new Studi();
heiner.hello();
// let's use reflection
try {
Object eve = Studi.class.getDeclaredConstructor().newInstance();
Method m = Studi.class.getDeclaredMethod("hello");
m.invoke(eve);
} catch (ReflectiveOperationException ignored) {}
Für jeden Typ instantiiert die JVM eine nicht veränderbare Instanz
der Klasse java.lang.Class, über die Informationen zu dem Typ
abgefragt werden können.
Dies umfasst u.a.:
- Klassenname
- Implementierte Interfaces
- Methoden
- Attribute
- Annotationen
- ...
java.lang.Class bildet damit den Einstiegspunkt in die Reflection.
Vorgehen
-
Gewünschte Klasse über ein Class-Objekt laden
-
Informationen abrufen (welche Methoden, welche Annotationen, ...)
-
Eine Instanz dieser Klasse erzeugen, und
-
Methoden aufrufen
Das Vorgehen umfasst vier Schritte: Zunächst die gewünschte Klasse über ein Class-Objekt laden
und anschließend Informationen abrufen (etwa welche Methoden vorhanden sind, welche Annotationen
annotiert wurden, ...) und bei Bedarf eine Instanz dieser Klasse erzeugen sowie Methoden aufrufen.
Ein zweiter wichtiger Anwendungsfall (neben dem Abfragen von Informationen und Aufrufen von Methoden)
ist das Laden von Klassen, die zur Compile-Zeit nicht mit dem eigentlichen Programm verbunden sind.
Auf diesem Weg kann beispielsweise ein Bildbearbeitungsprogramm zur Laufzeit dynamisch Filter aus einem
externen Ordner laden und nutzen, oder der Lexer kann die Tokendefinitionen zur Laufzeit einlesen (d.h.
er könnte mit unterschiedlichen Tokensätzen arbeiten, die zur Compile-Zeit noch gar nicht definiert sind).
Damit werden die Programme dynamischer.
Schritt 1: Class-Objekt erzeugen und Klasse laden
// Variante 1 (package.MyClass dynamisch zur Laufzeit laden)
Class<?> c = Class.forName("package.MyClass");
// Variante 2 (Objekt)
MyClass obj = new MyClass();
Class<?> c = obj.getClass();
// Variante 3 (Klasse)
Class<?> c = MyClass.class;
=> Einstiegspunkt der Reflection API
Eigentlich wird nur in Variante 1 die über den String angegebene Klasse
dynamisch von der Laufzeitumgebung (nach-) geladen (muss also im gestarteten
Programm nicht vorhanden sein). Die angegebene Klasse muss aber in Form von
Byte-Code an der angegebenen Stelle (Ordner package, Dateiname MyClass.class)
vorhanden sein.
Die anderen beiden Varianten setzen voraus, dass die jeweilige Klasse bereits
geladen ist (also ganz normal mit den restlichen Sourcen zu Byte-Code
(.class-Dateien) kompiliert wurde und mit dem Programm geladen wurde).
Alle drei Varianten ermöglichen die Introspektion der jeweiligen Klassen zur
Laufzeit.
Schritt 2: In die Klasse reinschauen
// Studi-Klasse dynamisch (nach-) laden
Class<?> c = Class.forName("reflection.Studi");
// Parametersatz für Methode zusammenbasteln
Class<?>[] paramT = new Class<?>[] { String.class };
// public Methode aus dem **Class**-Objekt holen
Method pubMethod = c.getMethod("setName", paramT);
// beliebige Methode aus dem **Class**-Objekt holen
Method privMethod = c.getDeclaredMethod("setName", paramT);
Method[] publicMethods = c.getMethods(); // all public methods (incl. inherited)
Method[] allMethods = c.getDeclaredMethods(); // all methods (excl. inherited)
public Methode laden (auch von Superklasse/Interface geerbt): Class<?>.getMethod(String, Class<?>[])- Beliebige (auch
private) Methoden (in der Klasse selbst deklariert): Class<?>.getDeclaredMethod(...)
Anmerkung: Mit Class<?>.getDeclaredMethods() erhalten Sie alle Methoden,
die direkt in der Klasse deklariert werden (ohne geerbte Methoden!), unabhängig
von deren Sichtbarkeit. Mit Class<?>.getMethods() erhalten Sie dagegen alle
public Methoden, die in der Klasse selbst oder ihren Superklassen bzw. den
implementierten Interfaces deklariert sind.
Vgl. Javadoc getMethods
und getDeclaredMethods.
Die Methoden-Arrays können Sie nach bestimmten Eigenschaften durchsuchen, bzw. auf
das Vorhandensein einer bestimmten Annotation prüfen (etwa mit isAnnotationPresent())
etc.
Analog können Sie weitere Eigenschaften einer Klasse abfragen, beispielsweise Attribute
(Class<?>.getDeclaredFields()) oder Konstruktoren (Class<?>.getDeclaredConstructors()).
Schritt 3: Instanz der geladenen Klasse erzeugen
// Class-Objekt erzeugen
Class<?> c = Class.forName("reflection.Studi");
// Variante 1
Studi s = (Studi) c.newInstance();
// Variante 2
Constructor<?> ctor = c.getConstructor();
Studi s = (Studi) ctor.newInstance();
// Variante 3
Class<?>[] paramT = new Class<?>[] {String.class, int.class};
Constructor<?> ctor = c.getDeclaredConstructor(paramT);
Studi s = (Studi) ctor.newInstance("Beate", 42);
Parameterlose, öffentliche Konstruktoren:
Class<?>.newInstance() (seit Java9 deprecated!)Class<?>.getConstructor() => Constructor<?>.newInstance()
Sonstige Konstruktoren:
Passenden Konstruktor explizit holen: Class<?>.getDeclaredConstructor(Class<?>[]),
Parametersatz zusammenbasteln (hier nicht dargestellt)
und aufrufen Constructor<?>.newInstance(...)
Unterschied new und Constructor.newInstance():
new ist nicht identisch zu Constructor.newInstance(): new
kann Dinge wie Typ-Prüfung oder Auto-Boxing mit erledigen, während
man dies bei Constructor.newInstance() selbst explizit angeben
oder erledigen muss.
Vgl. docs.oracle.com/javase/tutorial/reflect/member/ctorTrouble.html.
Schritt 4: Methoden aufrufen ...
// Studi-Klasse dynamisch (nach-) laden
Class<?> c = Class.forName("reflection.Studi");
// Studi-Objekt anlegen (Defaultkonstruktor)
Studi s = (Studi) c.newInstance();
// Parametersatz für Methode zusammenbasteln
Class<?>[] paramT = new Class<?>[] { String.class };
// Methode aus dem **Class**-Objekt holen
Method method = c.getMethod("setName", paramT);
// Methode auf dem **Studi**-Objekt aufrufen
method.invoke(s, "Holgi");
Die Reflection-API bietet neben dem reinen Zugriff auf (alle) Methoden noch viele
weitere Möglichkeiten. Beispielsweise können Sie bei einer Methode nach der Anzahl
der Parameter und deren Typ und Annotationen fragen etc. ... Schauen Sie am besten
einmal selbst in die API hinein.
Hinweis: Klassen außerhalb des Classpath laden
File folder = new File("irgendwo");
URL[] ua = new URL[]{folder.toURI().toURL()};
URLClassLoader ucl = URLClassLoader.newInstance(ua);
Class<?> c1 = Class.forName("org.wuppie.Fluppie", true, ucl);
Class<?> c2 = ucl.loadClass("org.wuppie.Fluppie");
Mit Class.forName("reflection.Studi") können Sie die Klasse Studi im
Package reflection laden. Dabei muss sich aber die entsprechende
.class-Datei (samt der der Package-Struktur entsprechenden Ordnerstruktur
darüber) im Java-Classpath befinden!
Mit einem weiteren ClassLoader können Sie auch aus Ordnern, die sich
nicht im Classpath befinden, .class-Dateien laden. Dies geht dann entweder
wie vorher über Class.forName(), wobei hier der neue Class-Loader als
Parameter mitgegeben wird, oder direkt über den neuen Class-Loader mit
dessen Methode loadClass().
Licht und Schatten
Nützlich:
- Erweiterbarkeit: Laden von "externen" (zur Kompilierzeit unbekannter)
Klassen in eine Anwendung
- Klassen-Browser, Debugger und Test-Tools
Nachteile:
- Verlust von Kapselung, Compiler-Unterstützung und Refactoring
- Performance: Dynamisches Laden von Klassen etc.
- Sicherheitsprobleme/-restriktionen
Reflection ist ein nützliches Werkzeug. Aber: Gibt es eine Lösung ohne Reflection, wähle diese!
Wrap-Up
- Inspektion von Programmen zur Laufzeit: Reflection
java.lang.Class: Metadaten über Klassen- Je Klasse ein
Class-Objekt
- Informationen über Konstruktoren, Methoden, Felder
- Anwendung: Laden und Ausführen von zur Compile-Zeit unbekanntem Code
- Vorsicht: Verlust von Refactoring und Compiler-Zusicherungen!
Challenges
In den Vorgaben
finden Sie eine einfache Implementierung für einen Taschenrechner mit Java-Swing.
Dieser Taschenrechner kann nur mit int-Werten rechnen.
Der Taschenrechner verfügt über keinerlei vordefinierte mathematische Operationen (Addieren, Subtrahieren etc.).
Erstellen Sie eigene mathematische Operationen, die IOperation implementieren. Jede Ihrer Klassen soll mit einer Annotation vermerkt werden, in welcher der Name der jeweiligen Operation gespeichert wird.
Der Taschenrechner lädt seine Operationen dynamisch über die statische Methode OperationLoader.loadOperations ein.
In den Vorgaben ist diese Methode noch nicht ausimplementiert. Implementieren Sie die Funktion so, dass sie mit Hilfe von Reflection Ihre Operationen einliest. Geben Sie dazu den Ordner an, in dem die entsprechenden .class-Dateien liegen. (Dieser Ordner soll sich außerhalb Ihres Java-Projekts befinden!)
Verändern Sie nicht die Signatur der Methode.
Ihre Operation-Klassen dürfen Sie nicht vorher bekannt machen. Diese müssen in einem vom aktuellen Projekt separierten Ordner/Projekt liegen.
Quellen
- [Inden2013] Der Weg zum Java-Profi
Inden, M., dpunkt.verlag, 2013. ISBN 978-3-8649-1245-0.
Reflection: Kapitel 8 - [Java-SE-Tutorial] The Java Tutorials
Oracle Corporation, 2022.
Specialized Trails and Lessons \> The Reflection API
Exception-Handling
TL;DR
Man unterscheidet in Java zwischen Exceptions und Errors. Ein Error ist ein
Fehler im System (OS, JVM), von dem man sich nicht wieder erholen kann. Eine Exception
ist ein Fehlerfall innerhalb des Programmes, auf den man innerhalb des Programms
reagieren kann.
Mit Hilfe von Exceptions lassen sich Fehlerfälle im Programmablauf deklarieren und
behandeln. Methoden können/müssen mit dem Keyword throws gefolgt vom Namen der
Exception deklarieren, dass sie im Fehlerfall diese spezifische Exception werfen
(und nicht selbst behandeln).
Zum Exception-Handling werden die Keywords try, catch und finally verwendet.
Dabei wird im try-Block der Code geschrieben, der einen potenziellen Fehler wirft.
Im catch-Block wird das Verhalten implementiert, dass im Fehlerfall ausgeführt
werden soll, und im finally-Block kann optional Code geschrieben werden, der sowohl
im Erfolgs- als auch Fehlerfall ausgeführt wird.
Es wird zwischen checked Exceptions und unchecked Exceptions unterschieden.
Checked Exceptions sind für erwartbare Fehlerfälle gedacht, die nicht vom Programm
ausgeschlossen werden können, wie das Fehlen einer Datei, die eingelesen werden soll.
Checked Exceptions müssen deklariert oder behandelt werden. Dies wird vom Compiler
überprüft.
Unchecked Exceptions werden für Fehler in der Programmlogik verwendet, etwa das Teilen
durch 0 oder Index-Fehler. Sie deuten auf fehlerhafte Programmierung, fehlerhafte Logik
oder beispielsweise mangelhafte Eingabeprüfung in. Unchecked Exceptions müssen nicht
deklariert oder behandelt werden. Unchecked Exceptions leiten von RuntimeException
ab.
Als Faustregel gilt: Wenn der Aufrufer sich von einer Exception-Situation erholen kann,
sollte man eine checked Exception nutzen. Wenn der Aufrufer vermutlich nichts tun kann,
um sich von dem Problem zu erholen, dann sollte man eine unchecked Exception einsetzen.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Unterschied zwischen Error und Exception
- (K2) Unterschied zwischen checked und unchecked Exceptions
- (K3) Umgang mit Exceptions
- (K3) Eigene Exceptions schreiben
Fehlerfälle in Java
int div(int a, int b) {
return a / b;
}
div(3, 0);
Problem: Programm wird abstürzen, da durch '0' geteilt wird ...
Lösung?
Optional<Integer> div(int a, int b) {
if (b == 0) return Optional.empty();
return Optional.of(a / b);
}
Optional<Integer> x = div(3, 0);
if (x.isPresent()) {
// do something
} else {
// do something else
}
Probleme:
- Da
int nicht null sein kann, muss ein Integer Objekt erzeugt und zurückgegeben werden:
Overhead wg. Auto-Boxing und -Unboxing!
- Der Aufrufer muss auf
null prüfen.
- Es wird nicht kommuniziert, warum
null zurückgegeben wird. Was ist das Problem?
- Was ist, wenn
null ein gültiger Rückgabewert sein soll?
Vererbungsstruktur Throwable

Exception vs. Error
Error:
- Wird für Systemfehler verwendet (Betriebssystem, JVM, ...)
StackOverflowErrorOutOfMemoryError
- Von einem Error kann man sich nicht erholen
- Sollten nicht behandelt werden
Exception:
- Ausnahmesituationen bei der Abarbeitung eines Programms
- Können "checked" oder "unchecked" sein
- Von Exceptions kann man sich erholen
Unchecked vs. Checked Exceptions
- "Checked" Exceptions:
- Für erwartbare Fehlerfälle, deren Ursprung nicht im Programm selbst liegt
FileNotFoundExceptionIOException
- Alle nicht von
RuntimeException ableitende Exceptions
- Müssen entweder behandelt (
try/catch) oder deklariert (throws) werden:
Dies wird vom Compiler überprüft!
- "Unchecked" Exceptions:
- Logische Programmierfehler ("Versagen" des Programmcodes)
IndexOutOfBoundExceptionNullPointerExceptionArithmeticExceptionIllegalArgumentException
- Leiten von
RuntimeException oder Unterklassen ab
- Müssen nicht deklariert oder behandelt werden
Beispiele checked Exception:
- Es soll eine Abfrage an eine externe API geschickt werden. Diese ist aber aktuell
nicht zu erreichen. "Erholung": Anfrage noch einmal schicken.
- Es soll eine Datei geöffnet werden. Diese ist aber nicht unter dem angegebenen
Pfad zu finden oder die Berechtigungen stimmen nicht. "Erholung": Aufrufer öffnet
neuen File-Picker, um es noch einmal mit einer anderen Datei zu versuchen.
Beispiele unchecked Exception:
- Eine
for-Loop über ein Array ist falsch programmiert und will auf einen Index
im Array zugreifen, der nicht existiert. Hier kann der Aufrufer nicht Sinnvolles
tun, um sich von dieser Situation zu erholen.
- Argumente oder Rückgabewerte einer Methode können
null sein. Wenn man das nicht
prüft, sondern einfach Methoden auf dem vermeintlichen Objekt aufruft, wird eine
NullPointerException ausgelöst, die eine Unterklasse von RuntimeException ist
und damit eine unchecked Exception. Auch hier handelt es sich um einen Fehler in
der Programmlogik, von dem sich der Aufrufer nicht sinnvoll erholen kann.
Throws
int div(int a, int b) throws ArithmeticException {
return a / b;
}
Alternativ:
int div(int a, int b) throws IllegalArgumentException {
if (b == 0) throw new IllegalArgumentException("Can't divide by zero");
return a / b;
}
Exception können an an den Aufrufer weitergeleitet werden oder selbst geworfen werden.
Wenn wie im ersten Beispiel bei einer Operation eine Exception entsteht und nicht
gefangen wird, dann wird sie automatisch an den Aufrufer weitergeleitet. Dies wird
über die throws-Klausel deutlich gemacht (Keyword throws plus den/die Namen der
Exception(s), angefügt an die Methodensignatur). Bei unchecked Exceptions kann man
das tun, bei checked Exceptions muss man dies tun.
Wenn man wie im zweiten Beispiel selbst eine neue Exception werfen will, erzeugt man
mit new ein neues Objekt der gewünschten Exception und "wirft" diese mit throw.
Auch diese Exception kann man dann entweder selbst fangen und bearbeiten (siehe nächste
Folie) oder an den Aufrufer weiterleiten und dies dann entsprechend über die
throws-Klausel deklarieren: nicht gefangene checked Exceptions müssen deklariert
werden, nicht gefangene unchecked Exceptions können deklariert werden.
Wenn mehrere Exceptions an den Aufrufer weitergeleitet werden, werden sie in der
throws-Klausel mit Komma getrennt: throws Exception1, Exception2, Exception3.
Anmerkung: In beiden obigen Beispielen wurde zur Verdeutlichung, dass die Methode
div() eine Exception wirft, diese per throws-Klausel deklariert. Da es sich bei
den beiden Beispielen aber jeweils um unchecked Exceptions handelt, ist dies im
obigen Beispiel nicht notwendig. Der Aufrufer muss auch nicht ein passendes
Exception-Handling einsetzen!
Wenn wir stattdessen eine checked Exception werfen würden oder in div() eine
Methode aufrufen würden, die eine checked Exception deklariert hat, muss diese
checked Exception entweder in div() gefangen und bearbeitet werden oder aber per
throws-Klausel deklariert werden. Im letzteren Fall muss dann der Aufrufer analog
damit umgehen (fangen oder selbst auch deklarieren). Dies wird vom Compiler geprüft!
Try-Catch
int a = getUserInput();
int b = getUserInput();
try {
div(a, b);
} catch (IllegalArgumentException e) {
e.printStackTrace(); // Wird im Fehlerfall aufgerufen
}
// hier geht es normal weiter
- Im
try Block wird der Code ausgeführt, der einen Fehler werfen könnte.
- Mit
catch kann eine Exception gefangen und im catch Block behandelt werden.
Anmerkung: Das bloße Ausgeben des Stacktrace via e.printStackTrace() ist
noch kein sinnvolles Exception-Handling! Hier sollte auf die jeweilige Situation
eingegangen werden und versucht werden, den Fehler zu beheben oder dem Aufrufer
geeignet zu melden!
_Try_und mehrstufiges Catch
try {
someMethod(a, b, c);
} catch (IllegalArgumentException iae) {
iae.printStackTrace();
} catch (FileNotFoundException | NullPointerException e) {
e.printStackTrace();
}
Eine im try-Block auftretende Exception wird der Reihe nach mit den catch-Blöcken
gematcht (vergleichbar mit switch case).
Wichtig: Dabei muss die Vererbungshierarchie beachtet werden. Die spezialisierteste
Klasse muss ganz oben stehen, die allgemeinste Klasse als letztes. Sonst wird eine
Exception u.U. zu früh in einem nicht dafür gedachten catch-Zweig aufgefangen.
Wichtig: Wenn eine Exception nicht durch die catch-Zweige aufgefangen wird, dann
wird sie an den Aufrufer weiter geleitet. Im Beispiel würde eine IOException nicht durch
die catch-Zweige gefangen (IllegalArgumentException und NullPointerException sind
im falschen Vererbungszweig, und FileNotFoundException ist spezieller als IOException)
und entsprechend an den Aufrufer weiter gereicht. Da es sich obendrein um eine checked
Exception handelt, müsste man diese per throws IOException an der Methode deklarieren.
Finally
Scanner myScanner = new Scanner(System.in);
try {
return 5 / myScanner.nextInt();
} catch (InputMismatchException ime) {
ime.printStackTrace();
} finally {
// wird immer aufgerufen
myScanner.close();
}
Der finally Block wird sowohl im Fehlerfall als auch im Normalfall aufgerufen. Dies
wird beispielsweise für Aufräumarbeiten genutzt, etwa zum Schließen von Verbindungen
oder Input-Streams.
Try-with-Resources
try (Scanner myScanner = new Scanner(System.in)) {
return 5 / myScanner.nextInt();
} catch (InputMismatchException ime) {
ime.printStackTrace();
}
Im try-Statement können Ressourcen deklariert werden, die am Ende sicher geschlossen
werden. Diese Ressourcen müssen java.io.Closeable implementieren.
Eigene Exceptions
// Checked Exception
public class MyCheckedException extends Exception {
public MyCheckedException(String errorMessage) {
super(errorMessage);
}
}
// Unchecked Exception
public class MyUncheckedException extends RuntimeException {
public MyUncheckedException(String errorMessage) {
super(errorMessage);
}
}
Eigene Exceptions können durch Spezialisierung anderer Exception-Klassen realisiert
werden. Dabei kann man direkt von Exception oder RuntimeException ableiten oder
bei Bedarf von spezialisierteren Exception-Klassen.
Wenn die eigene Exception in der Vererbungshierarchie unter RuntimeException steht,
handelt es sich um eine unchecked Exception, sonst um eine checked Exception.
In der Benutzung (werfen, fangen, deklarieren) verhalten sich eigene Exception-Klassen
wie die Exceptions aus dem JDK.
Stilfrage: Wie viel Code im Try?
int getFirstLineAsInt(String pathToFile) {
FileReader fileReader = new FileReader(pathToFile);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String firstLine = bufferedReader.readLine();
return Integer.parseInt(firstLine);
}
Hier lassen sich verschiedene "Ausbaustufen" unterscheiden.
Handling an den Aufrufer übergeben
int getFirstLineAsIntV1(String pathToFile) throws FileNotFoundException, IOException {
FileReader fileReader = new FileReader(pathToFile);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String firstLine = bufferedReader.readLine();
return Integer.parseInt(firstLine);
}
Der Aufrufer hat den Pfad als String übergeben und ist vermutlich in der Lage, auf
Probleme mit dem Pfad sinnvoll zu reagieren. Also könnte man in der Methode selbst
auf ein try/catch verzichten und stattdessen die FileNotFoundException (vom
FileReader) und die IOException (vom bufferedReader.readLine()) per throws
deklarieren.
Anmerkung: Da FileNotFoundException eine Spezialisierung von IOException ist,
reicht es aus, lediglich die IOException zu deklarieren.
Jede Exception einzeln fangen und bearbeiten
int getFirstLineAsIntV2(String pathToFile) {
FileReader fileReader = null;
try {
fileReader = new FileReader(pathToFile);
} catch (FileNotFoundException fnfe) {
fnfe.printStackTrace(); // Datei nicht gefunden
}
BufferedReader bufferedReader = new BufferedReader(fileReader);
String firstLine = null;
try {
firstLine = bufferedReader.readLine();
} catch (IOException ioe) {
ioe.printStackTrace(); // Datei kann nicht gelesen werden
}
try {
return Integer.parseInt(firstLine);
} catch (NumberFormatException nfe) {
nfe.printStackTrace(); // Das war wohl kein Integer
}
return 0;
}
In dieser Variante wird jede Operation, die eine Exception werfen kann, separat in
ein try/catch verpackt und jeweils separat auf den möglichen Fehler reagiert.
Dadurch kann man die Fehler sehr einfach dem jeweiligen Statement zuordnen.
Allerdings muss man nun mit Behelfsinitialisierungen arbeiten und der Code wird sehr
in die Länge gezogen und man erkennt die eigentlichen funktionalen Zusammenhänge nur
noch schwer.
Anmerkung: Das "Behandeln" der Exceptions ist im obigen Beispiel kein gutes Beispiel
für das Behandeln von Exceptions. Einfach nur einen Stacktrace zu printen und weiter
zu machen, als ob nichts passiert wäre, ist kein sinnvolles Exception-Handling.
Wenn Sie solchen Code schreiben oder sehen, ist das ein Anzeichen, dass auf dieser Ebene
nicht sinnvoll mit dem Fehler umgegangen werden kann und dass man ihn besser an den
Aufrufer weiter reichen sollte (siehe nächste Folie).
Funktionaler Teil in gemeinsames Try und mehrstufiges Catch
int getFirstLineAsIntV3(String pathToFile) {
try {
FileReader fileReader = new FileReader(pathToFile);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String firstLine = bufferedReader.readLine();
return Integer.parseInt(firstLine);
} catch (FileNotFoundException fnfe) {
fnfe.printStackTrace(); // Datei nicht gefunden
} catch (IOException ioe) {
ioe.printStackTrace(); // Datei kann nicht gelesen werden
} catch (NumberFormatException nfe) {
nfe.printStackTrace(); // Das war wohl kein Integer
}
return 0;
}
Hier wurde der eigentliche funktionale Kern der Methode in ein gemeinsames try/catch
verpackt und mit einem mehrstufigen catch auf die einzelnen Fehler reagiert. Durch die
Art der Exceptions sieht man immer noch, wo der Fehler herkommt. Zusätzlich wird die
eigentliche Funktionalität so leichter erkennbar.
Anmerkung: Auch hier ist das gezeigte Exception-Handling kein gutes Beispiel. Entweder
man macht hier sinnvollere Dinge, oder man überlässt dem Aufrufer die Reaktion auf den
Fehler.
Stilfrage: Wo fange ich die Exception?
private static void methode1(int x) throws IOException {
JFileChooser fc = new JFileChooser();
fc.showDialog(null, "ok");
methode2(fc.getSelectedFile().toString(), x, x * 2);
}
private static void methode2(String path, int x, int y) throws IOException {
FileWriter fw = new FileWriter(path);
BufferedWriter bw = new BufferedWriter(fw);
bw.write("X:" + x + " Y: " + y);
}
public static void main(String... args) {
try {
methode1(42);
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
Prinzipiell steht es einem frei, wo man eine Exception fängt und behandelt. Wenn im
main() eine nicht behandelte Exception auftritt (weiter nach oben geleitet wird),
wird das Programm mit einem Fehler beendet.
Letztlich scheint es eine gute Idee zu sein, eine Exception so nah wie möglich am
Ursprung der Fehlerursache zu behandeln. Man sollte sich dabei die Frage stellen: Wo
kann ich sinnvoll auf den Fehler reagieren?
Stilfrage: Wann checked, wann unchecked
"Checked" Exceptions
- Für erwartbare Fehlerfälle, deren Ursprung nicht im Programm selbst liegt
- Aufrufer kann sich von der Exception erholen
"Unchecked" Exceptions
- Logische Programmierfehler ("Versagen" des Programmcodes)
- Aufrufer kann sich von der Exception vermutlich nicht erholen
Vergleiche "Unchecked Exceptions — The Controversy".
Wrap-Up
-
Error und Exception: System vs. Programm
-
Checked und unchecked Exceptions: Exception vs. RuntimeException
-
try: Versuche Code auszuführen
-
catch: Verhalten im Fehlerfall
-
finally: Verhalten im Erfolgs- und Fehlerfall
-
throw: Wirft eine Exception
-
throws: Deklariert eine Exception an Methode
-
Eigene Exceptions durch Ableiten von anderen Exceptions
(werden je nach Vererbungshierarchie automatisch checked oder unchecked)
Challenges
Betrachten Sie die Vorgaben.
Verbessern Sie das Exception-Handling
Im package better_try_catch finden Sie die Klasse BetterTryCatchMain, in der
verschiedene Methoden der Klasse MyFunctions aufgerufen werden.
Erklären Sie, warum das dort implementierte Exception-Handling nicht gut ist und
verbessern Sie es.
Checked vs. unckecked Exceptions
Erklären Sie den Unterschied zwischen checked und unchecked Exceptions.
Im Folgenden werden verschiedene Exceptions beschrieben. Erklären Sie, ob diese
jeweils "checked" oder "unchecked" sein sollten.
IntNotBetweenException soll geworfen werden, wenn ein Integer-Parameter nicht
im definierten Wertebereich liegt.NoPicturesFoundException soll geworfen werden, wenn in einem übergebenen
Verzeichnis keine Bilddateien gefunden werden konnten.NotAPrimeNumberException soll geworfen werden, wenn eine vom User eingegebene
Zahl keine Primzahl ist.
Freigeben von Ressourcen
Im Package finally_resources finden Sie die Klasse MyResource.
Rufen Sie die Methode MyResource#doSomething auf, im Anschluss müssen Sie immer
die Methode MyResource#close aufrufen.
- Zeigen Sie den Aufruf mit
try-catch-finally.
- Verändern Sie die Vorgaben so, dass Sie den Aufruf mit der "try-with-resources"-Technik
ausführen können.
Where to catch?
Erklären Sie, wann und wo eine Exception gefangen und bearbeitet werden sollte.
Im Package where_to_catch finden Sie die Klasse JustThrow. Alle Methoden in der Klasse
werfen aufkommende Exceptions bis zur main hoch.
Verändern Sie die Vorgaben so, dass die Exceptions an den passenden Stellen gefangen und
sinnvoll bearbeitet werden. Begründen Sie Ihre Entscheidungen.
Aufzählungen (Enumerations)
TL;DR
Mit Hilfe von enum lassen sich Aufzählungstypen definieren (der Compiler erzeugt intern
passende Klassen). Dabei wird den Konstanten eine fortlaufende Nummer zugeordnet, auf die
mit ordinal() zugegriffen werden kann. Mit der Methode values() kann über die Konstanten
iteriert werden, und mit name() kann eine Stringrepräsentation einer Konstanten erzeugt
werden. Es sind keine Instanzen von Enum-Klassen erzeugbar, und die Enum-Konstanten sind
implizit final und static.
Es lassen sich auch komplexe Enumerations analog zu Klassendefinition definieren, die eigene
Konstruktoren, Felder und Methoden enthalten.
Videos (HSBI-Medienportal)
Lernziele
- (K2) Vorgänge beim Initialisieren von Enum-Klassen (Hinweis:
static) - (K3) Erstellung komplexer Enumerationen mit Feldern und Konstruktoren
- (K3) Nutzung von
name(), ordinal() und values() in Enum-Klassen
Motivation
public class Studi {
public static final int IFM = 0;
public static final int ELM = 1;
public static final int ARC = 2;
public Studi(String name, int credits, int studiengang) {
// Wert für studiengang muss zwischen 0 und 2 liegen
// Erwünscht: Konstanten nutzen
}
public static void main(String[] args) {
Studi rainer = new Studi("Rainer", 10, Studi.IFM);
Studi holger = new Studi("Holger", 3, 4); // Laufzeit-Problem!
}
}
Probleme:
- Keine Typsicherheit
- Konstanten gehören zur Klasse
Studi, obwohl sie in anderem Kontext
vermutlich auch interessant sind
Verbesserung: Einfache Aufzählung
public enum Fach {
IFM, ELM, ARC
}
public class Studi {
public Studi(String name, int credits, Fach studiengang) {
// Typsicherheit für studiengang :-)
}
public static void main(String[] args) {
Studi rainer = new Studi("Rainer", 10, Fach.IFM);
Studi holger = new Studi("Holger", 3, 4); // Syntax-Fehler!
}
}
Einfache Aufzählungen: Eigenschaften
public enum Fach {
IFM, ELM, ARC
}
- Enum-Konstanten (
IFM, ...) sind implizit static und final
- Enumerations (
Fach) nicht instantiierbar
- Enumerations stellen einen neuen Typ dar: hier der Typ
Fach
- Methoden:
name(), ordinal(), values(), toString()
Wiederholung static
Attribute:
static Attribute sind Eigenschaften/Zustände der Klasse- Gelten in jedem von der Klasse erzeugten Objekt
- Unterschiedliche Lebensdauer:
- Objektattribute (Instanzvariablen): ab
new bis zum Garbage Collector
- Statische Variablen: Laufzeitumgebung (JVM) lädt und initialisiert die Klasse
(
static Attribute existieren, bis die JVM die Klasse entfernt)
Methoden:
static deklarierte Methoden sind Klassenmethoden- Können direkt auf der Klasse aufgerufen werden
- Beispiele:
Math.max(), Math.sin(), Integer.parseInt()
- Achtung: In Klassenmethoden nur Klassenattribute nutzbar (keine Instanzattribute!),
d.h. keine
this-Referenz nutzbar
Wiederholung final: Attribute/Methoden/Klassen nicht änderbar
-
Attribute: final Attribute können nur einmal gesetzt werden
void foo() {
int i = 2;
final int j = 3;
final int k;
i = 3;
j = 4; // Compilerfehler
k = 5;
k = 6; // Compilerfehler
}
-
Methoden: final deklarierte Methoden können bei Vererbung nicht überschrieben werden
-
Klassen: von final deklarierten Klassen können keine Unterklassen gebildet werden
Einfache Aufzählungen: Eigenschaften (cnt.)
// Referenzen auf Enum-Objekte können null sein
Fach f = null;
f = Fach.IFM;
// Vergleich mit == möglich
// equals() unnötig, da Vergleich mit Referenz auf statische Variable
if (f == Fach.IFM) {
System.out.println("Richtiges Fach :-)");
}
// switch/case
switch (f) {
case IFM: // Achtung: *NICHT* Fach.IFM
System.out.println("Richtiges Fach :-)");
break;
default:
throw new IllegalArgumentException("FALSCHES FACH: " + f);
}
Außerdem können wir folgende Eigenschaften nutzen (u.a., s.u.):
- Enumerations haben Methode
String toString() für die Konstanten
- Enumerations haben Methode
final T[] values() für die Iteration über die Konstanten
Enum: Genauer betrachtet
public enum Fach { IFM, ELM, ARC }
Compiler sieht (in etwa):
public class Fach extends Enum {
public static final Fach IFM = new Fach("IFM", 0);
public static final Fach ELM = new Fach("ELM", 1);
public static final Fach ARC = new Fach("ARC", 2);
private Fach( String s, int i ) { super( s, i ); }
}
=> Singleton-Pattern für Konstanten
Enum-Klassen: Eigenschaften
public enum Fach {
IFM,
ELM("Elektrotechnik Praxisintegriert", 1, 30),
ARC("Architektur", 4, 40),
PHY("Physik", 3, 10);
private final String description;
private final int number;
private final int capacity;
Fach() { this("Informatik Bachelor", 0, 60); }
Fach(String descr, int number, int capacity) {
this.description = descr; this.number = number; this.capacity = capacity;
}
public String getDescription() {
return "Konstante: " + name() + " (Beschreibung: " + description
+ ", Kapazitaet: " + capacity + ", Nummer: " + number
+ ", Ordinal: " + ordinal() + ")";
}
}
Konstruktoren und Methoden für Enum-Klassen definierbar
- Kein eigener Aufruf von
super (!)
- Konstruktoren implizit
private
Compiler fügt automatisch folgende Methoden hinzu (Auswahl):
- Strings:
public final String name() => Name der Konstanten (final!)public String toString() => Ruft name() auf, überschreibbar
- Konstanten:
public final T[] values() => Alle Konstanten der Aufzählungpublic final int ordinal() => Interne Nummer der Konstanten
(Reihenfolge des Anlegens der Konstanten!)public static T valueOf(String) => Zum String passende Konstante
(via name())
Hinweis: Diese Methoden gibt es auch bei den "einfachen" Enumerationen (s.o.).
Wrap-Up
-
Aufzählungen mit Hilfe von enum (Compiler erzeugt intern Klassen)
-
Komplexe Enumerations analog zu Klassendefinition: Konstruktoren, Felder und Methoden
(keine Instanzen von Enum-Klassen erzeugbar)
-
Enum-Konstanten sind implizit final und static
-
Compiler stellt Methoden name(), ordinal() und values() zur Verfügung
- Name der Konstanten
- Interne Nummer der Konstanten (Reihenfolge des Anlegens)
- Array mit allen Konstanten der Enum-Klasse
Quellen
- [Java-SE-Tutorial] The Java Tutorials
Oracle Corporation, 2022.
Trail: Learning the Java Language :: Classes and Objects :: Enum Types - [Ullenboom2021] Java ist auch eine Insel
Ullenboom, C., Rheinwerk-Verlag, 2021. ISBN 978-3-8362-8745-6.
Abschnitt 6.4.3: Aufzählungstypen, Abschnitt 10.7: Die Spezial-Oberklasse Enum
Konfiguration eines Programms
TL;DR
Zu Konfiguration von Programmen kann man beim Aufruf Kommandozeilenparameter mitgeben. Diese
sind in der über den ParameterString[] args in der main(String[] args)-Methode zugreifbar.
Es gibt oft eine Kurzversion ("-x") und/oder eine Langversion ("--breite"). Zusätzlich können
Parameter noch ein Argument haben ("-x 12" oder "--breite=12"). Parameter können optional oder
verpflichtend sein.
Um dies nicht manuell auswerten zu müssen, kann man beispielsweise die Bibliothkek Apache
Commons CLI benutzen.
Ein anderer Weg zur Konfiguration sind Konfigurationsdateien, die man entsprechend einliest.
Hier findet man häufig das "Ini-Format", also zeilenweise "Key=Value"-Paare. Diese kann man
mit der Klasse java.util.Properties einlesen, bearbeiten und speichern (auch als XML).
Videos (HSBI-Medienportal)
Lernziele
- (K3) Auswertung von Kommandozeilenparametern in einem Programm
- (K3) Apache Commons CLI zur Verarbeitung von Kommandozeilenparametern
- (K3) Laden von Konfigurationsdaten mit
java.util.Properties
Wie kann man Programme konfigurieren?
-
Parameter beim Start mitgeben: Kommandozeilenparameter (CLI)
-
Konfigurationsdatei einlesen und auswerten
Varianten von Kommandozeilenparameter
-
Fixe Reihenfolge
java MyApp 10 20 hello debug
-
Benannte Parameter I
java MyApp -x 10 -y 20 -answer hello -d
-
Benannte Parameter II
java MyApp --breite=10 --hoehe=20 --answer=hello --debug
Häufig Mischung von Kurz- und Langformen
Häufig hat man eine Kurzform der Optionen, also etwa "-x". Dabei ist der Name der Option
in der Regel ein Zeichen lang. Es gibt aber auch Abweichungen von dieser Konvention, denken
Sie beispielsweise an java -version.
In der Langform nutzt man dann einen aussagekräftigen Namen und stellt zwei Bindestriche
voran, also beispielsweise "--breite" (als Alternative für "-x").
Wenn Optionen Parameter haben, schreibt man in der Kurzform üblicherweise "-x 10" (trennt
also den Parameter mit einem Leerzeichen von der Option) und in der Langform "--breite=10"
(also mit einem "=" zwischen Option und Parameter). Das sind ebenfalls Konventionen, d.h.
man kann prinzipiell auch in der Kurzform das "=" nutzen, also "-x=10", oder in der Langform
mit einem Leerzeichen trennen, also "--breite 10".
Hinweis IntelliJ: "Edit Configurations" => Kommandozeilenparameter unter "Build and run" im entsprechenden Feld eintragen

Auswertung Kommandozeilenparameter
Anmerkung: Nur Parameter! Nicht Programmname als erster Eintrag wie in C ...
Beispiel Auswertung Kommandozeilenparameter
public static void main(String[] args) {
int x = 100;
String answer = "";
boolean debug = false;
// Parameter: -x=10 -answer=hello -debug
// => args = ["-x=10", "-answer=hello", "-debug"]
for (String param : args) {
if (param.startsWith("-x")) { x = Integer.parseInt(param.substring(3)); }
if (param.startsWith("-a")) { answer = param.substring(8); }
if (param.startsWith("-d")) { debug = true; }
}
}
Kritik an manueller Auswertung Kommandozeilenparameter
- Umständlich und unübersichtlich
- Große
if-else-Gebilde in main()
- Kurz- und Langform müssen getrennt realisiert werden
- Optionale Parameter müssen anders geprüft werden als Pflichtparameter
- Überlappende Parameternamen schwer aufzufinden
- Prüfung auf korrekten Typ nötig bei Parametern mit Werten
- Hilfe bei Fehlern muss separat realisiert und gepflegt werden
Apache Commons: CLI
Rad nicht neu erfinden!
Annäherung an fremde API:
- Lesen der verfügbaren Doku (PDF, HTML)
- Lesen der verfügbaren Javadoc
- Herunterladen der Bibliothek
- Einbinden ins Projekt
Exkurs: Einbinden fremder Bibliotheken/APIs
Eclipse
- Lib von commons.apache.org
herunterladen und auspacken
- Neuen Unterordner im Projekt anlegen:
libs/
- Bibliothek (
.jar-Files) hinein kopieren
- Projektexplorer, Kontextmenü auf
.jar-File: "Add as Library"
- Alternativ Menü-Leiste: "
Project > Properties > Java Build Path > Libraries > Add JARs"
IntelliJ
- Variante 1:
- Lib von commons.apache.org
herunterladen und auspacken
- Neuen Unterordner im Projekt anlegen:
libs/
- Bibliothek (
.jar-Files) hinein kopieren
- Variante 1 (a):Projektexplorer, Kontextmenü auf
.jar-File: "Build Path > Add to Build Path"
- Variante 1 (b): Projekteigenschaften, Eintrag "Libraries", "+", "New Project Library", "Java" und Jar-File auswählen
- Variante 2:
- Projekteigenschaften, Eintrag "Libraries", "+", "New Project Library", "From Maven" und
"commons-cli:commons-cli:1.5.0" als Suchstring eingeben und die Suche abschließen
Gradle oder Ant oder Maven
- Lib auf Maven Central suchen: "commons-cli:commons-cli" als Suchstring eingeben
- Passenden Dependency-Eintrag in das Build-Skript kopieren
Kommandozeilenaufruf
-
Class-Path bei Aufruf setzen:
- Unix:
java -cp .:<jarfile>:<jarfile> <mainclass>
- Windows:
java -cp .;<jarfile>;<jarfile> <mainclass>
Achtung: Unter Unix (Linux, MacOS) wird ein Doppelpunkt zum Trennen
der Jar-Files eingesetzt, unter Windows ein Semikolon!
Beispiel: java -classpath .:/home/user/wuppy.jar MyApp
Vorgriff auf Build-Skripte (spätere VL): Im hier gezeigten Vorgehen werden die
Abhängigkeiten manuell aufgelöst, d.h. die Jar-Files werden manuell heruntergeladen
(oder selbst kompiliert) und dem Projekt hinzugefügt.
Alle später besprochenen Build-Skripte (Ant, Gradle) beherrschen die automatische
Auflösung von Abhängigkeiten. Dazu muss im Skript die Abhängigkeit auf geeignete
Weise beschrieben werden und wird dann beim Kompilieren des Programms automatisch
von spezialisierten Servern in der im Skript definierten Version heruntergeladen.
Dies funktioniert auch bei rekursiven Abhängigkeiten ...
Überblick Umgang mit Apache Commons CLI
Paket: org.apache.commons.cli
- Definition der Optionen
- Je Option eine Instanz der Klasse
Option
- Alle Optionen in Container
Options sammeln
- Parsen der Eingaben mit
DefaultParser
- Abfragen der Ergebnisse:
CommandLine
- Formatierte Hilfe ausgeben:
HelpFormatter
Die Funktionsweise der einzelnen Klassen wird in der Demo kurz angerissen. Schauen Sie bitte
zusätzlich in die Dokumentation.
Laden und Speichern von Konfigurationsdaten
#ola - ein Kommentar
hoehe=2
breite=9
gewicht=12
Laden und Speichern von Konfigurationsdaten (cnt.)
-
Properties anlegen und modifizieren
Properties props = new Properties();
props.setProperty("breite", "9");
props.setProperty("breite", "99");
String value = props.getProperty("breite");
-
Properties speichern: Properties#store und Properties#storeToXML
public void store(Writer writer, String comments)
public void store(OutputStream out, String comments)
public void storeToXML(OutputStream os, String comment, String encoding)
-
Properties laden: Properties#load und Properties#loadFromXML
public void load(Reader reader)
public void load(InputStream inStream)
public void loadFromXML(InputStream in)
java.util.Properties sind eine einfache und im JDK bereits eingebaute Möglichkeit,
mit Konfigurationsdateien zu hantieren. Deutlich umfangreichere Möglichkeiten bieten
aber externe Bibliotheken, beispielsweise "Apache Commons Configuration"
(commons.apache.org/configuration).
Wrap-Up
- Kommandozeilenparameter als
String[] in main()-Methode
- Manuelle Auswertung komplex => Apache Commons CLI
- Schlüssel-Wert-Paare mit
java.util.Properties aus/in Dateien laden/speichern
Quellen
- [Java-SE-Tutorial] The Java Tutorials
Oracle Corporation, 2022.
Essential Java Classes \> The Platform Environment \> Configuration Utilities





