Auf die lexikalische Analyse und die Syntaxanalyse folgt die semantische Analyse. Nach dem
Parsen steht fest, dass ein Programm syntaktisch korrekt ist. Nun muss geprüft werden, ob
es auch semantisch korrekt ist. Dazu gehören u.a. die Identifikation und Sammlung von
Bezeichnern und die Zuordnung zur richtigen Ebene (Scopes) sowie die die Typ-Prüfung
und -Inferenz.
In dieser Phase zeigen sich die Eigenschaften der zu verarbeitenden Sprache sehr deutlich,
beispielsweise müssen Bezeichner deklariert sein vor der ersten Benutzung, welche Art von
Scopes soll es geben, gibt es Klassen und Vererbung ...
Da hier der Kontext der Symbole eine Rolle spielt, wird diese Phase oft auch "Context Handling"
oder "Kontext Analyse" bezeichnet. Neben attributierten Grammatiken sind die Symboltabellen
wichtige Werkzeuge.
expr : expr '+' term
| term
;
term : term '*' DIGIT
| DIGIT
;
DIGIT : [0-9] ;
=> Wie den Ausdruck ausrechnen?
Anmerkung: Heute geht es um die einfachste Form der semantischen Analyse: Anreichern einer Grammatik um
Attribute und Aktionen, die während des Parsens oder bei der Traversierung des Parse-Trees ausgewertet
werden.
Semantische Analyse
Das haben wir bis jetzt
Wir haben den AST vorliegen.
Idealerweise enthält er bei jedem Bezeichner einen Verweis in sogenannte Symboltabellen (siehe spätere Veranstaltung).
Was kann beim Parsen schon überprüft / bestimmt werden?
Hier entsteht ein Tafelbild.
Was fehlt jetzt noch?
Kontextsensitive Analysen
Hier entsteht ein Tafelbild.
Analyse von Datentypen
Typisierung
stark oder statisch typisierte Sprachen: Alle oder fast alle Typüberprüfungen finden in der semantischen Analyse statt (C, C++, Java)
schwach oder dynamisch typisierte Sprachen: Alle oder fast alle Typüberprüfungen finden zur Laufzeit statt (Python, Lisp, Perl)
(Wenn f den Typ $s \rightarrow t$ hat und x den Typ s,
dann hat der Ausdruck f(x) den Typ t.)
z. B. zur Auflösung von Überladung und Polymorphie zur Laufzeit
Statische Typprüfungen
Bsp.: Der + - Operator:
Typ 1. Operand
Typ 2. Operand
Ergebnistyp
int
int
int
float
float
float
int
float
float
float
int
float
string
string
string
Typkonvertierungen
Der Compiler kann implizite Typkonvertierungen vornehmen, um einen Ausdruck zu verifizieren (siehe Sprachdefiniton)
Typerweiterungen, z.B. von int nach float oder
Bestimmung des kleinsten umschließenden Typ vorliegender Typen
Type Casts: explizite Typkonvertiereungen
Nicht grundsätzlich statisch mögliche Typprüfungen
Bsp.: Der ^-Operator $(a^b)$:
Typ 1. Operand
Typ 2. Operand
Ergebnistyp
int
int $\geq$ 0
int
int
int < 0
float
int
float
float
$\ldots$
$\ldots$
$\ldots$
Attributierte Grammatiken
Was man damit macht
Die Syntaxanalyse kann keine kontextsensitiven Analysen durchführen
Kontextsensitive Grammatiken benutzen: Laufzeitprobleme, das Parsen von cs-Grammatiken ist PSPACE-complete
Parsergenerator Bison: generiert LALR(1)-Parser, aber auch sog. Generalized LR (GLR) Parser, die bei nichtlösbaren Konflikten in der Grammatik (Reduce/Reduce oder Shift/Reduce) parallel den Input mit jede der Möglichkeiten weiterparsen
Anderer Ansatz: Berücksichtigung kontextsensitiver Abhängigkeiten mit Hilfe attributierter Grammatiken, zur Typanalyse, auch zur Codegenerierung
Weitergabe von Informationen im Baum
Syntax-gesteuerte Übersetzung: Attribute und Aktionen
Berechnen der Ausdrücke
expr : expr '+' term ;
translate expr ;
translate term ;
handle + ;
Attributierte Grammatiken (SDD)
auch "syntax-directed definition"
Anreichern einer CFG:
Zuordnung einer Menge von Attributen zu den Symbolen (Terminal- und Nicht-Terminal-Symbole)
Zuordnung einer Menge von semantischen Regeln (Evaluationsregeln) zu den Produktionen
Definition: Attributierte Grammatik
Eine attributierte GrammatikAG = (G,A,R) besteht aus folgenden Komponenten:
Mengen A(X) der Attribute eines Nonterminals X
G = (N, T, P, S) ist eine cf-Grammatik
A = $\bigcup\limits_{X \in (T \cup N)} A(X)$ mit $A(X) \cap A(Y) \neq \emptyset \Rightarrow X = Y$
R = $\bigcup\limits_{p \in P} R(p)$ mit $R(p) = \lbrace X_i.a = f(\ldots) \vert p : X_0 \rightarrow X_1 \ldots X_n \in P, X_i.a \in A(X_i), 0 \leq i \leq n\rbrace$
Abgeleitete und ererbte Attribute
Die in einer Produktion p definierten Attribute sind
AF(p) = $\lbrace X_i.a \ \vert\ p : X_0 \rightarrow X_1 \ldots X_n \in P, 0 \leq i \leq n, X_i.a = f(\ldots) \in R(p)\rbrace$
Disjunkte Teilmengen der Attribute: abgeleitete (synthesized) Attributen AS(X) und ererbte (inherited) Attributen AI(X):
AS(X) = $\lbrace X.a\ \vert \ \exists p : X \rightarrow X_1 \ldots X_n \in P, X.a \in AF(p)\rbrace$
Abgeleitete Attribute geben Informationen von unten nach oben weiter, geerbte von oben nach unten.
Abhängigkeitsgraphen stellen die Abhängigkeiten der Attribute dar.
Beispiel: Attributgrammatiken
Produktion
Semantische Regel
e : e1 '+' t ;
e.val = e1.val + t.val
e : t ;
e.val = t.val
t : t1 '*' D ;
t.val = t1.val * D.lexval
t : D ;
t.val = D.lexval
Produktion
Semantische Regel
t : D t' ;
t'.inh = D.lexval
t.syn = t'.syn
t' : '*' D t'1 ;
t'1.inh = t'.inh * D.lexval
t'.syn = t'1.syn
t' :$\epsilon$;
t'.syn = t'.inh
Wenn ein Nichtterminal mehr als einmal in einer Produktion vorkommt, werden die Vorkommen nummeriert. (t, t1; t', t'1)
S-Attributgrammatiken und L-Attributgrammatiken
S-Attributgrammatiken
S-Attributgrammatiken: Grammatiken mit nur abgeleiteten Attributen, lassen sich während des Parsens mit LR-Parsern beim Reduzieren berechnen (Tiefensuche mit Postorder-Evaluation):
defvisit(N):
for each child C of N (from left to right):
visit(C)
eval(N) # evaluate attributes of N
L-Attributgrammatiken
Grammatiken, deren geerbte Atribute nur von einem Elternknoten oder einem linken Geschwisterknoten abhängig sind
können während des Parsens mit LL-Parsern berechnet werden
alle Kanten im Abhängigkeitsgraphen gehen nur von links nach rechts
ein Links-Nach-Rechts-Durchlauf ist ausreichend
S-attributierte SDD sind eine Teilmenge von L-attributierten SDD
Beispiel: S-Attributgrammatik
Produktion
Semantische Regel
e : e1 '+' t ;
e.val = e1.val + t.val
e : t ;
e.val = t.val
t : t1 '*' D ;
t.val = t1.val * D.lexval
t : D ;
t.val = D.lexval
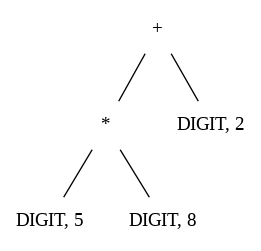
Beispiel: Annotierter Syntaxbaum für 5*8+2
Annotierter Parse-Tree
Erzeugung des AST aus dem Parse-Tree für 5*8+2
Produktion
Semantische Regel
e : e1 '+' t ;
e.node = new Node('+', e1.node, t.node)
e : t ;
e.node = t.node
t : t1 '*' D ;
t.node = new Node('*', t1.node, new Leaf(D, D.lexval));
t : D ;
t.node = new Leaf(D, D.lexval);
AST
Beispiel: L-Attributgrammatik, berechnete u. geerbte Attribute, ohne Links-Rekursion
Teil der vorigen SDD zum Parsen und Berechnen von Ausdrücken wie 5*8+2, hier umformuliert ohne Links-Rekursion
und mit berechneten und geerbten Attributen:
Produktion
Semantische Regel
t : D t' ;
t'.inh = D.lexval
t.syn = t'.syn
t' : '*' D t'1 ;
t'1.inh = t'.inh * D.lexval
t'.syn = t'1.syn
t' :$\epsilon$;
t'.syn = t'.inh
5*8 =>
Annotierter Parse-Tree mit berechneten und geerbten Attributen (nur Multiplikation)
Vorgriff: Dies ist ein Beispiel für eine "L-attributierte SDD".
Beispiel: Typinferenz für 3+7+9 oder "hello"+"world"
Produktion
Semantische Regel
e : e1 '+' t ;
e.type = f(e1.type, t.type)
e : t ;
e.type = t.type
t : NUM ;
t.type = "int"
t : NAME ;
t.type = "string"
Syntax-gesteuerte Übersetzung (SDT)
Erweiterung attributierter Grammatiken
Syntax-directed translation scheme:
Zu den Attributen kommen Semantische Aktionen: Code-Fragmente als zusätzliche Knoten im Parse Tree an beliebigen Stellen in einer Produktion, die, wenn möglich, während des Parsens, ansonsten in weiteren Baumdurchläufen ausgeführt werden.
e : e1 {print e1.val;}
'+' {print "+";}
t {e.val = e1.val + t.val; print(e.val);}
;
Die Aktionen werden am Ende jeder Produktion eingefügt ("postfix SDT").
Produktion
Semantische Regel
e : e1 '+' t ;
e.val = e1.val + t.val
e : t ;
e.val = t.val
t : t1 '*' D ;
t.val = t1.val * D.lexval
t : D ;
t.val = D.lexval
e : e1 '+' t {e.val = e1.val + t.val; print(e.val);} ;
e : t {e.val = t.val;} ;
t : t1 '*' D {t.val = t1.val * D.lexval;} ;
t : D {t.val = D.lexval;} ;
[Levine2009] flex & bison Levine, J., O'Reilly, 2009. ISBN 978-0-5961-5597-1.
Lernziele
(K2) Konzept der attributierten Grammatiken: Anreicherung mit Attributen und semantischen Regeln
(K2) Unterschied zwischen geerbten und berechneten Attributen
(K2) Umsetzung von SDD mit Hilfe von SDT
(K3) Einfache semantische Analyse mit Hilfe von attributierten Grammatiken
SymbTab0: Überblick Symboltabellen
TL;DR
Auf die lexikalische Analyse und die Syntaxanalyse folgt die semantische Analyse. Nach dem
Parsen steht fest, dass ein Programm syntaktisch korrekt ist. Nun muss geprüft werden, ob
es auch semantisch korrekt ist. Dies umfasst in der Regel die Identifikation und Sammlung
von Bezeichnern und die Zuordnung zur richtigen Ebene (Scopes). Außerdem muss die Nutzung
von Symbolen validiert werden: Je nach Sprache müssen beispielsweise Variablen und Funktionen
vor ihrer Benutzung zumindest deklariert sein; Funktionen sollten sich nicht wie Variablen
benutzen lassen, ...
Als Werkzeug werden (hierarchische) Tabellen eingesetzt, um die verschiedenen Symbole und
Informationen darüber zu verwalten. Dabei werden die Symboltabelleneinträge oft an verschiedenen
Stellen im Compiler generiert und benutzt.
(K2) Bedeutung von Symboltabellen: Aufgaben, Verbindung zu Compiler-Phasen
Was passiert nach der Syntaxanalyse?
int x =42;
intf(int x) {
int y =9;
return y+x;
}
x =f(x);
Nach der Syntaxanalyse braucht der Compiler für die darauf folgenden Phasen
semantische Analyse, Optimierung und Codegenerierung Informationen
über Bezeichner, z.B.
Welcher Bezeichner ist gemeint?
Welchen Typ hat ein Bezeichner?
Auf dem Weg zum Interpreter/Compiler müssen die Symbole im AST korrekt zugeordnet
werden. Dies geschieht über Symboltabellen. Im Folgenden werden wir verschiedene
Aspekte von Symboltabellen betrachten und eine mögliche Implementierung erarbeiten,
bevor wir uns (in Interpreter)
um die Auswertung (Interpretation) des AST kümmern können.
Logische Compilierungsphasen
Die lexikalische Analyse generiert eine Folge von Token.
Die Syntaxanalyse generiert einen Parse Tree.
Die semantische Analyse macht folgendes:
Der Parse Tree wird in einen abstrakten Syntaxbaum (AST) umgewandelt.
Dieser wird häufig mit Attributen annotiert.
Dabei sind oft mehrere Baumdurchläufe nötig (z.B. wegen der Abhängigkeiten
der Attribute).
Nachfolgende Stufen:
Der AST wird in einen Zwischencode umgewandelt mit Registern und virtuellen
Adressen.
Der Zwischencode wird optimiert.
Aus dem optimierten Zwischencode wird der endgültige Code, aber immer noch
mit virtuellen Adressen, generiert.
Der generierte Code wird nachoptimiert.
Der Linker ersetzt die virtuellen Adressen durch reale Adressen.
Abgrenzung der Phasen
Diese Phasen sind oft nicht klar unterscheidbar. Schon allein zur Verbesserung der
Laufzeit baut der Parser oft schon den abstrakten Syntaxbaum auf, der Lexer trägt schon
Bezeichner in Symboltabellen ein, der Parser berechnet beim Baumaufbau schon Attribute,
...
Oft werden gar nicht alle Phasen und alle Zwischendarstellungen benötigt.
Semantische Analyse und Symboltabellen
Syntax und Semantik
Syntaxregeln: Formaler Aufbau eines Programms
Semantik: Bedeutung eines (syntaktisch korrekten) Programms
=> Keine Codegenerierung für syntaktisch/semantisch inkorrekte Programme!
Zur Erinnerung: Die Syntaxregeln einer Programmiersprache bestimmen den formalen
Aufbau eines zu übersetzenden Programms. Die Semantik gibt die Bedeutung eines
syntaktisch richtigen Programms an.
Lexikalische und syntaktische Analyse können formalisiert mit regulären Ausdrücken und
endlichen Automaten, sowie mit CFG und Parsern durchgeführt werden.
Die Durchführung der semantischen Analyse ist stark von den Eigenschaften der zu
übersetzenden Sprache, sowie der Zielsprache abhängig und kann hier nur beispielhaft
für einige Eigenschaften erklärt werden.
Es darf kein lauffähiges Programm erstellt werden können, dass nicht syntaktisch und
semantisch korrekt ist. Ein lauffähiges Programm muss syntaktisch und semantisch korrekt
sein!
Aufgaben der semantischen Analyse
Identifikation und Sammlung der Bezeichner
Zuordnung zur richtigen Ebene (Scopes)
Typ-Inferenz
Typkonsistenz (Ausdrücke, Funktionsaufrufe, ...)
Validieren der Nutzung von Symbolen
Vermeidung von Mehrfachdefinition
Zugriff auf nicht definierte Bezeichner
(Lesender) Zugriff auf nicht initialisierte Bezeichner
Funktionen werden nicht als Variablen genutzt
...
Die semantische Analyse überprüft die Gültigkeit eines syntaktisch korrekten Programms
bzgl. statischer semantischer Eigenschaften und liefert die Grundlage für die (Zwischen-)
Codeerzeugung und -optimierung. Insbesondere wird hier die Typkonsistenz (in Ausdrücken,
von Parametern, ...) überprüft, und implizite Typumwandlungen werden vorgenommen. Oft
müssen Typen automatisch bestimmt werden (z.B. bei Polymorphie, Typinferenz). Damit
Typen bestimmt oder angepasst werden können, müssen Bezeichner zunächst identifiziert
werden, d.h. bei namensgleichen Bezeichnern der richtige Bezug bestimmt werden.
=> Ein wichtiges Hilfsmittel dazu sind Symboltabellen
Identifizierung von Objekten
Beim Compiliervorgang müssen Namen immer wieder den dazugehörigen Definitionen
zugeordnet, ihre Eigenschaften gesammelt und geprüft und darauf zugegriffen werden.
Symboltabellen werden im Compiler fast überall gebraucht (siehe Abbildung unter
"Einordnung").
Welche Informationen zu einem Bezeichner gespeichert und ermittelt werden, ist dann
abhängig von der Klasse des Bezeichners.
Validieren der Nutzung von Symbolen
Hier sind unendlich viele Möglichkeiten denkbar. Dies reicht von den unten aufgeführten
Basisprüfungen bis hin zum Prüfen der Typkompatibilität bei arithmetischen Operationen.
Dabei müssen für alle Ausdrücke die Ergebnistypen berechnet werden und ggf. automatische
Konvertierungen vorgenommen werden, etwa bei 3+4.1 ...
Zugriff auf Variablen: Müssen sichtbar sein
Zugriff auf Funktionen: Vorwärtsreferenzen sind OK
Da Funktionen bereits vor dem Bekanntmachen der Definition aufgerufen werden dürfen, bietet
sich ein zweimaliger Durchlauf (pass) an: Beim ersten Traversieren des AST werden alle
Definitionen in der Symboltabelle gesammelt. Beim zweiten Durchlauf werden dann die Referenzen
aufgelöst.
Das Mittel der Wahl: Tabellen für die Symbole (= Bezeichner)
Def.:Symboltabellen sind die zentrale Datenstruktur zur Identifizierung und
Verwaltung von bezeichneten Elementen.
Die Organisation der Symboltabellen ist stark anwendungsabhängig. Je nach Sprachkonzept
gibt es eine oder mehrere Symboltabellen, deren Einträge vom Lexer oder Parser angelegt
werden. Die jeweiligen Inhalte jedes einzelnen Eintrags kommen aus den verschiedenen
Phasen der Compilierung. Symboltabellen werden oft als Hashtables oder auch als Bäume
implementiert, manchmal als verkettete Listen. In seltenen Fällen kommt man auch mit
einem Stack aus.
Eine Symboltabelle enthält benutzerdefinierte Bezeichner (oder Verweise in eine Hashtable
mit allen vorkommenden Namen), manchmal auch die Schlüsselwörter der Programmiersprache.
Die einzelnen Felder eines Eintrags variieren stark, abhängig vom Typ des Bezeichners
(= Bezeichnerklasse).
Manchmal gibt es für Datentypen eine Extra-Tabelle, ebenso eine für die Werte von Konstanten.
Manchmal werden die Namen selbst in eine (Hash-) Tabelle geschrieben. Die Symboltabelle
enthält dann statt der Namen Verweise in diese (Hash-) Tabelle.
Einfache Verwaltung von Variablen primitiven Typs
int x =0;
int i =0;
for (i=0; i<10; i++) {
x++;
}
Bsp.: Die zu übersetzende Sprache hat nur einen (den globalen) Scope und kennt nur
Bezeichner für Variablen.
Eine Symboltabelle für alle Bezeichner
Jeder Bezeichner ist der Name einer Variablen
Symboltabelle wird evtl. mit Einträgen aller Schlüsselwörter initialisiert -- warum?
Scanner erkennt Bezeichner und sucht ihn in der Symboltabelle
Ist der Bezeichner nicht vorhanden, wird ein (bis auf den Namen leerer) Eintrag angelegt
Scanner übergibt dem Parser das erkannte Token und einen Verweis auf den
Symboltabelleneintrag
Die Symboltabelle könnte hier eine (Hash-) Tabelle oder eine einfache verkettete Liste sein.
Was kann jetzt weiter passieren?
int x =0;
int i =0;
for (i=0; i<10; i++) {
x++;
}
a =42;
In vielen Sprachen muss überprüft werden, ob es ein definierendes Vorkommen des Bezeichners oder
ein angewandtes Vorkommen ist.
Definitionen und Deklarationen von Bezeichnern
Def.: Die Definition eines (bisher nicht existenten) Bezeichners in einem Programm
generiert einen neuen Bezeichner und legt für ihn seinem Typ entsprechend Speicherplatz an.
Def.: Unter der Deklaration eines (bereits existierenden) Bezeichners verstehen wir
seine Bekanntmachung, damit er benutzt werden kann. Er ist oft in einem anderen Scope
definiert und bekommt dort Speicherplatz zugeteilt.
Insbesondere werden auch Typen deklariert. Hier gibt es in der Regel gar keine
Speicherplatzzuweisung.
Ein Bezeichner kann beliebig oft deklariert werden, während er in einem Programm nur einmal
definiert werden kann. Oft wird bei der Deklarationen eines Elements sein Namensraum mit
angegeben.
Vorsicht: Die Begriffe werden auch anders verwendet. Z.B. findet sich in der
Java-Literatur der Begriff Deklaration anstelle von Definition.
Anmerkung:
Deklarationen beziehen sich auf Definitionen, die woanders in einer Symboltabelle stehen, evtl.
in einer anderen Datei, also in diesem Compilerlauf nicht zugänglich sind und erst von Linker
aufgelöst werden können. Beim Auftreten einer Deklaration muss die dazugehörige Definition gesucht
werden,und wenn vorhanden, im Symboltabelleneintrag für den deklarierten Bezeichner festgehalten
werden. Hier ist evtl. ein zweiter Baumdurchlauf nötig, um alle offenen Deklarationen, die sich
auf Definitionen in derselben Datei beziehen, aufzulösen.
Wird bei objektorientierten Sprachen ein Objekt definiert, dessen Klassendefinition in einer anderen
Datei liegt, kann man die Definition des Objekts gleichzeitig als Deklaration der Klasse auffassen
(Java).
Wo werden Verweise in Symboltabellen gebraucht?
=> Parse Tree und AST enthalten Verweise auf Symboltabelleneinträge
Im Parse Tree enthält der Knoten für einen Bezeichner einen Verweis auf den
Symboltabelleneintrag.
Parser und semantische Analyse (AST) vervollständigen die Einträge.
Attribute des AST können Feldern der Symboltabelle entsprechen, bzw. sich aus
ihnen berechnen.
Für Debugging-Zwecke können die Symboltabellen die ganze Compilierung und das
Linken überleben.
Grenzen der semantischen Analyse
Welche semantischen Eigenschaften einer Sprache kann die semantische Analyse nicht überprüfen?
Wer ist dann dafür verantwortlich?
Wie äußert sich das im Fehlerfall?
Dinge, die erst durch eine Ausführung/Interpretation eines Programms berechnet werden können.
Beispielsweise können Werte von Ausdrücken oft erst zur Laufzeit bestimmt werden. Insbesondere
kann die semantische Analyse in der Regel nicht feststellen, ob ein Null-Pointer übergeben wird
und anschließend dereferenziert wird.
Wrap-Up
Semantische Analyse:
Identifikation und Sammlung der Bezeichner
Zuordnung zur richtigen Ebene (Scopes)
Validieren der Nutzung von Symbolen
Typ-Inferenz
Typkonsistenz (Ausdrücke, Funktionsaufrufe, ...)
Symboltabellen: Verwaltung von Symbolen und Typen (Informationen über Bezeichner)
Symboltabelleneinträge werden an verschiedenen Stellen des Compilers generiert und benutzt
In Symboltabellen werden Informationen über Bezeichner verwaltet. Wenn es in der zu
übersetzenden Sprache Nested Scopes gibt, spiegelt sich dies in den Symboltabellen
wider: Auch hier wird eine entsprechende hierarchische Organisation notwendig. In der
Regel nutzt man Tabellen, die untereinander verlinkt sind.
Eine wichtige Aufgabe ist das Binden von Bezeichner gleichen Namens an ihren jeweiligen
Scope => bind(). Zusätzlich müssen Symboltabellen auch das Abrufen von Bezeichnern
aus dem aktuellen Scope oder den Elternscopes unterstützen => resolve().
(K3) Aufbau von Symboltabellen für Nested Scopes inkl. Strukturen/Klassen mit einem Listener
(K3) Auflösen von Symbolen über die Scopes
(K3) Einfache statische Prüfungen anhand der Symboltabellen
Scopes und Name Spaces
Def.: Unter dem Gültigkeitsbereich (Sichtbarkeitsbereich, Scope) eines
Bezeichners versteht man den Programmabschnitt, in dem der Bezeichner sichtbar
und nutzbar ist. Das ist oft der kleinste umgebende Block, außer darin enthaltene
Scopes, die ein eigenes Element dieses Namens benutzen.
Scopes sind fast immer hierarchisch angeordnet.
Def.: Unter einem Namensraum (name space) versteht man die Menge der zu
einem Zeitpunkt sichtbaren Bezeichner.
Es gibt Sprachen, in denen man eigene Namensräume explizit definieren kann (z.B.
C++).
Vorsicht: Diese Begriffe werden nicht immer gleich definiert und auch gerne
verwechselt.
Symbole und (nested) Scopes
int x =42;
float y;
{
int x;
x =1;
y =2;
{ int y = x; }
}
Aufgaben:
bind(): Symbole im Scope definieren
resolve(): Symbole aus Scope oder Eltern-Scope abrufen
Hinzunahme von Scopes
Bsp.: Die zu übersetzende Sprache ist scope-basiert und kennt nur Bezeichner
für Variablen
Scopes können ineinander verschachtelt sein. Die Spezifikation der zu übersetzenden
Sprache legt fest, in welcher Reihenfolge Scopes zu durchsuchen sind, wenn auf einen
Bezeichner Bezug genommen wird, der nicht im aktuellen Scope definiert ist.
Insgesamt bilden die Scopes oft eine Baumstruktur, wobei jeder Knoten einen Scope
repräsentiert und seine Kinder die direkt in ihm enthaltenen Scopes sind. Dabei ist
es in der Regel so, dass Scopes sich entweder vollständig überlappen oder gar nicht.
Wenn ein Bezeichner nicht im aktuellen Scope vorhanden ist, muss er in der Regel in
umschließenden Scopes gesucht werden. Hier kann ein Stack aller "offenen" Scopes
benutzt werden.
Grundlegendes Vorgehen
Das Element, das einen neuen Scope definiert, steht selbst in dem aktuell
behandelten Scope. Wenn dieses Element selbst ein Bezeichner ist, gehört
dieser in den aktuellen Scope. Nur das, was nur innerhalb des oben genannten
Elements oder Bezeichners definiert wird, gehört in den Scope des Elements
oder Bezeichners.
Nested Scopes: Symbole und Scopes
Implementierung mit hierarchischen (verketteten) Tabellen
Pro Scope wird eine Symboltabelle angelegt, dabei enthält jede Symboltabelle zusätzlich
einen Verweis auf ihre Vorgängersymboltabelle für den umgebenden Scope. Die globale
Symboltabelle wird typischerweise mit allen Schlüsselwörtern initialisiert.
Wenn ein neuer Scope betreten wird, wird eine neue Symboltabelle erzeugt.
Scanner: Erkennt Bezeichner und sucht ihn in der Symboltabelle des aktuellen
Scopes bzw. trägt ihn dort ein und übergibt dem Parser das erkannte Token und
einen Verweis auf den Symboltabelleneintrag (Erinnerung: Der Scanner wird
i.d.R. vom Parser aus aufgerufen, d.h. der Parser setzt den aktuellen Scope!)
Parser:
Wird ein neues Element (ein Bezeichner) definiert, muss bestimmt werden, ob
es einen eigenen Scope hat. Wenn ja, wird eine neue Symboltabelle für den
Scope angelegt. Sie enthält alle Definitionen von Elementen, die in diesem
Scope liegen. Der Bezeichner selbst wird in die aktuelle Symboltabelle eingetragen
mit einem Verweis auf die neue Tabelle, die all die Bezeichner beinhaltet, die
außerhalb dieses Scopes nicht sichtbar sein sollen. Die Tabellen werden untereinander
verzeigert.
Wird ein Element deklariert oder benutzt, muss sein Eintrag in allen sichtbaren
Scopes in der richtigen Reihenfolge entlang der Verzeigerung gesucht (und je nach
Sprachdefinition auch gefunden) werden.
Der Parse-Tree enthält im Knoten für den Bezeichner den Verweis in die Symboltabelle
Klassenhierarchie für Scopes
Für die Scopes wird eine Klasse Scope definiert mit den Methoden bind() (zum
Definieren von Symbolen im Scope) und resolve() (zum Abrufen von Symbolen aus
dem Scope oder dem umgebenden Scope).
Für lokale Scopes wird eine Instanz dieser Klasse angelegt, die eine Referenz auf
den einschließenden Scope im Attribut enclosingScope hält. Für den globalen Scope
ist diese Referenz einfach leer (None).
Klassen und Interfaces für Symbole
Für die Symbole gibt es die Klasse Symbol, wo für jedes Symbol Name und Typ gespeichert
wird. Variablensymbole leiten direkt von dieser Klasse ab. Für die eingebauten Typen wird
ein "Marker-Interface" Type erstellt, um Variablen- und Typ-Symbole unterscheiden zu
können.
Der Parse Tree bzw. der AST enthalten an den Knoten, die jeweils einen ganzen
Scope repräsentieren, einen Verweis auf die Symboltabelle dieses Scopes.
Die Scopes werden in einem Stack verwaltet.
Wird ein Scope betreten beim Baumdurchlauf, wird ein Verweis auf seine
Symboltabelle auf den Stack gepackt.
Die Suche von Bezeichnern in umliegenden Scopes erfordert ein Durchsuchen
des Stacks von oben nach unten.
Beim Verlassen eines Scopes beim Baumdurchlauf wird der Scope vom Stack entfernt.
Nested Scopes: Definieren und Auflösen von Namen
classScope:
Scope enclosingScope # None if global (outermost) scope Symbol<String, Symbol> symbols
defresolve(name):
# do we know "name" here?if symbols[name]: return symbols[name]
# if not here, check any enclosing scopeif enclosingScope: return enclosingScope.resolve(name)
else: returnNone# not founddefbind(symbol):
symbols[symbol.name] = symbol
symbol.scope = self # track the scope in each symbol
Anmerkung: In der Klasse Symbol kann man ein Feld scope vom Typ Scope
implementieren. Damit "weiss" jedes Symbol, in welchem Scope es definiert ist und
man muss sich auf der Suche nach dem Scope eines Symbols ggf. nicht erst durch
die Baumstruktur hangeln. Aus technischer Sicht verhindert das Attribut das
Aufräumen eines lokalen Scopes durch den Garbage Collector, wenn man den lokalen
Scope wieder verlässt: Jeder Scope hat eine Referenz auf den umgebenden (Eltern-)
Scope (Feld enclosingScope). Wenn man den aktuellen Scope "nach oben" verlässt,
würde der eben verlassene lokale Scope bei nächster Gelegenheit aufgeräumt, wenn
es keine weiteren Referenzen auf diesen gäbe. Da nun aber die Symbole, die in
diesem Scope definiert wurden, auf diesen verweisen, passiert das nicht :)
Nested Scopes: Listener
Mit einem passenden Listener kann man damit die nötigen Scopes aufbauen:
enterStart:
erzeuge neuen globalen Scope
definiere und pushe die eingebauten Typen
exitVarDecl:
löse den Typ der Variablen im aktuellen Scope auf
definiere ein neues Variablensymbol im aktuellen Scope
exitVar:
löse die Variable im aktuellen Scope auf
enterBlock:
erzeuge neuen lokalen Scope, wobei der aktuelle Scope der Elternscope ist
ersetze den aktuellen Scope durch den lokalen Scope
exitBlock:
ersetze den aktuellen Scope durch dessen Elternscope
start : stat+ ;
stat : block | varDecl | expr ';' ;
block : '{' stat* '}' ;
varDecl : type ID ('=' expr)? ';' ;
expr : var '=' INT ;
var : ID ;
type : 'float' | 'int' ;
Relevanter Ausschnitt aus der Grammatik
int x =42;
{ int y =9; x =7; }
classMyListener(BaseListener):
Scope scope
defenterStart(Parser.FileContext ctx):
globals = Scope()
globals.bind(BuiltIn("int"))
globals.bind(BuiltIn("float"))
scope = globals
defenterBlock(Parser.BlockContext ctx):
scope = Scope(scope)
defexitBlock(Parser.BlockContext ctx):
scope = scope.enclosingScope
defexitVarDecl(Parser.VarDeclContext ctx):
t = scope.resolve(ctx.type().getText())
var = Variable(ctx.ID().getText(), t)
scope.bind(var)
defexitVar(Parser.VarContext ctx):
name = ctx.ID().getText()
var = scope.resolve(name)
if var ==None: error("no such var: "+ name)
Anmerkung: Um den Code auf die Folie zu bekommen, ist dies ein Mix aus Java und Python geworden. Sry ;)
In der Methode exitVar() wird das Variablensymbol beim Ablaufen des AST
lediglich aufgelöst und ein Fehler geworfen, wenn das Variablensymbol (noch)
nicht bekannt ist. Hier könnte man weiteres Type-Checking und/oder -Propagation
ansetzen.
Später im Interpreter muss an dieser Stelle dann aber auch der Wert der
Variablen abgerufen werden ...
Löschen von Symboltabellen
Möglicherweise sind die Symboltabellen nach der Identifizierungsphase der Elemente
überflüssig, weil die zusammengetragenen Informationen als Attribute im AST stehen.
Die Knoten enthalten dann Verweise auf definierende Knoten von Elementen, nicht mehr
auf Einträge in den Symboltabellen. In diesem Fall können die Symboltabellen nach der
Identifizierung gelöscht werden, wenn sie nicht z.B. für einen symbolischen Debugger
noch gebraucht werden.
Wrap-Up
Symboltabellen: Verwaltung von Symbolen und Typen (Informationen über Bezeichner)
Eine Funktion sind selbst ein Symbol, welches in einem Scope gilt und entsprechend
in der Symboltabelle eingetragen wird. Darüber hinaus bildet sie einen neuen
verschachtelten Scope, in dem die Funktionsparameter und der Funktionskörper definiert
werden müssen.
Entsprechend müssen die Strukturen für die Symboltabellen sowie das Eintragen und das
Auflösen von Symbolen erweitert werden.
(K3) Aufbau von Symboltabellen für Nested Scopes inkl. Strukturen/Klassen mit einem Listener
(K3) Attribute von Klassen und Strukturen auflösen
Funktionen und Scopes
int x =42;
int y;
voidf() {
int x;
x =1;
y =2;
{ int y = x; }
}
voidg(int z){}
Behandlung von Funktionsdefinitionen
Jeder Symboltabelleneintrag braucht ein Feld, das angibt, ob es sich um eine
Variable, eine Funktion, ... handelt. Alternativ eine eigene Klasse ableiten ...
Der Name der Funktion steht als Bezeichner in der Symboltabelle des Scopes, in dem
die Funktion definiert wird.
Der Symboltabelleneintrag für den Funktionsnamen enthält Verweise auf die Parameter.
Der Symboltabelleneintrag für den Funktionsnamen enthält Angaben über den Rückgabetypen.
Jede Funktion wird grundsätzlich wie ein neuer Scope behandelt.
Die formalen Parameter werden als Einträge in der Symboltabelle für den Scope der
Funktion angelegt and entsprechend als Parameter gekennzeichnet.
Behandlung von Funktionsaufrufen
Der Name der Funktion steht als Bezeichner in der Symboltabelle des Scopes, in dem
die Funktion aufgerufen wird und wird als Aufruf gekennzeichnet.
Der Symboltabelleneintrag für den Funktionsnamen enthält Verweise auf die aktuellen
Parameter.
Die Definition der Funktion wird in den zugänglichen Scopes gesucht (wie oben) und
ein Verweis darauf in der Symboltabelle gespeichert.
Erweiterung des Klassendiagramms für Funktions-Scopes
classFunction(Scope, Symbol):
def __init__(name, retType, enclScope):
Symbol.__init__(name, retType) # we are "Symbol" ... enclosingScope = enclScope # ... and "Scope"
Funktionen: Listener
Den Listener zum Aufbau der Scopes könnte man entsprechend erweitern:
enterFuncDecl:
löse den Typ der Funktion im aktuellen Scope auf
lege neues Funktionssymbol an, wobei der aktuelle Scope der Elternscope ist
definiere das Funktionssymbol im aktuellen Scope
ersetze den aktuellen Scope durch das Funktionssymbol
exitFuncDecl:
ersetze den aktuellen Scope durch dessen Elternscope
exitParam: analog zu exitVarDecl
löse den Typ der Variablen im aktuellen Scope auf
definiere ein neues Variablensymbol im aktuellen Scope
exitCall: analog zu exitVar
löse das Funktionssymbol (und die Argumente) im aktuellen Scope auf
funcDecl : type ID '(' params? ')' block ;
params : param (',' param)* ;
param : type ID ;
call : ID '(' exprList? ')' ;
exprList : expr (',' expr)* ;
Relevanter Ausschnitt aus der Grammatik
intf(int x) {
int y =9;
}
int x =f(x);
defenterFuncDecl(Parser.FuncDeclContext ctx):
name = ctx.ID().getText()
type = scope.resolve(ctx.type().getText())
func = Function(name, type, scope)
scope.bind(func)
# change current scope to function scope scope = func
defexitFuncDecl(Parser.FuncDeclContext ctx):
scope = scope.enclosingScope
defexitParam(Parser.ParamContext ctx):
t = scope.resolve(ctx.type().getText())
var = Variable(ctx.ID().getText(), t)
scope.bind(var)
defexitCall(Parser.CallContext ctx):
name = ctx.ID().getText()
func = scope.resolve(name)
if func ==None:
error("no such function: "+ name)
if func.type == Variable:
error(name +" is not a function")
Anmerkung: Um den Code auf die Folie zu bekommen, ist dies wieder ein Mix aus Java und Python geworden. Sry ;)
Im Vergleich zu den einfachen nested scopes kommt hier nur ein weiterer
Scope für den Funktionskopf dazu. Dieser spielt eine Doppelrolle: Er ist
sowohl ein Symbol (welches im Elternscope bekannt ist) als auch ein eigener
(lokaler) Scope für die Funktionsparameter.
Um später im Interpreter eine Funktion tatsächlich auswerten zu können, muss
im Scope der Funktion zusätzlich der AST-Knoten der Funktionsdefinition
gespeichert werden (weiteres Feld/Attribut in Function)!
Wrap-Up
Symboltabellen: Verwaltung von Symbolen und Typen (Informationen über Bezeichner)
Strukturen und Klassen bilden jeweils einen eigenen verschachtelten Scope, worin
die Attribute und Methoden definiert werden.
Bei der Namensauflösung muss man dies beachten und darf beim Zugriff auf Attribute
und Methoden nicht einfach in den übergeordneten Scope schauen. Zusätzlich müssen
hier Vererbungshierarchien in der Struktur der Symboltabelle berücksichtigt werden.
=> Auflösen von "a.b" (im Listener in exitMember()):
a im "normalen" Modus mit resolve() über den aktuellen Scope
Typ von a ist Struct mit Verweis auf den eigenen Scope
b nur innerhalb des Struct-Scopes mit resolveMember()
In der Grammatik würde es eine Regel member geben, die auf eine Struktur
der Art ID.ID anspricht (d.h. eigentlich den Teil .ID), und entsprechend
zu Methoden enterMember() und exitMember() im Listener führt.
Das Symbol für a hat als type-Attribut eine Referenz auf die Struct,
die ja einen eigenen Scope hat (symbols-Map). Darin muss dann b aufgelöst
werden.
Klassen
classA {
public:int x;
voidfoo() { ; }
};
classB:public A {
publicint y;
voidfoo() {
int z = x+y;
}
};
Bei Klassen kommt in den Tabellen ein weiterer Pointer parentClazz auf die
Elternklasse hinzu (in der Superklasse ist der Wert None).
Klassen: Auflösen von Namen
classClazz(Struct):
Clazz parentClazz # None if base classdefresolve(name):
# do we know "name" here?if symbols[name]: return symbols[name]
# NEW: if not here, check any parent class ...if parentClazz and parentClazz.resolve(name): return parentClazz.resolve(name)
else:
# ... or enclosing scope if base classif enclosingScope: return enclosingScope.resolve(name)
else: returnNone# not founddefresolveMember(name):
if symbols[name]: return symbols[name]
# NEW: check parent classif parentClazz: return parentClazz.resolveMember(name)
else: returnNone
Hinweis: Die obige Implementierungsskizze soll vor allem das Prinzip demonstrieren - sie ist aus
Gründen der Lesbarkeit nicht besonders effizient: beispielsweise wird parentClazz.resolve(name)
mehrfach evaluiert ...
Beim Auflösen von Attributen oder Methoden muss zunächst in der Klasse selbst gesucht werden,
anschließend in der Elternklasse.
Beispiel (mit den obigen Klassen A und B):
B foo;
foo.x =42;
Hier wird analog zu den Structs zuerst foo mit resolve() im lokalen Scope aufgelöst. Der Typ
des Symbols foo ist ein Clazz, was zugleich ein Scope ist. In diesem Scope wird nun mit
resolveMember() nach dem Symbol x gesucht. Falls es hier nicht gefunden werden kann, wird in
der Elternklasse (sofern vorhanden) weiter mitresolveMember() gesucht.
Die normale Namensauflösung wird ebenfalls erweitert um die Auflösung in der Elternklasse.
Beispiel:
int wuppie;
classA {
public:int x;
voidfoo() { ; }
};
classB:public A {
publicint y;
voidfoo() {
int z = x+y+wuppie;
}
};
Hier würde wuppie als Symbol im globalen Scope definiert werden. Beim Verarbeiten von
int z = x+y+wuppie; würde mit resolve() nach wuppie gesucht: Zuerst im lokalen Scope
unterhalb der Funktion, dann im Funktions-Scope, dann im Klassen-Scope von B. Hier sucht
resolve() auch zunächst lokal, geht dann aber die Vererbungshierarchie entlang (sofern
wie hier vorhanden). Erst in der Superklasse (wenn der parentClazz-Zeiger None ist),
löst resolve() wieder normal auf und sucht um umgebenden Scope. Auf diese Weise kann man
wie gezeigt in Klassen (Methoden) auf globale Variablen verweisen ...
Anmerkung: Durch dieses Vorgehen wird im Prinzip in Methoden aus dem Zugriff auf ein Feld
x implizit ein this.x aufgelöst, wobei this die Klasse auflöst und x als Attribut darin.
Wrap-Up
Symboltabellen: Verwaltung von Symbolen und Typen (Informationen über Bezeichner)
Strukturen und Klassen bilden eigenen Scope
Strukturen/Klassen lösen etwas anders auf: Zugriff auf Attribute und Methoden
Challenges
Symboltabellen praktisch
Betrachten Sie folgenden Java-Code:
Umkreisen Sie alle Symbole.
Zeichen Sie Pfeile von Symbol-Referenzen zur jeweiligen Definition (falls vorhanden).
Identifizieren Sie alle benannten Scopes.
Identifizieren Sie alle anonymen Scopes.
Geben Sie die resultierende Symboltabelle an (Strukturen wie in VL besprochen).
package a.b;
import u.Y;
classXextends Y {
intf(int x) {
int x,y;
{ int x; x - y + 1; }
x = y + 1;
}
}
classZ {
classWextends X {
int x;
voidfoo() { f(34); }
}
int x,z;
intf(int x) {
int y;
y = x;
z = x;
}
}