Subsections of Interpreter
Syntaxgesteuerte Interpreter
TL;DR
Zur Einordnung noch einmal die bisher betrachteten Phasen und die jeweiligen Ergebnisse:
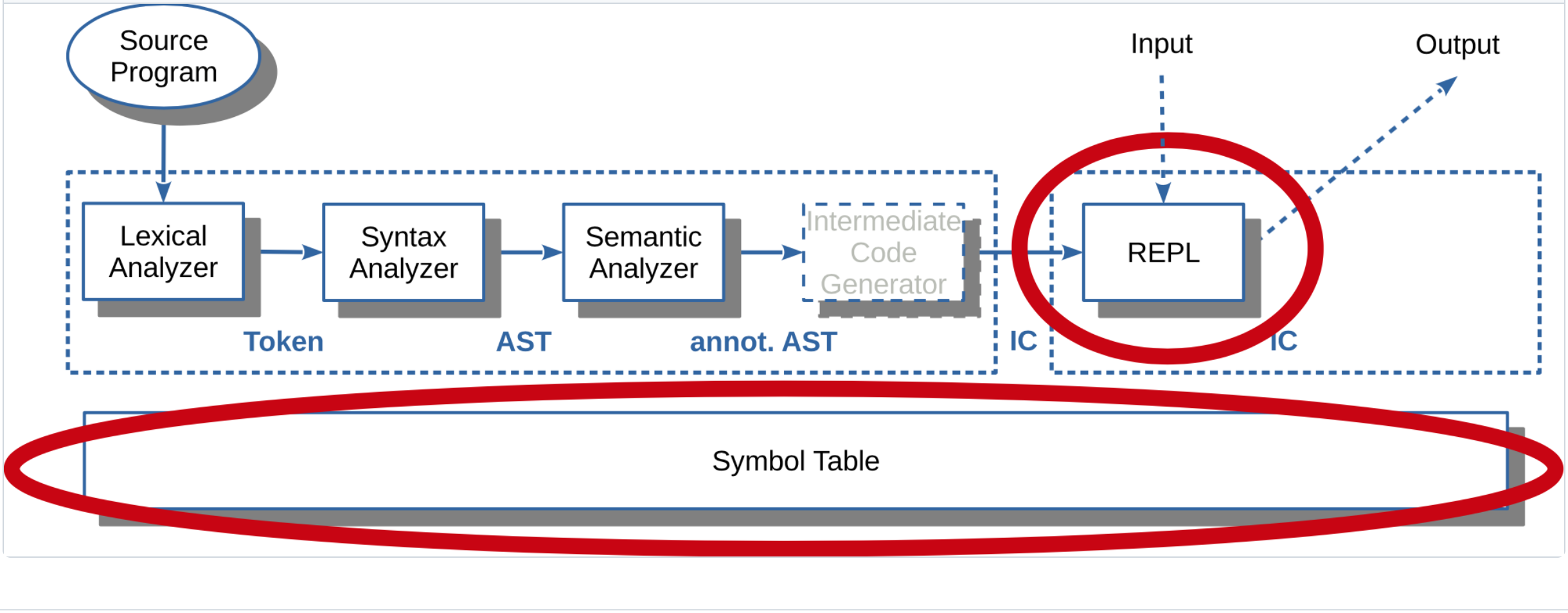
|
Phase |
Ergebnis |
| 0 |
Lexer/Parser |
AST |
| 1 |
Semantische Analyse, Def-Phase |
Symboltabelle (Definitionen), Verknüpfung Scopes mit AST-Knoten |
| 2 |
Semantische Analyse, Ref-Phase |
Prüfung auf nicht definierte Referenzen |
| 3 |
Interpreter |
Abarbeitung, Nutzung von AST und Symboltabelle |
Das Erzeugen der Symboltabelle wird häufig in zwei Phasen aufgeteilt: Zunächst
werden die Definitionen abgearbeitet und in der zweiten Phase wird noch einmal
über den AST iteriert und die Referenzen werden geprüft. Dies hat den Vorteil,
dass man mit Vorwärtsreferenzen arbeiten kann ...
Für die semantische Analyse kann man gut mit Listenern arbeiten, für den Interpreter
werden oft Visitors eingesetzt.
Die einfachste Form von Interpretern sind die "syntaxgesteuerten Interpreter". Durch
den Einsatz von attributierten Grammatiken und eingebetteten Aktionen kann in einfachen
Fällen der Programmcode bereits beim Parsen interpretiert werden, d.h. nach dem Parsen
steht das Ergebnis fest.
Normalerweise traversiert man in Interpretern aber den AST, etwa mit dem Listener-
oder Visitor-Pattern. Die in dieser Sitzung gezeigten einfachen Beispiele der
syntaxgesteuerten Interpreter werden erweitert auf die jeweilige Traversierung mit
dem Listener- bzw. Visitor-Pattern. Für nicht so einfache Fälle braucht man aber
zusätzlich noch Speicherstrukturen, die wir in
AST-basierte Interpreter: Basics
und
AST-basierte Interpreter: Funktionen und Klassen
betrachten.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Attribute und eingebettete Aktionen in Bison und ANTLR
- (K3) Traversierung von Parse-Trees und Implementierung von Aktionen mit Hilfe des Listener-Patterns
- (K3) Traversierung von Parse-Trees und Implementierung von Aktionen mit Hilfe des Visitor-Patterns
Überblick Interpreter
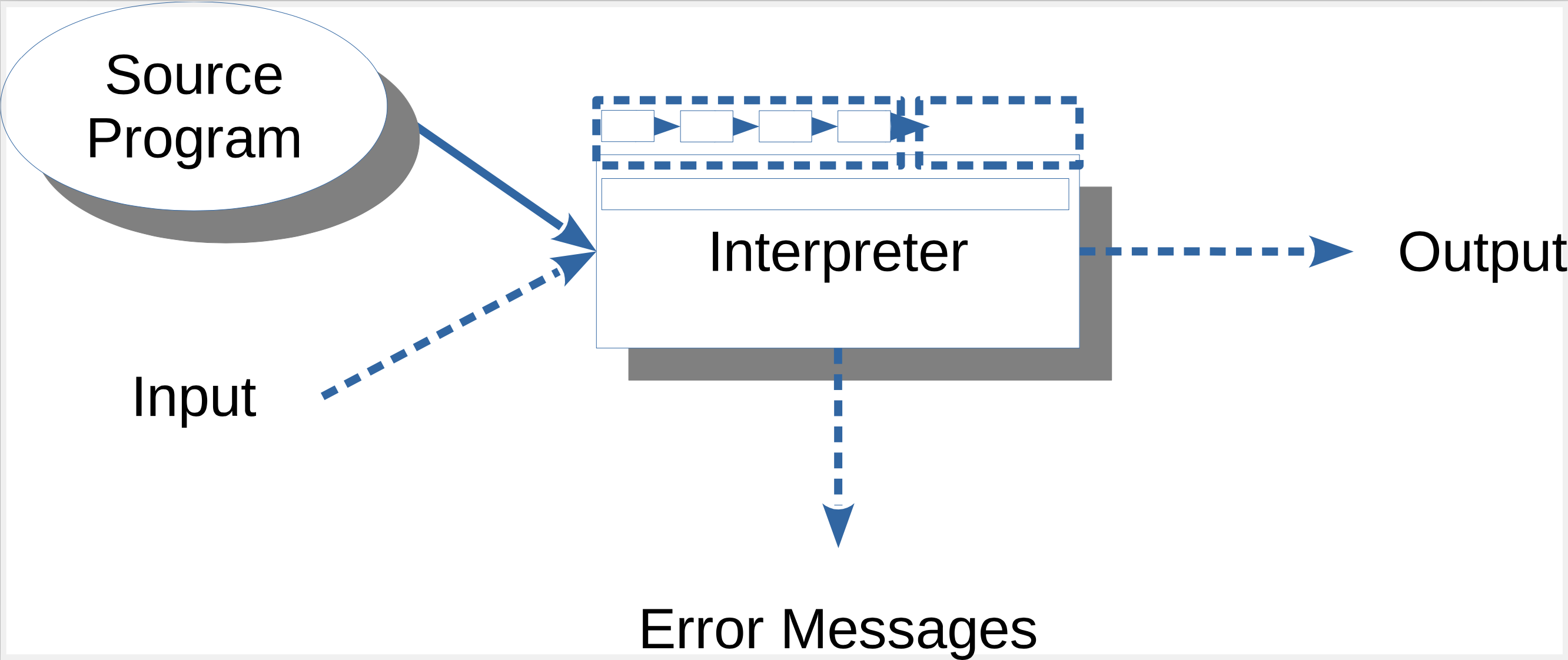
Beim Interpreter durchläuft der Sourcecode nur das Frontend, also die Analyse.
Es wird kein Code erzeugt, stattdessen führt der Interpreter die Anweisungen
im AST bzw. IC aus. Dazu muss der Interpreter mit den Eingabedaten beschickt
werden.
Es gibt verschiedene Varianten, beispielsweise:
-
Syntaxgesteuerte Interpreter
- Einfachste Variante, wird direkt im Parser mit abgearbeitet
- Keine Symboltabellen, d.h. auch keine Typprüfung oder Vorwärtsdeklarationen o.ä.
(d.h. erlaubt nur vergleichsweise einfache Sprachen)
- Beispiel: siehe nächste Folie
-
AST-basierte Interpreter
- Nutzt den AST und Symboltabellen
- Beispiel: siehe weiter unten
-
Stack-basierte Interpreter
- Simuliert eine Stack Machine, d.h. hält alle (temporären) Werte auf einem Stack
- Arbeitet typischerweise auf bereits stark vereinfachtem Zwischencode (IR),
etwa Bytecode
-
Register-basierte Interpreter
- Simuliert eine Register Machine, d.h. hält alle (temporären) Werte in virtuellen
Prozessor-Registern
- Arbeitet typischerweise auf bereits stark vereinfachtem Zwischencode (IR),
etwa Bytecode
Weiterhin kann man Interpreter danach unterscheiden, ob sie interaktiv sind oder nicht.
Python kann beispielsweise direkt komplette Dateien verarbeiten oder interaktiv Eingaben
abarbeiten. Letztlich kommen dabei aber die oben dargestellten Varianten zum Einsatz.
Syntaxgesteuerte Interpreter: Attributierte Grammatiken
s : expr {System.err.println($expr.v);} ;
expr returns [int v]
: e1=expr '*' e2=expr {$v = $e1.v * $e2.v;}
| e1=expr '+' e2=expr {$v = $e1.v + $e2.v;}
| DIGIT {$v = $DIGIT.int;}
;
DIGIT : [0-9] ;
Die einfachste Form des Interpreters wird direkt beim Parsen ausgeführt und kommt ohne AST aus.
Der Nachteil ist, dass der AST dabei nicht vorverarbeitet werden kann, insbesondere entfallen
semantische Prüfungen weitgehend.
Über returns [int v] fügt man der Regel expr ein Attribut v (Integer) hinzu, welches
man im jeweiligen Kontext abfragen bzw. setzen kann (agiert als Rückgabewert der generierten
Methode). Auf diesen Wert kann in den Aktionen mit $v zugegriffen werden.
Da in den Alternativen der Regel expr jeweils zwei "Aufrufe" dieser Regel auftauchen, muss
man per "e1=expr" bzw. "e2=expr" eindeutige Namen für die "Aufrufe" vergeben, hier e1
und e2.
Eingebettete Aktionen in ANTLR I
Erinnerung: ANTLR generiert einen LL-Parser, d.h. es wird zu jeder Regel eine entsprechende
Methode generiert.
Analog zum Rückgabewert der Regel (Methode) expr() kann auf die Eigenschaften der Token und
Sub-Regeln zugegriffen werden: $name.eigenschaft. Dabei gibt es bei Token Eigenschaften wie
text (gematchter Text bei Token), type (Typ eines Tokens), int (Integerwert eines Tokens,
entspricht Integer.valueOf($Token.text)). Parser-Regeln haben u.a. ein text-Attribut und
ein spezielles Kontext-Objekt (ctx).
Die allgemeine Form lautet:
rulename[args] returns [retvals] locals [localvars] : ... ;
Dabei werden die in "[...]" genannten Parameter mit Komma getrennt (Achtung: Abhängig von
Zielsprache!).
Beispiel:
add[int x] returns [int r] : '+=' INT {$r = $x + $INT.int;} ;
Eingebettete Aktionen in ANTLR II
@members {
int count = 0;
}
expr returns [int v]
@after {System.out.println(count);}
: e1=expr '*' e2=expr {$v = $e1.v * $e2.v; count++;}
| e1=expr '+' e2=expr {$v = $e1.v + $e2.v; count++;}
| DIGIT {$v = $DIGIT.int;}
;
DIGIT : [0-9] ;
Mit @members { ... } können im generierten Parser weitere Attribute angelegt
werden, die in den Regeln normal genutzt werden können.
Die mit @after markierte Aktion wird am Ende der Regel list ausgeführt. Analog
existiert @init.
ANTLR: Traversierung des AST und Auslesen von Kontext-Objekten
Mit dem obigen Beispiel, welches dem Einsatz einer L-attributierten SDD in ANTLR
entspricht, können einfache Aufgaben bereits beim Parsen erledigt werden.
Für den etwas komplexeren Einsatz von attributierten Grammatiken kann man die von
ANTLR erzeugten Kontext-Objekte für die einzelnen AST-Knoten nutzen und über den
AST mit dem Visitor- oder dem Listener-Pattern iterieren.
Die Techniken sollen im Folgenden kurz vorgestellt werden.
ANTLR: Kontext-Objekte für Parser-Regeln
s : expr {List<EContext> x = $expr.ctx.e();} ;
expr : e '*' e ;
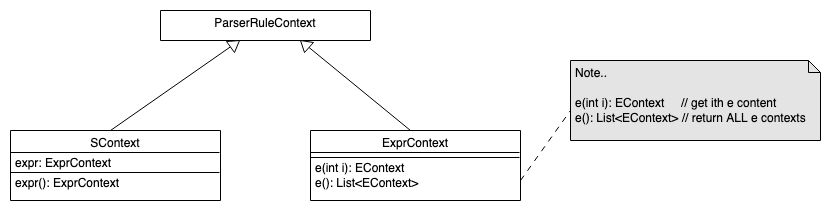
Jede Regel liefert ein passend zu dieser Regel generiertes Kontext-Objekt
zurück. Darüber kann man das/die Kontextobjekt(e) der Sub-Regeln abfragen.
Die Regel s() liefert entsprechend ein SContext-Objekt und die Regel
expr() liefert ein ExprContext-Objekt zurück.
In der Aktion fragt man das Kontextobjekt über ctx ab.
Für einfache Regel-Aufrufe liefert die parameterlose Methode nur ein
einziges Kontextobjekt (statt einer Liste) zurück.
Anmerkung: ANTLR generiert nur dann Felder für die Regel-Elemente im
Kontextobjekt, wenn diese in irgendeiner Form referenziert werden. Dies
kann beispielsweise durch Benennung (Definition eines Labels, siehe nächste
Folie) oder durch Nutzung in einer Aktion (siehe obiges Beispiel) geschehen.
ANTLR: Benannte Regel-Elemente oder Alternativen
stat : 'return' value=e ';' # Return
| 'break' ';' # Break
;
public static class StatContext extends ParserRuleContext { ... }
public static class ReturnContext extends StatContext {
public EContext value;
public EContext e() { ... }
}
public static class BreakContext extends StatContext { ... }
Mit value=e wird der Aufruf der Regel e mit dem Label value belegt,
d.h. man kann mit $e.text oder $value.text auf das text-Attribut von
e zugreifen. Falls es in einer Produktion mehrere Aufrufe einer anderen
Regel gibt, muss man für den Zugriff auf die Attribute eindeutige Label
vergeben.
Analog wird für die beiden Alternativen je ein eigener Kontext erzeugt.
ANTLR: Arbeiten mit dem Listener-Pattern
ANTLR (generiert auf Wunsch) zur Grammatik passende Listener (Interface und
leere Basisimplementierung). Beim Traversieren mit dem Default-ParseTreeWalker
wird der Parse-Tree mit Tiefensuche abgelaufen und jeweils beim Eintritt in
bzw. beim Austritt aus einen/m Knoten der passende Listener mit dem passenden
Kontext-Objekt aufgerufen.
Damit kann man die Grammatik "für sich" halten, d.h. unabhängig von einer
konkreten Zielsprache und die Aktionen über die Listener (oder Visitors, s.u.)
ausführen.
expr : e1=expr '*' e2=expr # MULT
| e1=expr '+' e2=expr # ADD
| DIGIT # ZAHL
;
ANTLR kann zu dieser Grammatik einen passenden Listener (Interface calcListener)
generieren. Weiterhin generiert ANTLR eine leere Basisimplementierung (Klasse
calcBaseListener):

Von dieser Basisklasse leitet man einen eigenen Listener ab und implementiert
die Methoden, die man benötigt.
public static class MyListener extends calcBaseListener {
Stack<Integer> stack = new Stack<Integer>();
public void exitMULT(calcParser.MULTContext ctx) {
int right = stack.pop();
int left = stack.pop();
stack.push(left * right); // {$v = $e1.v * $e2.v;}
}
public void exitADD(calcParser.ADDContext ctx) {
int right = stack.pop();
int left = stack.pop();
stack.push(left + right); // {$v = $e1.v + $e2.v;}
}
public void exitZAHL(calcParser.ZAHLContext ctx) {
stack.push(Integer.valueOf(ctx.DIGIT().getText()));
}
}
Anschließend baut man das alles in eine Traversierung des Parse-Trees ein:
public class TestMyListener {
public static class MyListener extends calcBaseListener {
...
}
public static void main(String[] args) throws Exception {
calcLexer lexer = new calcLexer(CharStreams.fromStream(System.in));
CommonTokenStream tokens = new CommonTokenStream(lexer);
calcParser parser = new calcParser(tokens);
ParseTree tree = parser.s(); // Start-Regel
System.out.println(tree.toStringTree(parser));
ParseTreeWalker walker = new ParseTreeWalker();
MyListener eval = new MyListener();
walker.walk(eval, tree);
System.out.println(eval.stack.pop());
}
}
ANTLR: Arbeiten mit dem Visitor-Pattern
ANTLR (generiert ebenfalls auf Wunsch) zur Grammatik passende Visitoren
(Interface und leere Basisimplementierung). Hier muss man allerdings selbst
für eine geeignete Traversierung des Parse-Trees sorgen. Dafür hat man mehr
Freiheiten im Vergleich zum Listener-Pattern, insbesondere im Hinblick auf
Rückgabewerte.
expr : e1=expr '*' e2=expr # MULT
| e1=expr '+' e2=expr # ADD
| DIGIT # ZAHL
;
ANTLR kann zu dieser Grammatik einen passenden Visitor (Interface calcVisitor<T>)
generieren. Weiterhin generiert ANTLR eine leere Basisimplementierung (Klasse
calcBaseVisitor<T>):

Von dieser Basisklasse leitet man einen eigenen Visitor ab und überschreibt
die Methoden, die man benötigt. Wichtig ist, dass man selbst für das "Besuchen"
der Kindknoten sorgen muss (rekursiver Aufruf der geerbten Methode visit()).
public static class MyVisitor extends calcBaseVisitor<Integer> {
public Integer visitMULT(calcParser.MULTContext ctx) {
return visit(ctx.e1) * visit(ctx.e2); // {$v = $e1.v * $e2.v;}
}
public Integer visitADD(calcParser.ADDContext ctx) {
return visit(ctx.e1) + visit(ctx.e2); // {$v = $e1.v + $e2.v;}
}
public Integer visitZAHL(calcParser.ZAHLContext ctx) {
return Integer.valueOf(ctx.DIGIT().getText());
}
}
Anschließend baut man das alles in eine manuelle Traversierung des Parse-Trees ein:
public class TestMyVisitor {
public static class MyVisitor extends calcBaseVisitor<Integer> {
...
}
public static void main(String[] args) throws Exception {
calcLexer lexer = new calcLexer(CharStreams.fromStream(System.in));
CommonTokenStream tokens = new CommonTokenStream(lexer);
calcParser parser = new calcParser(tokens);
ParseTree tree = parser.s(); // Start-Regel
System.out.println(tree.toStringTree(parser));
MyVisitor eval = new MyVisitor();
System.out.println(eval.visit(tree));
}
}
Wrap-Up
-
Interpreter simulieren die Programmausführung
-
Syntaxgesteuerter Interpreter (attributierte Grammatiken)
-
Beispiel ANTLR: Eingebettete Aktionen, Kontextobjekte, Visitors/Listeners (AST-Traversierung)
AST-basierte Interpreter: Basics
TL;DR
Ein AST-basierter Interpreter besteht oft aus einem "Visitor-Dispatcher": Man traversiert
mit einer eval()-Funktion den AST und ruft je nach Knotentyp die passende Funktion auf.
Dabei werden bei Ausdrücken (Expressions) Werte berechnet und zurückgegeben, d.h. hier
hat man einen Rückgabewert und ein entsprechendes return im switch/case, während man
bei Anweisungen (Statements) keinen Rückgabewert hat.
Der Wert von Literalen ergibt sich direkt durch die Übersetzung des jeweiligen Werts in den
passenden Typ der Implementierungssprache. Bei einfachen Ausdrücken kann man auf das in
Syntaxgesteuerte Interpreter
demonstrierte Vorgehen zurückgreifen: Man interpretiert zunächst die Teilausdrücke durch den
Aufruf von eval() für die jeweiligen AST-Kindknoten und berechnet daraus das gewünschte
Ergebnis.
Für Blöcke und Variablen muss man analog zum Aufbau von Symboltabellen wieder Scopes
berücksichtigen, d.h. man benötigt Strukturen ähnlich zu den Symboltabellen (hier "Umgebung"
(Environment) genannt). Es gibt eine globale Umgebung, und mit dem Betreten eines neuen
Blocks wird eine neue Umgebung aufgemacht, deren Eltern-Umgebung die bisherige Umgebung ist.
Zu jedem Namen kann man in einer Umgebung einen Wert definieren bzw. abrufen. Dabei muss man
je nach Semantik der zu interpretierenden Sprache unterscheiden zwischen der "Definition" und
der "Zuweisung" einer Variablen: Die Definition erfolgt i.d.R. in der aktuellen Umgebung, bei
der Zuweisung sucht man ausgehend von der aktuellen Umgebung bis hoch zur globalen Umgebung
nach dem ersten Vorkommen der Variablen und setzt den Wert in der gefundenen Umgebung. Bei
Sprachen, die Variablen beim ersten Zugriff definieren, muss man dieses Verhalten entsprechend
anpassen.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Traversierung von Parse-Trees und Implementierung von Aktionen mit Hilfe des Visitor-Patterns
- (K3) Interpreter müssen Namen und Werte speichern: Environment-Strukturen analog zu den Symboltabellen
- (K3) Code-Ausführung im Interpreter durch eine Read-Eval-Schleife: Implementierung mit einem Visitor
Aufgaben im Interpreter
Im Allgemeinen reichen einfache syntaxgesteuerte Interpreter nicht aus. Normalerweise simuliert
ein Interpreter die Ausführung eines Programms durch den Computer. D.h. der Interpreter muss
über die entsprechenden Eigenschaften verfügen: Prozessor, Code-Speicher, Datenspeicher, Stack ...
int x = 42;
int f(int x) {
int y = 9;
return y+x;
}
x = f(x);
-
Aufbauen des AST ... => Lexer+Parser
-
Auflösen von Symbolen/Namen ... => Symboltabellen, Resolving
-
Type-Checking und -Inference ... => Semantische Analyse (auf Symboltabellen)
-
Speichern von Daten: Name+Wert vs. Adresse+Wert (Erinnerung: Data-Segment und Stack im virtuellen Speicher)
-
Ausführen von Anweisungen Text-Segment im virtuellen Speicher; hier über den AST
-
Aufruf von Funktionen und Methoden Kontextwechsel nötig: Was ist von wo aus sichtbar?
AST-basierte Interpreter: Visitor-Dispatcher
def eval(self, AST t):
if t.type == Parser.BLOCK : block(t)
elif t.type == Parser.ASSIGN : assign(t)
elif t.type == Parser.RETURN : ret(t)
elif t.type == Parser.IF : ifstat(t)
elif t.type == Parser.CALL : return call(t)
elif t.type == Parser.ADD : return add(t)
elif t.type == Parser.MUL : return mul(t)
elif t.type == Parser.INT : return Integer.parseInt(t.getText())
elif t.type == Parser.ID : return load(t)
else : ... # catch unhandled node types
return None;
Nach dem Aufbau des AST durch Scanner und Parser und der semantischen Analyse
anhand der Symboltabellen müssen die Ausdrücke (expressions) und Anweisungen
(statements) durch den Interpreter ausgewertet werden. Eine Möglichkeit dazu
ist das Traversieren des AST mit dem Visitor-Pattern. Basierend auf dem Typ
des aktuell betrachteten AST-Knotens wird entschieden, wie damit umgegangen
werden soll. Dies erinnert an den Aufbau der Symboltabellen ...
Die eval()-Methode bildet das Kernstück des (AST-traversierenden) Interpreters.
Hier wird passend zum aktuellen AST-Knoten die passende Methode des Interpreters
aufgerufen.
Hinweis: Im obigen Beispiel wird nicht zwischen der Auswertung von
Ausdrücken und Anweisungen unterschieden, es wird die selbe Methode eval()
genutzt. Allerdings liefern Ausdrücke einen Wert zurück (erkennbar am return
im jeweiligen switch/case-Zweig), während Anweisungen keinen Wert liefern.
In den folgenden Beispielen wird davon ausgegangen, dass ein komplettes
Programm eingelesen, geparst, vorverarbeitet und dann interpretiert wird.
Für einen interaktiven Interpreter würde man in einer Schleife die Eingaben
lesen, parsen und vorverarbeiten und dann interpretieren. Dabei würde jeweils
der AST und die Symboltabelle ergänzt, damit die neuen Eingaben auf frühere
verarbeitete Eingaben zurückgreifen können. Durch die Form der Schleife
"Einlesen -- Verarbeiten -- Auswerten" hat sich auch der Name "Read-Eval-Loop"
bzw. "Read-Eval-Print-Loop" (REPL) eingebürgert.
Auswertung von Literalen und Ausdrücken
-
Typen mappen: Zielsprache => Implementierungssprache
Die in der Zielsprache verwendeten (primitiven) Typen müssen
auf passende Typen der Sprache, in der der Interpreter selbst
implementiert ist, abgebildet werden.
Beispielsweise könnte man den Typ nil der Zielsprache auf den
Typ null des in Java implementierten Interpreters abbilden, oder
den Typ number der Zielsprache auf den Typ Double in Java
mappen.
-
Literale auswerten:
elif t.type == Parser.INT : return Integer.parseInt(t.getText())
Das ist der einfachste Teil ... Die primitiven Typen der
Zielsprache, für die es meist ein eigenes Token gibt, müssen
als Datentyp der Interpreter-Programmiersprache ausgewertet
werden.
-
Ausdrücke auswerten:
add: e1=expr "+" e2=expr ;
def add(self, AST t):
lhs = eval(t.e1())
rhs = eval(t.e2())
return (double)lhs + (double)rhs # Semantik!
Die meisten möglichen Fehlerzustände sind bereits durch den Parser
und bei der semantischen Analyse abgefangen worden. Falls zur Laufzeit
die Auswertung der beiden Summanden keine Zahl ergibt, würde eine
Java-Exception geworfen, die man an geeigneter Stelle fangen und
behandeln muss. Der Interpreter soll sich ja nicht mit einem Stack-Trace
verabschieden, sondern soll eine Fehlermeldung präsentieren und danach
normal weiter machen ...
Kontrollstrukturen
ifstat: 'if' expr 'then' s1=stat ('else' s2=stat)? ;
def ifstat(self, AST t):
if eval(t.expr()): eval(t.s1())
else:
if t.s2(): eval(t.s2())
Analog können die anderen bekannten Kontrollstrukturen umgesetzt werden,
etwa switch/case, while oder for.
Dabei können erste Optimierungen vorgenommen werden: Beispielsweise könnten
for-Schleifen im Interpreter in while-Schleifen transformiert werden,
wodurch im Interpreter nur ein Schleifenkonstrukt implementiert werden
müsste.
Zustände: Auswerten von Anweisungen
int x = 42;
float y;
{
int x;
x = 1;
y = 2;
{ int y = x; }
}
Das erinnert nicht nur zufällig an den Aufbau der Symboltabellen :-)
Und so lange es nur um Variablen ginge, könnte man die Symboltabellen für das
Speichern der Werte nutzen. Allerdings müssen wir noch Funktionen und Strukturen
bzw. Klassen realisieren, und spätestens dann kann man die Symboltabelle nicht
mehr zum Speichern von Werten einsetzen. Also lohnt es sich, direkt neue
Strukturen für das Halten von Variablen und Werten aufzubauen.
Detail: Felder im Interpreter
Eine mögliche Implementierung für einen Interpreter basierend auf einem
ANTLR-Visitor ist nachfolgend gezeigt.
Hinweis: Bei der Ableitung des BaseVisitor<T> muss der Typ T
festgelegt werden. Dieser fungiert als Rückgabetyp für die Visitor-Methoden.
Entsprechend können alle Methoden nur einen gemeinsamen (Ober-) Typ zurückliefern,
weshalb man sich an der Stelle oft mit Object behilft und dann manuell
den konkreten Typ abfragen und korrekt casten muss.
class Interpreter(BaseVisitor<Object>):
__init__(self, AST t):
BaseVisitor<Object>.__init__(self)
self.root = t
self.env = Environment()
Quelle: Eigener Code basierend auf einer Idee nach Interpreter.java by Bob Nystrom on Github.com (MIT)
Ausführen einer Variablendeklaration
varDecl: "var" ID ("=" expr)? ";" ;
def varDecl(self, AST t):
# deklarierte Variable (String)
name = t.ID().getText()
value = None; # TODO: Typ der Variablen beachten (Defaultwert)
if t.expr(): value = eval(t.expr())
self.env.define(name, value)
return None
Wenn wir bei der Traversierung des AST mit eval() bei einer Variablendeklaration
vorbeikommen, also etwa int x; oder int x = wuppie + fluppie;, dann wird im
aktuellen Environment der String "x" sowie der Wert (im zweiten Fall) eingetragen.
Ausführen einer Zuweisung
def assign(self, AST t):
lhs = t.ID().getText()
value = eval(t.expr())
self.env.assign(lhs, value) # Semantik!
}
class Environment:
def assign(self, String n, Object v):
if self.values[n]: self.values[n] = v
elif self.enclosing: self.enclosing.assign(n, v)
else: raise RuntimeError(n, "undefined variable")
Quelle: Eigener Code basierend auf einer Idee nach Environment.java by Bob Nystrom on Github.com (MIT)
Wenn wir bei der Traversierung des AST mit eval() bei einer Zuweisung
vorbeikommen, also etwa x = 7; oder x = wuppie + fluppie;, dann wird
zunächst im aktuellen Environment die rechte Seite der Zuweisung ausgewertet
(Aufruf von eval()). Anschließend wird der Wert für die Variable im
Environment eingetragen: Entweder sie wurde im aktuellen Environment früher
bereits definiert, dann wird der neue Wert hier eingetragen. Ansonsten wird
entlang der Verschachtelungshierarchie gesucht und entsprechend eingetragen.
Falls die Variable nicht gefunden werden kann, wird eine Exception ausgelöst.
An dieser Stelle kann man über die Methode assign in der Klasse Environment
dafür sorgen, dass nur bereits deklarierte Variablen zugewiesen werden dürfen.
Wenn man stattdessen wie etwa in Python das implizite Erzeugen neuer
Variablen erlaubten möchte, würde man statt Environment#assign einfach
Environment#define nutzen ...
Anmerkung: Der gezeigte Code funktioniert nur für normale Variablen, nicht
für Zugriffe auf Attribute einer Struct oder Klasse!
Blöcke: Umgang mit verschachtelten Environments
def block(self, AST t):
prev = self.env
try:
self.env = Environment(self.env)
for s in t.stat(): eval(s)
finally: self.env = prev
return None;
Quelle: Eigener Code basierend auf einer Idee nach Interpreter.java by Bob Nystrom on Github.com (MIT)
Beim Interpretieren von Blöcken muss man einfach nur eine weitere
Verschachtelungsebene für die Environments anlegen und darin dann
die Anweisungen eines Blockes auswerten ...
Wichtig: Egal, was beim Auswerten der Anweisungen in einem Block
passiert: Es muss am Ende die ursprüngliche Umgebung wieder hergestellt
werden (finally-Block).
Wrap-Up
-
Interpreter simulieren die Programmausführung
- Namen und Symbole auflösen
- Speicherbereiche simulieren
- Code ausführen: Read-Eval-Loop
-
Traversierung des AST: eval(AST t) als Visitor-Dispatcher
-
Scopes mit Environment (analog zu Symboltabellen)
-
Interpretation von Blöcken und Variablen (Deklaration, Zuweisung)
Quellen
- [Grune2012] Modern Compiler Design
Grune, D. und van, Reeuwijk, K. und Bal, H. E. und Jacobs, C. J. H. und Langendoen, K., Springer, 2012. ISBN 978-1-4614-4698-9.
Kapitel 6 - [Mogensen2017] Introduction to Compiler Design
Mogensen, T., Springer, 2017. ISBN 978-3-319-66966-3. DOI 10.1007/978-3-319-66966-3.
Kapitel 4 - [Nystrom2021] Crafting Interpreters
Nystrom, R., Genever Benning, 2021. ISBN 978-0-9905829-3-9.
Kapitel Kapitel: A Tree-Walk Interpreter, insb. 8. Statements and State
AST-basierte Interpreter: Funktionen und Klassen
TL;DR
Üblicherweise können Funktionen auf die Umgebung zurückgreifen, in der die Definition der
Funktion erfolgt ist ("Closure").
Deshalb wird beim Interpretieren einer Funktionsdefinition der jeweilige AST-Knoten (mit
dem Block des Funktionskörpers) und die aktuelle Umgebung in einer Struktur zusammengefasst.
Zusätzlich muss in der aktuellen Umgebung der Name der Funktion zusammen mit der eben erzeugten
Struktur ("Funktionsobjekt") als Wert definiert werden.
Beim Funktionsaufruf löst man den Funktionsnamen in der aktuellen Umgebung auf und erhält
das Funktionsobjekt mit dem AST der Funktion und der Closure. Die Funktionsparameter werden
ebenfalls in der aktuellen Umgebung aufgelöst (Aufruf von eval() für die AST-Kindknoten
des Funktionsaufrufs). Zur Interpretation der Funktion legt man sich eine neue Umgebung an,
deren Eltern-Umgebung die Closure der Funktion ist, definiert die Funktionsparameter (Name
und eben ermittelter Wert) in dieser neuen Umgebung und interpretiert dann den AST-Kindknoten
des Funktionsblocks in dieser neuen Umgebung. Für den Rückgabewert muss man ein wenig tricksen:
Ein Block hat normalerweise keinen Wert. Eine Möglichkeit wäre, bei der Interpretation eines
return-Statements eine Exception mit dem Wert des Ausdruck hinter dem "return" zu werfen
und im eval() des Funktionsblock zu fangen.
Für Klassen kann man analog verfahren. Methoden sind zunächst einfach Funktionen, die in einem
Klassenobjekt gesammelt werden. Das Erzeugen einer Instanz einer Klasse ist die Interpretation
eines "Aufrufs" der Klasse (analog zum Aufruf einer Funktion): Dabei wird ein spezielles
Instanzobjekt erzeugt, welches auf die Klasse verweist und welches die Werte der Attribute hält.
Beim Aufruf von Methoden auf einem Instanzobjekt wird der Name der Funktion über das Klassenobjekt
aufgelöst, eine neue Umgebung erzeugt mit der Closure der Funktion als Eltern-Umgebung und das
Instanzobjekt wird in dieser Umgebung definiert als "this" oder "self". Anschließend wird
ein neues Funktionsobjekt mit der eben erzeugten Umgebung und dem Funktions-AST erzeugt und
zurückgeliefert. Dieses neue Funktionsobjekt wird dann wie eine normale Funktion aufgerufen
(interpretiert, s.o.). Der Zugriff in der Methode auf die Attribute der Klasse erfolgt dann
über this bzw. self, welche in der Closure der Funktion nun definiert sind und auf das
Instanzobjekt mit den Attributen verweisen.
Videos (HSBI-Medienportal)
Lernziele
- (K3) Traversierung von Parse-Trees und Implementierung von Aktionen mit Hilfe des Visitor-Patterns
- (K3) Interpreter müssen Namen und Werte speichern: Environment-Strukturen analog zu den Symboltabellen
- (K3) Code-Ausführung im Interpreter durch eine Read-Eval-Schleife: Implementierung mit einem Visitor
Funktionen
int foo(int a, int b, int c) {
print a + b + c;
}
foo(1, 2, 3);
def makeCounter():
var i = 0
def count():
i = i + 1
print i
return count;
counter = makeCounter()
counter() # "1"
counter() # "2"
Die Funktionsdeklaration muss im aktuellen Kontext abgelegt werden,
dazu wird der AST-Teilbaum der Deklaration benötigt.
Beim Aufruf muss man das Funktionssymbol im aktuellen Kontext
suchen, die Argumente auswerten, einen neuen lokalen Kontext
anlegen und darin die Parameter definieren (mit den eben ausgewerteten
Werten) und anschließend den AST-Teilbaum des Funktionskörpers im
Interpreter mit eval() auswerten ...
Ausführen einer Funktionsdeklaration
funcDecl : type ID '(' params? ')' block ;
funcCall : ID '(' exprList? ')' ;
def funcDecl(self, AST t):
fn = Fun(t, self.env)
self.env.define(t.ID().getText(), fn)
Quelle: Eigener Code basierend auf einer Idee nach LoxFunction.java by Bob Nystrom on Github.com (MIT)
Man definiert im aktuellen Environment den Funktionsnamen und hält dazu
den aktuellen Kontext (aktuelles Environment) sowie den AST-Knoten mit
der eigentlichen Funktionsdefinition fest.
Für Closures ist der aktuelle Kontext wichtig, sobald man die
Funktion ausführen muss. In [Parr2010, S.236] wird beispielsweise
einfach nur ein neuer Memory-Space (entspricht ungefähr hier einem
neuen lokalen Environment) angelegt, in dem die im Funktionskörper
definierten Symbole angelegt werden. Die Suche nach Symbolen erfolgt
dort nur im Memory-Space (Environment) der Funktion bzw. im globalen
Scope (Environment).
Ausführen eines Funktionsaufrufs
funcDecl : type ID '(' params? ')' block ;
funcCall : ID '(' exprList? ')' ;
def funcCall(self, AST t):
fn = (Fun)eval(t.ID())
args = [eval(a) for a in t.exprList()]
prev = self.env; self.env = Environment(fn.closure)
for i in range(args.size()):
self.env.define(fn.decl.params()[i].getText(), args[i])
eval(fn.decl.block())
self.env = prev
Quelle: Eigener Code basierend auf einer Idee nach LoxFunction.java by Bob Nystrom on Github.com (MIT)
Zunächst wird die ID im aktuellen Kontext ausgewertet. In der obigen Grammatik
ist dies tatsächlich nur ein Funktionsname, aber man könnte über diesen Mechanismus
auch Ausdrücke erlauben und damit Funktionspointer bzw. Funktionsreferenzen
realisieren ... Im Ergebnis hat man das Funktionsobjekt mit dem zugehörigen AST-Knoten
und dem Kontext zur Deklarationszeit.
Die Argumente der Funktion werden nacheinander ebenfalls im aktuellen Kontext
ausgewertet.
Um den Funktionsblock auszuwerten, legt man einen neuen temporären Kontext über
dem Closure-Kontext der Funktion an und definiert darin die Parameter der Funktion
samt den aktuellen Werten. Dann lässt man den Interpreter über den Visitor-Dispatch
den Funktionskörper evaluieren und schaltet wieder auf den Kontext vor der
Funktionsauswertung zurück.
Funktionsaufruf: Rückgabewerte
def funcCall(self, AST t):
...
eval(fn.decl.block())
...
return None # (Wirkung)
class ReturnEx(RuntimeException):
__init__(self, v): self.value = v
def return(self, AST t):
raise ReturnEx(eval(t.expr()))
def funcCall(self, AST t):
...
erg = None
try: eval(fn.decl.block())
except ReturnEx as r: erg = r.value
...
return erg;
Quelle: Eigener Code basierend auf einer Idee nach Return.java und LoxFunction.java by Bob Nystrom on Github.com (MIT)
Rückgabewerte für den Funktionsaufruf werden innerhalb von block berechnet,
wo eine Reihe von Anweisungen interpretiert werden, weshalb block ursprünglich
keinen Rückgabewert hat. Im Prinzip könnte man block etwas zurück geben lassen,
was durch die möglicherweise tiefe Rekursion relativ umständlich werden kann.
An dieser Stelle kann man den Exceptions-Mechanismus missbrauchen und bei
der Auswertung eines return mit dem Ergebniswert direkt zum Funktionsaufruf
zurück springen. In Methoden, wo man einen neuen lokalen Kontext anlegt und
die globale env-Variable temporär damit ersetzt, muss man dann ebenfalls
mit try/catch arbeiten und im finally-Block die Umgebung zurücksetzen und
die Exception erneut werfen.
Native Funktionen
class Callable:
def call(self, Interpreter i, List<Object> a): pass
class Fun(Callable): ...
class NativePrint(Fun):
def call(self, Interpreter i, List<Object> a):
for o in a: print a # nur zur Demo, hier sinnvoller Code :-)
# Im Interpreter (Initialisierung):
self.env.define("print", NativePrint())
def funcCall(self, AST t):
...
# prev = self.env; self.env = Environment(fn.closure)
# for i in range(args.size()): ...
# eval(fn.decl.block()); self.env = prev
fn.call(self, args)
...
Quelle: Eigener Code basierend auf einer Idee nach LoxCallable.java und LoxFunction.java by Bob Nystrom on Github.com (MIT)
Normalerweise wird beim Interpretieren eines Funktionsaufrufs der
Funktionskörper (repräsentiert durch den entsprechenden AST-Teilbaum)
durch einen rekursiven Aufruf von eval ausgewertet.
Für native Funktionen, die im Interpreter eingebettet sind, klappt
das nicht mehr, da hier kein AST vorliegt.
Man erstellt ein neues Interface Callable mit der Hauptmethode call()
und leitet die frühere Klasse Fun davon ab: class Fun(Callable).
Die Methode funcCall() des Interpreters ruft nun statt der eval()-Methode
die call()-Methode des Funktionsobjekts auf und übergibt den Interpreter
(== Zustand) und die Argumente. Die call()-Methode der Klasse Fun muss
nun ihrerseits im Normalfall den im Funktionsobjekt referenzierten AST-Teilbaum
des Funktionskörpers mit dem Aufruf von eval() interpretieren ...
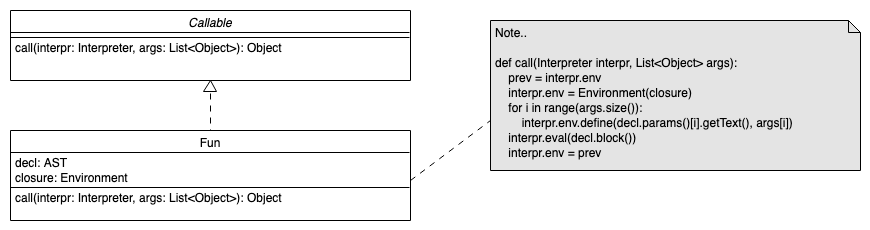
Für die nativen Funktionen leitet man einfach eine (anonyme) Klasse
ab und speichert sie unter dem gewünschten Namen im globalen Kontext
des Interpreters. Die call()-Methode wird dann entsprechend der
gewünschten Funktion implementiert, d.h. hier erfolgt kein weiteres
Auswerten des AST.
Klassen und Instanzen I
classDef : "class" ID "{" funcDecl* "}" ;
def classDef(self, AST t):
methods = HashMap<String, Fun>()
for m in t.funcDecl():
fn = Fun(m, self.env)
methods[m.ID().getText()] = fn
clazz = Clazz(methods)
self.env.define(t.ID().getText(), clazz)
Quelle: Eigener Code basierend auf einer Idee nach Interpreter.java by Bob Nystrom on Github.com (MIT)
Anmerkung: In dieser Darstellung wird der Einfachheit halber nur auf Methoden eingegangen.
Für Attribute müssten ähnliche Konstrukte implementiert werden.
Klassen und Instanzen II
class Clazz(Callable):
__init__(self, Map<String, Fun> methods):
self.methods = methods
def call(self, Interpreter i, List<Object> a):
return Instance(self)
def findMethod(self, String name):
return self.methods[name]
class Instance:
__init__(self, Clazz clazz):
self.clazz = clazz
def get(self, String name):
method = self.clazz.findMethod(name)
if method != None: return method.bind(self)
raise RuntimeError(name, "undefined method")
Quelle: Eigener Code basierend auf einer Idee nach LoxClass.java und LoxInstance.java by Bob Nystrom on Github.com (MIT)
Instanzen einer Klasse werden durch den funktionsartigen "Aufruf" der Klassen
angelegt (parameterloser Konstruktor). Eine Instanz hält die Attribute (hier
nicht gezeigt) und eine Referenz auf die Klasse, um später an die Methoden
heranzukommen.
Zugriff auf Methoden (und Attribute)
def getExpr(self, AST t):
obj = eval(t.obj())
if isinstance(obj, Instance):
return ((Instance)obj).get(t.ID().getText())
raise RuntimeError(t.obj().getText(), "no object")
Beim Zugriff auf Attribute muss das Objekt im aktuellen Kontext evaluiert
werden. Falls es eine Instanz von Instance ist, wird auf das Feld per
interner Hash-Map zugriffen; sonst Exception.
Methoden und this oder self
class Fun(Callable):
def bind(self, Instance i):
e = Environment(self.closure)
e.define("this", i)
e.define("self", i)
return Fun(self.decl, e)
Quelle: Eigener Code basierend auf einer Idee nach LoxFunction.java by Bob Nystrom on Github.com (MIT)
Nach dem Interpretieren von Klassendefinitionen sind die Methoden in der Klasse
selbst gespeichert, wobei der jeweilige closure auf den Klassenkontext zeigt.
Beim Auflösen eines Methodenaufrufs wird die gefundene Methode an die
Instanz gebunden, d.h. es wird eine neue Funktion angelegt, deren closure
auf den Kontext der Instanz zeigt. Zusätzlich wird in diesem Kontext noch die
Variable "this" definiert, damit man damit auf die Instanz zugreifen kann.
In Python wird das in der Methodensignatur sichtbar: Der erste Parameter ist
eine Referenz auf die Instanz, auf der diese Methode ausgeführt werden soll ...
Wrap-Up
-
Interpreter simulieren die Programmausführung
- Namen und Symbole auflösen
- Speicherbereiche simulieren
- Code ausführen: Read-Eval-Loop
-
Traversierung des AST: eval(AST t) als Visitor-Dispatcher
-
Scopes mit Environment (analog zu Symboltabellen)
-
Interpretation von Funktionen (Deklaration/Aufruf, native Funktionen)
-
Interpretation von Klassen und Instanzen
Challenges
- Wie interpretiert man Code?
- Warum kann man die Werte nicht einfach in Symboltabellen ablegen?
- Wie geht man mit Funktionen um? Warum? Kann man diese mehrfach aufrufen?
- Wieso erzeugt man eine neue Environment mit der Closure in der Funktion?
- Wie gehen native Funktionen?
Betrachten Sie folgenden Code-Ausschnitt:
int x = 42;
int f(int x) {
int y = 9;
return y+x;
}
x = f(x);
- Geben Sie den AST an.
- Stellen Sie die Strukturen der Symboltabelle dar.
- Stellen Sie die Strukturen im Interpreter dar.
Quellen
- [Grune2012] Modern Compiler Design
Grune, D. und van, Reeuwijk, K. und Bal, H. E. und Jacobs, C. J. H. und Langendoen, K., Springer, 2012. ISBN 978-1-4614-4698-9.
Kapitel 6 - [Mogensen2017] Introduction to Compiler Design
Mogensen, T., Springer, 2017. ISBN 978-3-319-66966-3. DOI 10.1007/978-3-319-66966-3.
Kapitel 4 - [Nystrom2021] Crafting Interpreters
Nystrom, R., Genever Benning, 2021. ISBN 978-0-9905829-3-9.
Kapitel Kapitel: A Tree-Walk Interpreter, insb. 10. Functions u. 12. Classes - [Parr2010] Language Implementation Patterns
Parr, T., Pragmatic Bookshelf, 2010. ISBN 978-1-9343-5645-6.

